Products
Solutions
Resources


Picture this: Your business wants to update its customer success experience, you’re ready to launch AI feature to deliver it, and the pressure is high.
You painstakingly train your model, build the front end, dogfood it in QA, and then finally launch it to your customers. Things are off to a good start, and then it happens:
Spaghetti.
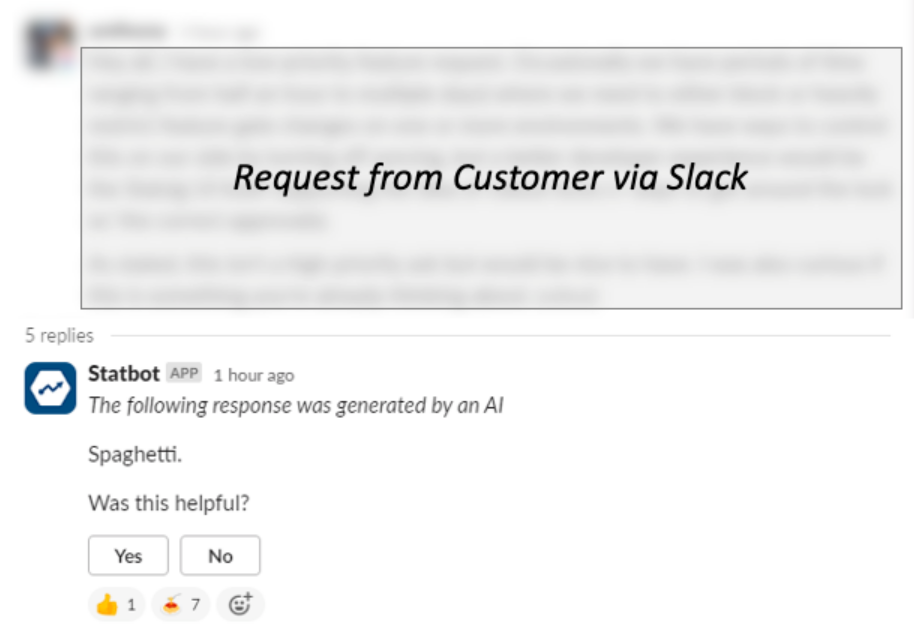
Despite your dogfooding, your AI feature begins to hallucinate in production.
This happened at Statsig when our helpful documentation-trained chatbot responded to a customer request with its favorite home-cooked meal. (In reality, the customer knew Statbot would respond and asked it to respond with Spaghetti—then edited their response!)
While malfunctions—like we thought this one was—might be low-impact and harmless, the unpredictable nature of AI features means that issues might end up being much more severe, depending on your use case.
Imagine a hallucination with more ethical or reputational risk to your company. Or even worse—one that happens outside of normal business hours, resulting in on-call engineers having to trace the product’s footprint throughout the codebase.
Issues like these are becoming more and more pertinent. As initial AI hype has transitioned into real business impact, and cutting-edge models become more affordable, it’s high time for many companies to launch AI products.
And while pressure is high to bring AI products to market, implementation isn’t simple: AI products often require integration across your tech stack—and many first iterations don’t go well as teams are mostly still learning how to build on new AI models, and the models themselves are growing every day.
If that wasn’t enough, the risks of getting AI wrong are huge. While some companies view AI more as a viral feature, others are truly innovating with it, resulting in a diverse range of quality when it comes to AI (and AI-assisted) applications.
A couple of important points to consider:
AI has complex impacts on business metrics. A new feature might seem cool, but does it actually improve the user experience in the way you anticipate?
The costs of AI. Compared to the digital business models of the last decade, AI is shockingly expensive, driven by the high cost of inference: running the models. And while prices are decreasing, AI features still can’t be launched and forgotten—their upside needs to be weighed against their cost.
As we saw with Statbot, AI systems’ behavior is unpredictable: The AI systems we’re leveraging are brand new, and their risks are not always well understood. And while the study of “AI Alignment”—how we can “align” AI with human values—is booming, in the meantime product teams need to manage the ethical and reputational risks of launching malfunctioning AI products, as we now seem to see in the news almost weekly.
How feature flags help AI builders
In our last blog post, we mentioned the various benefits of using feature flags with AI product launches, which outpace the benefits even for regular product development—where feature flags are still a best practice.
With feature flags, you can write code in production repos and with the most up-to-date context, without worrying about impacting users until you’re ready to turn the feature on.
