Products
Solutions
Resources

Bringing conditional evaluation to a server near you
Background: This post assumes some prior knowledge of Statsig Feature Gates (Feature flags). You can read more in our article: What are Feature Flags?
To evaluate Feature Gates on your servers or in your clients, Statsig provides SDKs in a number of different languages. Let’s explore how they work.
Statsig SDKs target two different types of environments:
Single-user/client-side environments (check Feature Gate values and experiments for the current user)
Multi-user/server-side environments (check Feature Gate values and experiments for the user associated with the current request)
All SDKs expose a similar API:
initialize() — setup the SDK
checkGate() — gets the value of a Feature Gate for the user. The gate may be open to everyone, or in a partial rollout state where only certain users pass the gate, based on some predefined criteria or random assignment
getConfig() — gets the json blob of data we call a Dynamic Config for the user
logEvent() —send log data to Statsig, which is used to create metrics and produce A/B test results (e.g. Group A logs more purchase events)
The playbook for single-user, client-side environments is simple: fetch all the Feature Gates/Dynamic Configs for a user up front in initialize(), then serve checkGate() and getConfig() requests synchronously thereafter with the cached values. If they log in or log out, you can call updateUser() to refetch the Gates and Configs for the updated user. All subsequent calls are assumed to be associated with the same user.

This works well for websites and mobile apps, where a single viewer is interacting with your product. But what about a server which is responding to requests from many different users? We cannot make the same assumptions and cache Feature Gate/Dynamic Config values up front for each user.
For multi-user environments, we started simple. We made checkGate and getConfig take a user, and then hit our REST API endpoints to check the value for that user. Using the REST API required an API request for every single call to check a gate or config:

While this is simple, making an external request to Statsig servers for each Feature Gate check is unacceptable for performance.
Fortunately, we can improve this. Our server already evaluates gates and configs, based on a blob of data store in our database. Our server and first server SDK were both written in node.js even! So what if we could just pass the same blob of data down to our SDK, and evaluate conditions in the SDK as we did on our server?
We always knew we would get to this eventually — it turns out that “eventually” is now. Starting with v3.0.0 of our node.js SDK, we are proud to announce that Feature Gate and Dynamic Config conditions are evaluated locally, without a round trip to the server!
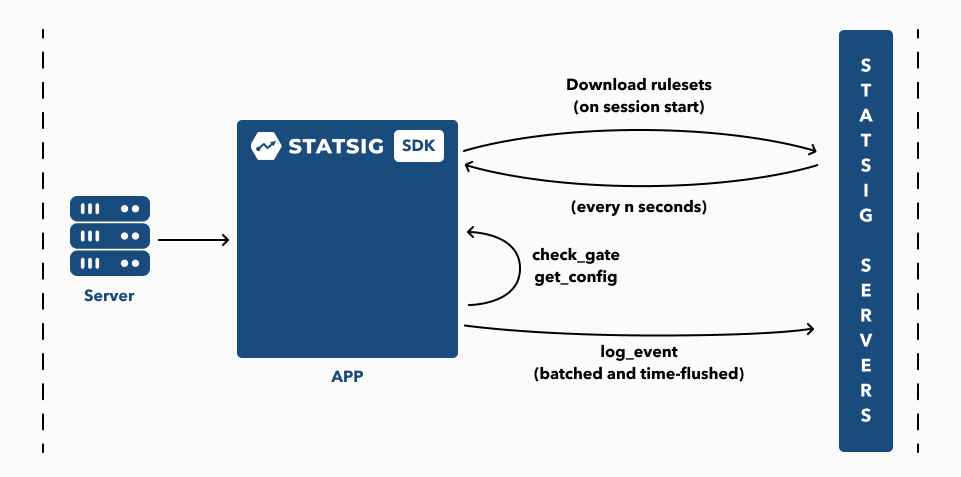
Now, instead of using the REST API for each request, the Statsig Server SDK can do the evaluation locally, and not hit Statsig servers for each request! In terms of our diagrams, it looks a bit like this:

Let’s take a look at a Feature Gate that we use at Statsig, and how that condition is evaluated in code via the statsig-node SDK.
We have a number of features under development at any given time which we only want logged in Statsig employees to see. So we have a gate, is_statsig_employee, which helps us hide these features for everybody else. This gate has a single rule and condition:

If the current user is logged in, and their account has a verified email ending in @statsig.com or @statsig.io, they will pass this gate.
That gets passed down to our SDK as a str_contains_any condition, with an array target of ['@statsig.com', '@statsig.io']. When that gate is checked in code, the server calls statsig.checkGate(user, 'is_statsig_employee'). The user’s email is used as the value that is compared to the array target.
If the condition evaluation passes, the rule (which is set to pass for 100% of users matching the condition) will pass as well. And thats how a single, string-based condition is evaluated. There are many more different comparisons baked in to power any and all of your advanced Feature Gates. Feel free to poke around the SDK code on github for more examples!
And there you have it. Though the is_statsig_employee example showcased our node SDK, we’ve now taken this playbook and applied it to a broader set languages: so far, we’ve added SDKs for .NET, java, and ruby! They are all open source and hosted on github. Waiting on a particular language? Let us know!