Products
Solutions
Resources

How do you reduce your cloud compute costs without using a third-party vendor?
Anyone who has optimized cloud compute costs knows that spot nodes can significantly reduce your bill.
However, spot pricing isn't always intuitive: better hardware isn't necessarily more expensive and pricing fluctuates significantly across regions.
While some SaaS companies offer automated optimization of spot node selection, these services typically have notable drawbacks:
Loss of Control: You're entrusting third-party providers with your node management, which could risk disrupting your workflows with opaque algorithms
Cost: These services can significantly add to your operational expenses
Even manually selecting the cheapest nodes doesn't fully resolve the issue because spot prices continually change. Also, pricing varies across multiple regions, requiring constant manual updates and monitoring.
Automating node selection with GitHub Actions
To solve this, we implemented a cron job using GitHub Actions. This job periodically scrapes compute prices from a publicly available source, dynamically assigning workloads to the cheapest node types each day. This strategy enables rapid responses to price fluctuations without manual oversight. Unfortunately, this is not a perfect solution.
The preemption challenge
Using only spot nodes introduces the issue of preemption, where the cloud provider may reclaim nodes at any moment, potentially leaving workloads without compute resources. A common strategy to address this is mixing spot and non-spot nodes and offering multiple node types. This works effectively only if Kubernetes consistently chooses the cheaper nodes first.
At first we thought that relying on Kubernetes node weighting, which allows prioritizing cheaper nodes for initial pod placement would solve these issues. But we found that node weighting alone has significant limitations:
Kubernetes preferences only affect initial pod placement, not autoscaling
Autoscaling naturally favors existing available nodes over spinning up new, optimal ones, leading to suboptimal node distribution over time
Detailed real-world example
To showcase why this is problematic here is a detailed example.
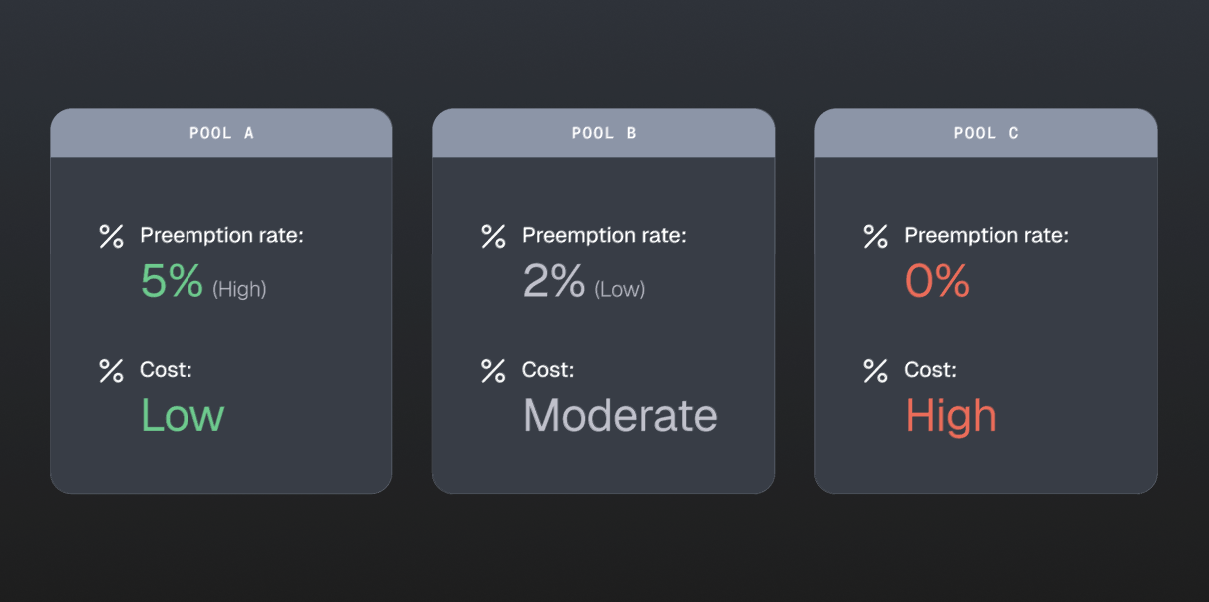
Imagine you have three node pools:
Pool A: Cheapest spot nodes, high preemption rate (5% per hour)
Pool B: Moderately priced spot nodes, lower preemption rate (2% per hour)
Pool C: Non-spot nodes, most expensive, zero preemption

Here's the detailed progression:
Initial State: All workloads run on Pool A (100 nodes).
Preemptions Begin: Nodes in Pool A start getting preempted frequently due to their high preemption rate. When a node is preempted, Kubernetes tries to immediately reschedule the affected pods.
Shift to Pool B: Pool A temporarily lacks available nodes, so Kubernetes begins scaling Pool B. Over time, as preemptions continue frequently in Pool A, more nodes in Pool B are scaled up.
Pool B Dominance: Because Pool B experiences fewer preemptions, it eventually hosts most workloads, becoming dominant.
Fallback to Pool C: Occasionally, both Pool A and Pool B nodes become unavailable at the same time. Kubernetes then scales up nodes in Pool C. These non-spot nodes remain permanently active, as they never face preemptions.
Costly Drift Occurs: Over time, Pool C nodes accumulate and remain active, gradually increasing the overall compute cost.
Compute classes: An effective solution
GKE's compute classes explicitly define priorities for autoscaling and proactively migrate workloads back to cheaper, higher-priority nodes when they become available, effectively preventing long-term drift to expensive nodes.
Compute class manifest example (using pre-created node pools)
apiVersion: cloud.google.com/v1
kind: ComputeClass
metadata:
name: my-service-compute-class
spec:
priorities:
- nodepools:
- nodepool-a-spot
- nodepools:
- nodepool-b-spot
- nodepools:
- nodepool-c-spot
- nodepools:
- nodepool-a-regular
- nodepools:
- nodepool-b-regular
- nodepools:
- nodepool-c-regular
activeMigration:
optimizeRulePriority: true
whenUnsatisfiable: DoNotScaleUp
With this configuration, GKE prioritizes pre-created node pools explicitly, optimizing cost management.
End-to-End automated workflow
Here's our complete automated workflow:
Daily Price Scraping: GitHub Actions cron job daily scrapes current spot and on-demand node pricing.
Configuration Update: If there are significant price changes, GitHub Actions updates a configuration file.
Compute Class Generation: Pulumi regenerates the ComputeClass manifest based on the updated pricing data, prioritizing nodes accordingly.
Continuous Deployment: ArgoCD automatically detects and applies the updated ComputeClass manifest to the clusters.
Dynamic management
Price Changes: Daily scraping ensures immediate adjustments in node priority as pricing fluctuates
Node Drift Correction: GKE's active migration moves workloads back to optimal nodes as soon as cheaper node types become available again after preemptions
Results
Implementing this automated, compute-class-driven strategy has yielded:
~50% reduction in compute costs by consistently using the lowest-cost nodes
Improved reliability through multiple fallback node options
Enhanced performance since we can afford to utilize more powerful nodes that were previously cost-prohibitive
Full automation, significantly reducing operational overhead
Simplified developer workflow, removing the need for engineers to manually select cost-effective nodes