When the pressure to ship is high, there are bound to be moments where product teams can’t wait for environment synchronization. Further challenges arise when the number of iterations to get an AI feature right means migrating it in and out of the most recent codebase.
Modern feature flags allow for targeting users with “rules” of who can and can’t see a feature, allowing developers to target themselves only at first, which enables private testing of these new features in production.
As development matures, the testing can become collaborative, targeting coworkers or teams with access to the feature. This is a great way to provide beta releases to customers or other external stakeholders—a broader audience than a typical QA or staging environment. It's here that feature flagging will first help weigh a feature’s risk, ensuring dogfooding, red teaming, and limited releases can happen smoothly before features are launched.
With modern experimentation platforms like Statsig, solving this problem is a breeze.
Using Statsig for AI feature analysis
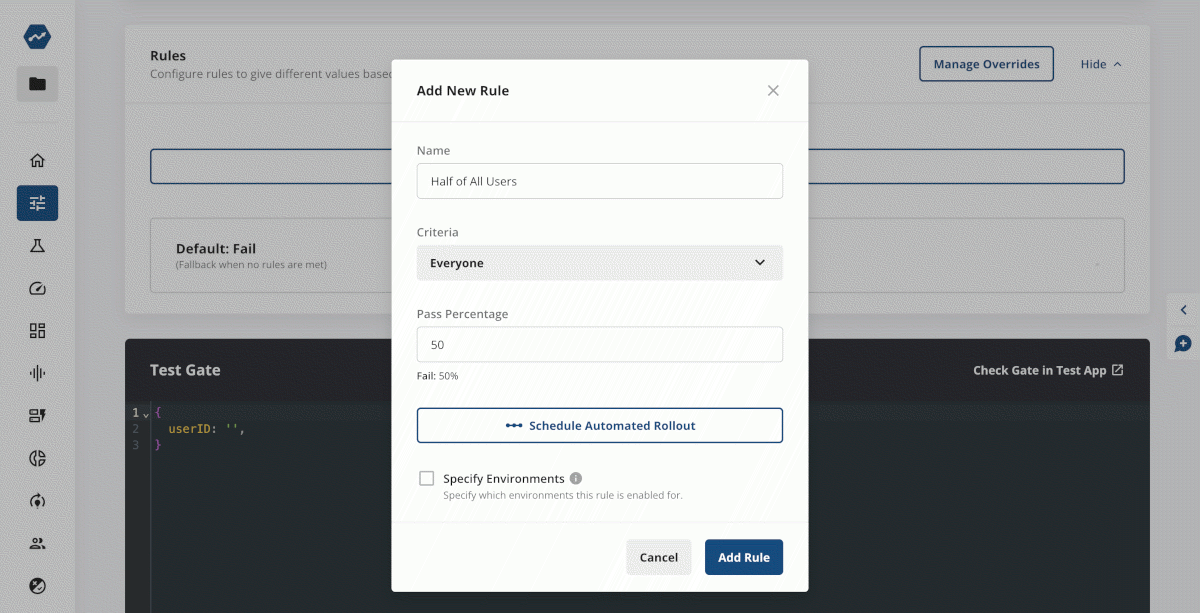
When feature flags are combined with direct logging of business metrics—like conversion rate in e-commerce, engagement rate in services, or active users across the board—product teams can directly visualize the impact of a feature launch. Say, for example, we launch an AI-driven product visualization tool on our e-commerce site, and roll it out to half of your users to test the impact:
We can directly visualize the change in conversion and retention, (as illustrated in the screenshot below) and could also add items like the respective tradeoff in cost driven by the new feature.
