Products
Solutions
Resources



Yes, you can use Statsig when your backend is heavily cached!
We speak with many companies operating at scale that have sophisticated caching architectures to ensure they have optimal performance when serving pages, assets, and even API responses to their users.
Think high-traffic web experiences that don’t have a lot of user I/O—where the main purpose is to deliver the same content to all of its users such that it makes sense to “cache” the response for reuse, which the server worked so hard to compute.
Typically, these organizations are using a CDN or hosted caching layer to ensure:
(a) their content is served from a node in close geographical proximity to their users in order to minimize latency
(b) to lessen the load of traffic that hits their application servers.
Below, we’ll outline the challenge this poses for experimentation and the various considerations we make to help companies implement Statsig while keeping caching fine-tuned.
💡 This guide assumes your objective is to test on pure server-side functionality—such as search ranking algorithms, ML models, price-testing, and more. If your test plans call for testing primarily visual treatments, consider using the Statsig Web JS SDK.
The challenge
Experimenting on the server is easy—just install one of our many Server-side SDKs and use that to assign traffic and serve the proper test experience back to your visitors.
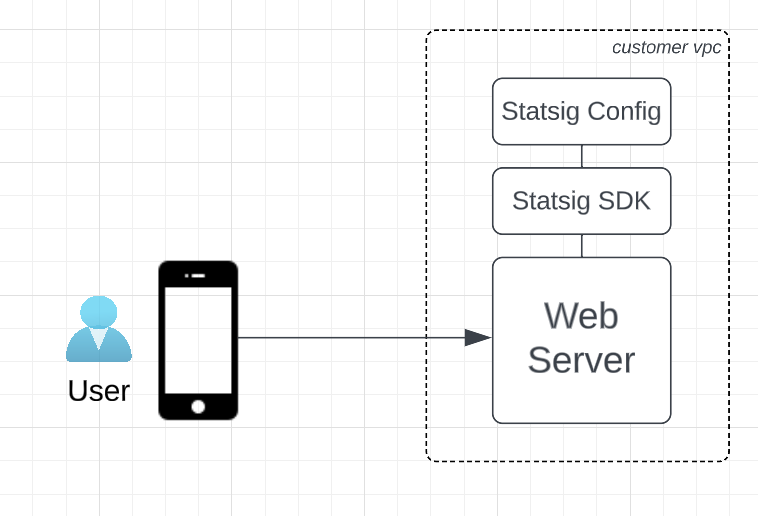
However, with a cache deployed “in front of” your server, you don’t have the luxury of running code for every incoming request in order to assign users to your test groups (ie; control vs test). In fact, it’s common that many user requests never make it to your web server.
Fundamentally, you need the following to run an experiment:
(a) User identifier that can be used to deterministically assign users to a test group aka ‘traffic splitting’, which should persist across pages and visits
(b) Code that initializes the Statsig SDK, and ensures it’s consuming a fresh ‘config’ to reflect up-to-date experiment rules configured in Statsig Console
(c) Code that calls the Statsig SDK to get the assigned test group and its parameters
(d) Code that uses the assigned group & its parameters to generate and serve the proper experience to the user.
So, how can this be done ‘behind’ a cache?
Let’s define a few terms up front:
Edge: The server nearest to the viewer
Edge Function/Edge Compute/Edge Code: This is essentially the ability to run code at the “Edge.” Providers commonly have the widest support for various NodeJS runtimes, although some offer Python (AWS) and even C# (Azure). Edge functions are used to manipulate the incoming request prior to the Cache lookup.
Cache: This is a server that stores static assets (can be content, web pages, media, etc). These are performant in that they are purpose-built for delivering a static asset with low latency.
Colocated: Located in the same network, whereby colocated services can call each other with minimal latency since requests don’t travel across the public internet.
Origin: This is the server that the cache is working for. This is commonly a web/application server that generates and serves content based on the path a visitor navigates to and other contextual information (search terms, user state, etc).
Cache-hit ratio: This refers to the frequency with which the cache serves the request without having to resolve back to origin to compute & serve the response. Ie; an 80% cache-hit ratio means the request resolves to origin only 20% of the time.
Cache object/entry: These are essentially files stored in the cache. In the case of CDNs, a cache object is commonly an HTML document or media file. Each object has a cache key.
Cache key: in computing, a cache uses a key to look into its store of objects to determine if the object exists in cache. In the case of CDNs, the cache key is the request URL. E.g., a CDN could contain HTML objects with these cache keys
/registration-page,/registration-page-2TTL aka “Time-to-live:” Used to describe how long an object should remain in cache before it expires (causing subsequent lookups to hit origin).
