Products
Solutions
Resources
Build vs Buy
You are here because you subscribe to product experimentation as a philosophy. We do too! And we want to help you make the right call on one of the most important decisions you’ll make for your product.
Companies like Bing, Google, and LinkedIn increased the number of product experiments they ran by an order of magnitude after they built an experimentation platform. Today, these companies run tens of thousands of experiments every year. While these large technology companies have dedicated teams that build and maintain their own experimentation platforms, you must decide whether to build or buy based on the context of your business. Here are two key questions to help you decide what works for you:
- What would it cost to build your own platform?
- What can an external platform deliver?
Building Your Own
The goal of an experimentation platform is to enable fast product iteration based on data driven metrics. Ideally it should be self-serve so as to enable your teams to make ship decisions without relying on a central committee; and in the process, minimize the costs of running experiments.
Building such an experimentation platform will draw investment in three key areas:
- Reliable core infrastructure to control and execute experiments
- An analysis framework to make sense of the data and thereby product decisions
- A set of software development kits (SDKs) and tools to integrate with the company’s existing software development and decision-making processes
Core Infrastructure
The core infrastructure is the foundation of the experimentation platform. It should be reliable, always available and must be fast. You won’t want your experimentation platform to introduce any variance, or worse, negatively affect the product’s experience.
The core infrastructure usually comprises of the four key components:
-
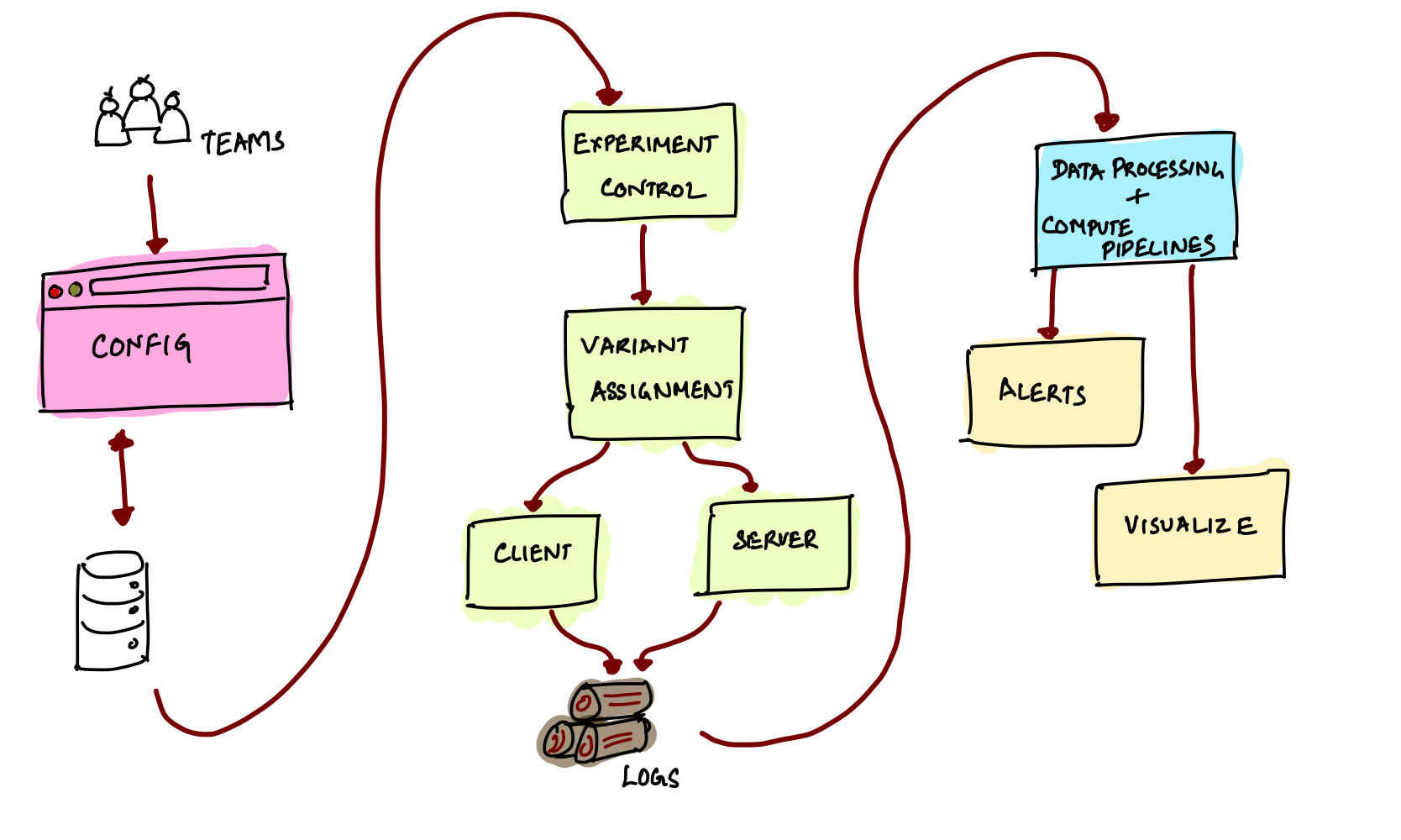
Experiment Control
This component persists and validates the specifications for each experiment including any subsequent iterations. For example, each experiment specifies several parameters such as start and end dates, control and variants, target users, sample sizes, and related configuration. This component also enforces approval workflows as well as roles and permissions to ensure that only approved experiments are allowed to run, and only authorized team members can start and stop an experiment.