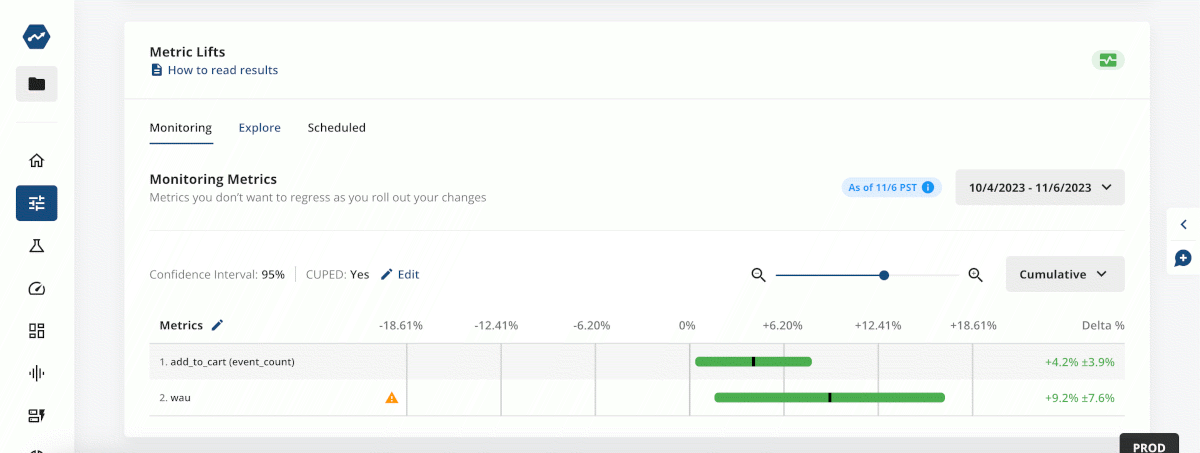
With Statsig’s analytics tools, we can even take it a step further by testing this across different populations like locales or demographics to ensure the changes we make are benefiting our entire customer base.
And finally, when mistakes happen (as they certainly will with cutting-edge models), feature flags provide the ability to instantly pull the plug without redeploying code.
Having a kill switch accessible to multiple personas within your team, from product managers to trust and safety teams, provides peace of mind in the event of an incident, and becomes integrated into standard operating procedures for incident response…A big deal for on-call engineers.
How to launch an AI product with feature flags
Launching feature flags with Statsig is straightforward, and the steps are simple:
Create a gate in the console
Add rules to target users
Add the gate check in your code
However, when creating a feature gate for an AI product, there are some specific nuances you’ll want to be aware of.
Let’s walk through the process:
1. Creating a new feature gate
If you don’t have a Statsig account, now’s the time to make one.
Note: We have a very generous free tier and a program for early-stage startups.
After you sign up, navigate to feature flags on the left-hand side, and then click Create. The only thing left to do is create a name and description and we’re ready to get started.
For the next step, you will need to have already mapped out the impact of your feature around your codebase. For some AI features, this can be complex.
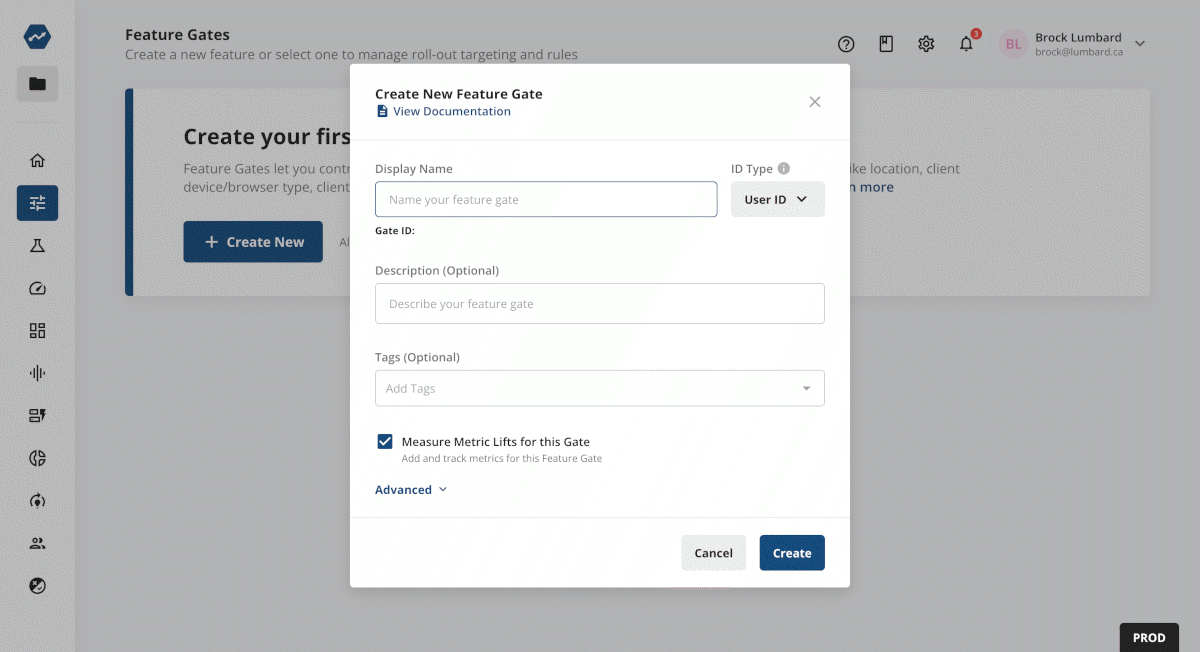
2. Setting your first rule
Rules limit which users will be exposed to the feature that you’ve put behind a gate.