Using a CDN or Cache that supports Edge functions?
Edge functions the rescue! You won’t have to compromise cache-hit ratio
Our Node SDK is compatible with modern cloud providers that offer edge function capabilities. We also offer an official Vercel integration (which leverages their Edge Config feature to store a fresh statsig config. This takes care of some of the eng’ heaving lifting and ensures your implementation is fine-tuned to minimize latency).
You can deploy our SDK within these edge function environments in order to assign users to test groups and determine what to serve. The Edge function will determine which resource to serve (based on URL), and the existing cache configuration will simply return the resource from Cache or forward the request to Origin on cache-miss.
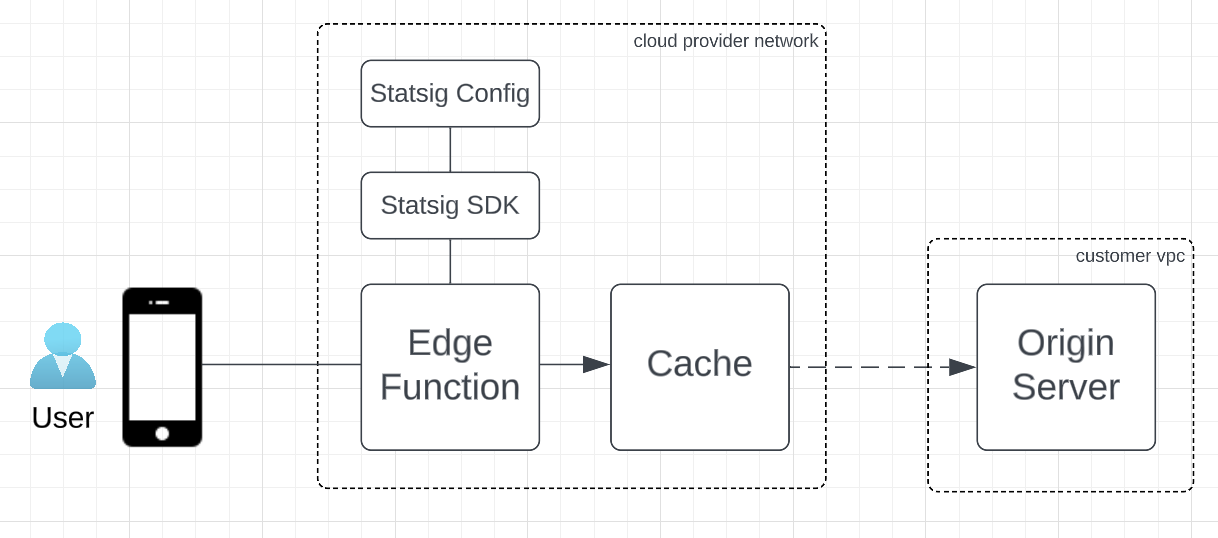
💡 The Edge function implementation doesn’t need to alter existing cache rules, and can be entirely agnostic to how cache is managed.
Your edge function should do the following:
(See this example Vercel middleware code)
Generate random userID or read existing from from cookie
Initialize the Statsig SDK client
💡 You should implement the DataAdapter interface which will enable the Statsig SDK to pull the
configfrom a local datastore, rather than reaching back to Statsig servers. This will minimize the runtime of your function and the latency of user requests.Call
getExperimentto assign the user to the experiment and get the Group parametersUse the parameters to rewrite the request URL
💡 With a CDN, the URL is essentially the Cache Key. If you’re running a homepage test, your origin server should implement the versions at different URLs, such as
/(Control),/home-v2(Group 1),/home-v3(Group 3). Once the request URL is rewritten, the Cache will determine if the object should be pulled from cache or if the request should resolve to Origin. The primary purpose of the function should be to alter the Cache Key (~request URL).Set the userID to a cookie if one didn’t exist on step #1
Call
statsig.flush()to force events to be transmitted to Statsig before the process exits
💡 This will guarantee that users are properly counted in the experiment results.
Using a Cache solution without ‘edge function’ capabilities
This may get tricky! Less modern caching tools may not offer the ability to run code at the edge, but typically offer caching rules that we can leverage to conditionally forward the request to your origin server to assign users to experiments.
The scope and viability of this solution will depend heavily on your cache strategy and cache capabilities. Given that code cannot run prior to the Cache, we’ll have to determine where experiments will be run and how to bypass the cache to call the Statsig SDK as necessary while minimizing the number of cache-misses incurred (dotted arrow).
