Products
Solutions
Resources


What is pre-experiment bias?
Whenever someone runs an experiment, they have to accept that random selection is—in fact—random. Even if your test changes nothing, a 95%-confidence frequentist analysis can be expected to yield false positives in 5% of comparisons. Microsoft has a great article on this topic.
What this means is that in some cases, your random groups will—by chance—be different from each other. In Statsig’s days-since-exposure chart you can see this as a systematic lift that occurs before the 0-mark; e.g. before any intervention, the two groups had different behavior.
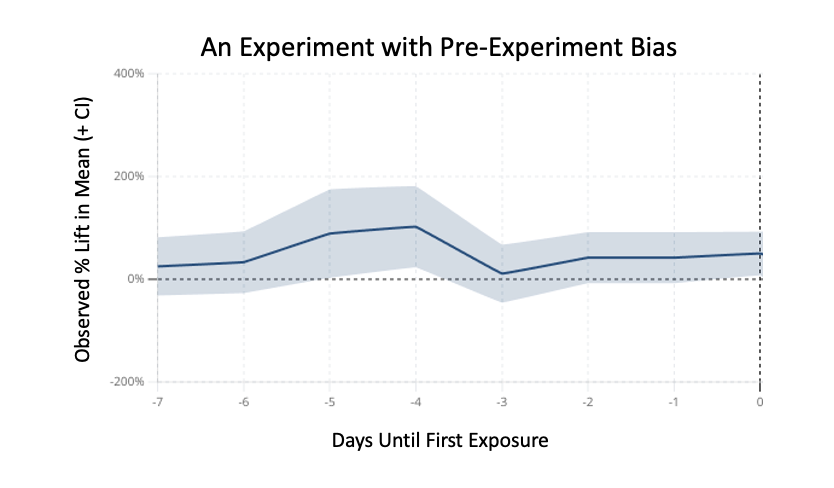
This phenomenon can lead to bad decisions. Without recognizing the bias in the chart above, an experimenter might mistake an apparent positive result for an experiment win.
Starting today, Statsig will proactively detect and flag pre-experiment bias in your experiments to ensure your results are trustworthy.
How to address pre-experiment bias
CUPED and other tools can help to reduce the impact of pre-experiment bias by adjusting experimental data based on pre-experiment data. However, this isn’t a perfect solution:
CUPED doesn’t completely account for pre-experiment bias: The correction is proportional to how consistent user behavior is over time at the user level
CUPED, even if well-documented, can function as a “black box:” users may not realize a large adjustment is happening (or not happening, per the above) in cases of bias
Certain metrics don’t have great pre-experiment analogues, such as retention and some user-accounting metrics, so CUPED isn’t always applicable
Accordingly, we have started to scan for pre-experiment bias on Scorecard Metrics for all recently-started experiments. The methodology leverages our standard Pulse lift calculation, but with a more sensitive p-value. When we detect a significant difference between experiment groups, we’ll proactively notify experiment owners and place warnings on the metric results.
In many cases, this is just a helpful warning. In extreme cases—or when there is bias on a critical metric—users are informed and can quickly respond by re-salting a suspect experiment instead of waiting days or weeks for bad results. We’ll continue to monitor this and tune the tradeoff between over-alerting and uncovering real issues.
Get started
Bias detection will automatically start running behind the scenes for all Statsig experiments, no opt-in needed. Anyone running experiments on Statsig can have confidence that they’re not running experiments that are skewed by pre-existing, random bias.
Get started now!