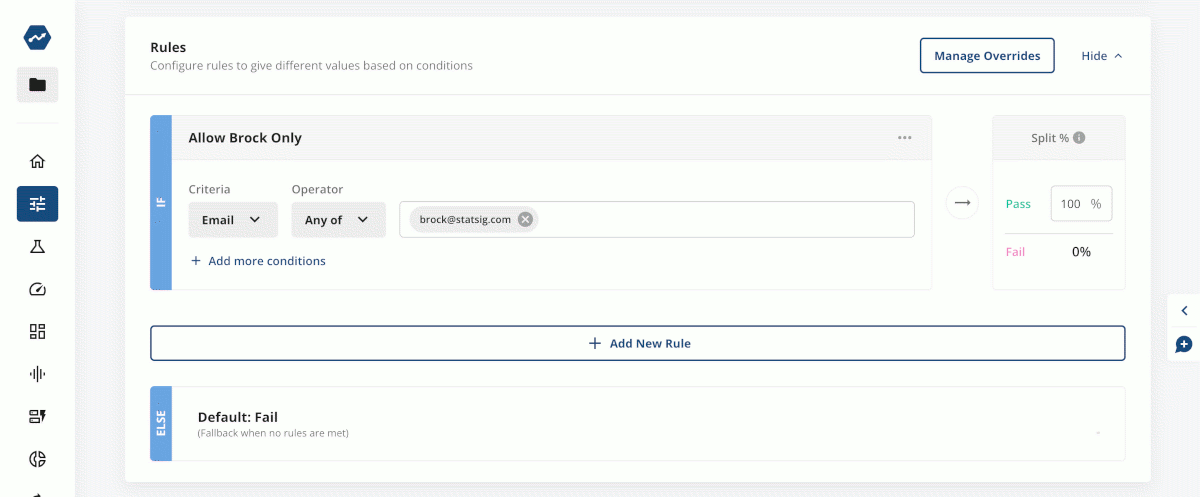
For this step, you’ll probably just want to add a rule allowing yourself, your team, or your company access. This can be done easily with a rule that targets user IDs or email domains (seen below).
Over time you can add and prioritize new rules to allow increasing access—which we’ll discuss later.
3. Implementing Statsig in your code
All it takes to implement a feature gate in your code is to initialize Statsig and check the gate.
This is where you’ll want to hide client-side (and possibly server-side) code behind feature flags to ensure it only targets who you want. AI features often range throughout your tech stack and with Statsig you can use the same feature gate in multiple places to hide features across different parts of the stack.
Statsig has a long list of server and client-side SDKs to make this task easy. For example, if you had a Python server that provided access to an AI feature, you could prevent access as simply as this:
from statsig import statsig
from statsig.statsig_user import StatsigUser
statsig.initialize("server-secret-key")
app = Flask(__name__)
@app.route('/protected-feature')
def protected_feature():
user = StatsigUser(request.args.get('user_id', '')) #assuming we include the user_id in the request parameters
if statsig.check_gate(user, "example-gate"):
# Place the code related to the AI feature access here
return jsonify({"message": "You have access to the AI feature!"})
else:
return jsonify({"error": "Access to the AI feature is forbidden"}), 403
app.run()
Where if the user ID is not included in the feature gate rules, the user would not have access to the AI feature on this Python server. Coupled with frontend flags, this would block access to the feature across the stack.