🧠 In these scenarios, we’ll outline the various considerations you should make as well as the associated pitfalls and tradeoffs.
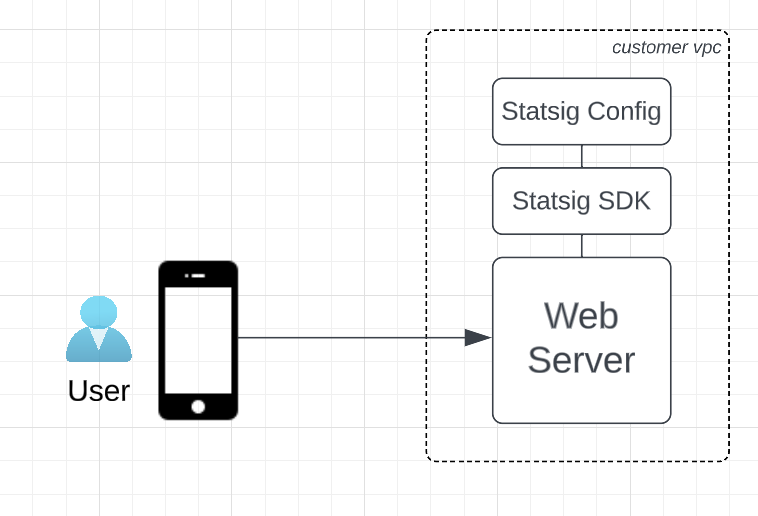
Upfront questions to determine what’s possible and measure trade-offs
Was is the cache strategy? What is the current Cache-hit ratio? Are all pages/resources cached with a universal TTL?
Does your Caching tool allow cache rules to be configured & prioritized based on URL path pattern-matching?
Does your Caching tool allow conditional caching based on request headers (Cookies)?
Does your Caching tool allow modifying the Cache Key?
Your cache supports conditional rules based on URL patterns and request cookies:
💡 This scenario allows your application server to be agnostic to caching rules, and may allow for some fine-tuning for maintaining a tolerable cache-hit ratio
Examples: Varnish offers the ability to bypass the Cache based on URL patterns (using VCL, Varnish Configuration Language), Fastly CDN offers Cache Rule config via VCL to define Cookie conditions, Microsoft Azure CDN offers Caching rule config with Cookie conditions
Your server (Origin) should implement one of the Server-side Statsig SDKs and run experiments as described in the guides.
You can define ‘bypass’ rules based on the set of URLs you are experimenting on, to tell your cache to forward all requests matching this URL pattern back to origin. This is in place of having to manually set Cache directives in your origin server’s route handler.
You can set a cookie in the response from your server the first time the user is assigned to an experiment, and then configure a cookie-based Cache rule that only bypasses the cache only if a given “experiment cookie” is missing. This will minimize the number of cache-misses. The specifics of your “experiment cookie” may depend on the capabilities of the cache you’re using — whereby a more flexible tool may allow regex matching of a cookie string that contains multiple experiment keys, and a less-flexible solution would require a specific cookie for each experiment key. The expiration rules for this cookie will directly influence the TTL when you decide to “ship” or “abandon” an experiment in Statsig.
Your cache offers no configurability
💡 This scenario is less flexible, and will result in incurring more cache-misses.
Your server (Origin) should implement one of the Server-side Statsig SDKs and run experiments as described in the guides.
Provided that your cache respects standard
Cache-Controldirectives (docs), the server responding with an experiment treatment should include a header to tell the Cache not to cache the resource for a given route. There are a number of ways to do this—you should explore which works best given the providers and technologies you’re using.Before launching the experiment, you should invalidate the relevant cache entry first (the page/content that you’re experimenting on), so that users won’t all be served the stale (original) experience. IE; if the test is running at any route under
/api/v1/pricing/[sku], you should invalidate/api/v1/pricing/*, which will remove those entries from the cache. Subsequent requests to these endpoints won’t be cached (given bullet #2).If it’s an expensive response for your origin server to compute, or it’s a page/content users will see many times, consider fine-tuning the browser-cache TTL in the response headers so that subsequent visits from a given visitor will load from the visitor’s browser cache on disk instead of resulting in a request back to origin.
Here is an example of the controls CloudFlare offers for this. ⚠️ The downside of implementing something like this, is that it’s difficult to manage and maintain test velocity, and also negates the ability to quickly stop or ship a test if everything is cached browser-side.
To learn more about how our Enterprise Engineering team can assist with experimenting on your cached content, don’t hesitate to reach out to our team here and we’ll contact you shortly 👏🏼