-
Variant Assignment
Given a user request, this component decides how to assign the request to a variant in an experiment. This assignment is based on the experiment specification and a pseudo-random hash of an identifier. Important considerations for this component include:
- Ensuring random but deterministic assignment of users to control and variant buckets (you don’t want your users to switch between experiences
- Assigning users across multiple concurrent experiments while ensuring a consistent experience, and when needed, keep experiments isolated, so that one user is not simultaneously in multiple conflicting experiments.
- delivering assignments without incurring additional latency or hurting application availability.
-
Data Processing
Delivering reliable and automated data processing is critical to establish organizational trust in experiment results. To get data into a reliable state, you would need to consolidate, sort, and join the logs from different sources, and then cleanse and enrich these logs where necessary. The next step is computing all the metrics for various segments and user dimensions, followed by p-values and confidence intervals.
This part is critical, and you would want to run a series of A/A tests to ensure correctness of the Finally, we must run basic health checks to ensure correctness.
-
Experiment Analysis
Any good experimentation platform should enable every person in the team to easily read and interpret their experiment results. This is where the rubber hits the road; this is what separates a valuable platform from one that’ll be discarded quickly. Results should be clear and concise, highlighting the relative change in metrics along with clear signals about statistical significance. Time and again we’ve seen platforms that don’t even bother providing confidence intervals which are at best amusing, and at worst misleading and damaging to your product.
In addition, if you care about a holistic impact of experiments, the platform should reveal all relevant metrics, not just the one that the experiment was tailored for. Results should enable slicing across user dimensions and segments and using lower p-values to filter for the most significant metrics. The team should also be able to see per metric views of all experiment results to see which experiments are most impactful.
APIs and SDKs
And finally, all of the experiment configurations would need to reach your applications, and this is done via APIs and SDKs. The most common considerations here include (a) support for different points of production decisioning which could be on the client side or server-side, and (b) support for all languages that various teams may choose for their respective functional goals.
In addition, you would want your SDKs to be resilient to network flakiness, and the API versioning should be carefully considered with existing SDK usage.
Architecture
The diagram below captures the high-level architecture of a simple experimentation platform.
Buying/Renting
If you’re looking beyond building your own experimentation platform, here are some considerations for choosing to use an external service:
-
Core Functionality Does the service deliver the functionality you need for your application? For example, is the service optimized for front-end or back-end experimentation? Does it work for both web and mobile applications? For example, the nice drag-and-drop editor may work well for the web interfaces but does the mobile SDK crash a lot?
-
SDK Support Does the service support the SDK in the language you need?
-
Performance Do SDK calls slow down the application?
-
Data Ingestion Can the service ingest data from different sources to avoid logging data with multiple services and to join the data for a richer analysis?
-
Near Real-time Results Do you need near-real time results to quickly detect and stop bad experiments?
-
Randomization Unit Does the service allow randomization units such as sessions or workspaces in addition to users?
-
Metrics Does the service compute all the metrics required to make a sound decision? Do these computed metrics reconcile with other sources in the company?
-
Health & Audit Does the service automatically surface health and system metrics to pro-actively identify issues? Does the Does the service provide approval workflows to implement team reviews? Does it provide an audit log of changes?
-
Access Control Does the service allow you to control who has permissions to start and stop experiments?
Building vs. Buying
To set yourself up for success, estimate how many experiments your organization would run assuming everyone in the company truly embraces experimentation. As the number of experiments scales, the experimentation infrastructure can become increasingly complex to manage and support. To decide between building vs. buying, consider the total cost of ownership (TCO) and the opportunity cost of building an experimentation platform in-house. Compare this against your functional needs, reliability, scalability, and costs of using an external service.
Total Cost of Ownership
To estimate the TCO for an in-house platform, consider the costs for:
-
Development Building an in-house platform requires top-notch infrastructure engineers to build the core infrastructure that offers both high availability and high performance. It also requires dedicated data scientists and data engineers to ensure that data processing, computations, and results are reliable and trustworthy.
-
Operations & Support To provide uptime SLAs, this team needs to devote a part of its time to on-call rotation. This team also needs to support inquiries and support tickets from all users in the company.
-
Infrastructure The core infrastructure must be redundant and resilient with automated scaling built-in to deliver a stable and trusted service. Be sure to include essential monitoring and operational tooling to estimate your infrastructure operating costs. If you require near-real time results, the complexity and cost of this infrastructure can increase further.
-
SDKs for Everyone Each team running experiments requires client and/or server SDKs in their own preferred language. As a result, the platform team needs to include engineers familiar with the nuances of these languages to build and support the required SDKs over time.
Opportunity Cost
Building an in-house platform comes at the expense of engineers and dollars that you could invest in your core product and functionality that your users want. A good experimentation platform is a powerhouse that accelerates your pace of innovation. If it slows down your client teams, they won’t use it and your initial investment may turn out to be a waste. If you do decide to build your own, you must invest in the team, infrastructure, and SDKs to stay ahead of the needs of all client teams in your organization.
As a point of comparison, assuming an external service meets your functional requirements, buying may offer a faster pace of innovation than an in-house platform. The external service is usually committed to innovating on behalf of all their customers and setting the industry standard for common requirements such as scalability, performance, security, and governance. This means you enjoy the leading pace of innovation in experimentation by default.
There are some cases where building could still be better than buying if external services don’t meet your functional requirements. For example, if you run software deeply integrated with hardware, such as Roku, you may want a unique or customized way to deploy and control your experiments.
Summary
To conclude, an external service can help you focus on driving the car rather than assembling all the parts of an experimentation platform. To enjoy the most flexibility, consider a service with a free tier and easy onboarding to see the value of simple A/B tests without committing to any contracts. Get your hands on something that works on day one, and most importantly provides transparent pricing so you only get what you need.