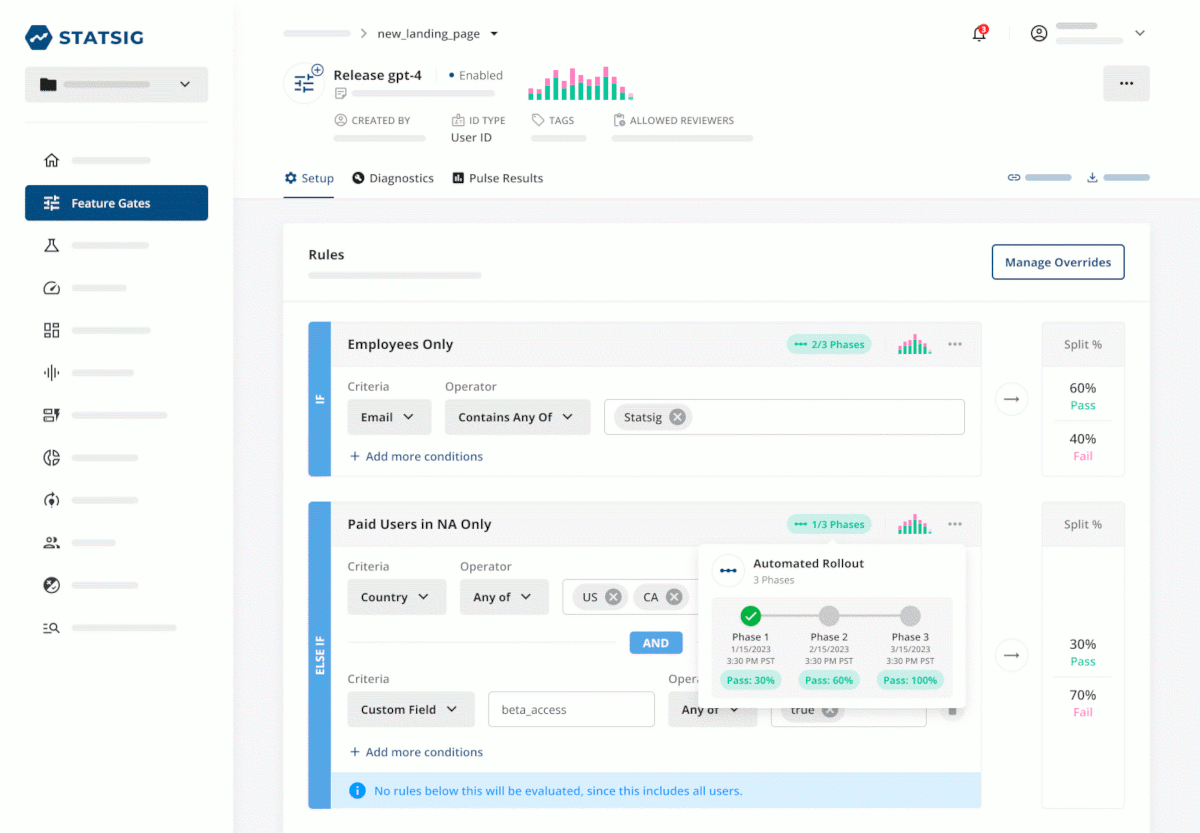
4. Using rules in production
Now that the feature is in your code (and once it's deployed), we can gradually roll it out to our users in line with your testing process.
For AI features, that might include more thorough dogfooding, red-teaming, and often more gradual rollouts to customers broadly to test impacts, costs, and more. In this process, we might choose to use a rule targeting specific user groups we’d like to test on, like a specific country or other user trait. Statsig can also schedule rollouts to make this process easier.
Further, as the feature rolls out, feature flags’ usefulness extends beyond gradual exposure: They can also be used as an instant killswitch if a feature proves too expensive, malfunctions in a way more risky than hallucinating Italian foods, or is impacted by regulation.
5. Adding analytics
Lastly, while AI features benefit from feature flags even without analytics, adding analytics makes directly attributing user behavior, costs, and more to the features you launch a trivial task.
Without log events, Statsig could still track basic user accounting metrics. With the Statsig SDK already in your code, however, it often only takes one additional line to log more insightful metrics like conversions, model usage, and more.
This enables Pulse on Statsig, but also Statsig’s broader analytics product offering which enables you to track metrics, users, and more throughout feature launches and experiments.
Feature flags provide functionality for safer, more controllable AI feature rollouts, and anyone launching a feature should at least consider using them, as they’re an essential part of the modern AI development toolkit.
As a next step, you might want to dive deeper on the benefits of experimentation tools to your AI feature development, like integrating Statsig experiments with OpenAI ChatCompletions, or using Autotune to experiment with model temperature.
Get started now!
