Products
Solutions
Resources


Lessons from Notion: How to build a great AI product, if you're not an AI company
Imagine that you’re the CEO of a successful documents company.
You know it’s time to build an AI product. You’ve read all the hype about Generative AI, you’ve seen amazing product demos from competitors, and your VCs are hounding you to incorporate AI into your product.
Where do you start? How do you build something great?
We’ve seen a number of companies build, launch, and continuously improve AI products, and we have thoughts on the recipe for success. In short, here’s what it takes to build an amazing AI product if you’re not an AI company:
Step 1: Identify a compelling problem that generative AI can solve for your users
Step 2: Build a v1 of your product by taking a propriety model, augmenting it with private data, and tweaking core model parameters
Step 3: Measure engagement, user feedback, cost, and latency
Step 4: Put this product in front of real users as soon as possible
Step 5: Continuously improve the product by experimenting with every input
We'll bring this to life with examples from Notion - who built an amazing AI product, as a non-native AI company.
First, why building AI products today is different
People have been building AI products for a long time. AI/ML features were a key point of differentiation for the last generation of great tech companies—ML models were the backbone of Facebook’s ad platform, Google’s search engine, and Netflix’s recommendation engine.
These companies could rely on AI/ML as a point of differentiation because it was incredibly difficult and expensive to build performant models. They were the only companies that could afford to pay top dollar for whole teams of AI/ML engineers, so their models gave them an edge.
The last generation of AI/ML features were defined by three things:
The model was the edge: It was very effort intensive to build a model that worked well in a given application, and it a very rare skillset. Because of this, building a great model was a big edge.
Small improvements in model performance made a big difference: Building a more performant model for a specific use case represented the lion’s share of the AI/ML work work. Small performance improvements made a big difference for a ranking algorithm or search engine, so teams of AI/ML engineers spent a lot of time focusing on incremental improvements.
AI/ML was largely hidden: These models augmented features that were built with descriptive code (e.g., Facebook’s newsfeed, Netflix’s video content). They didn’t represent new products / features themselves.
This wave of AI is different.
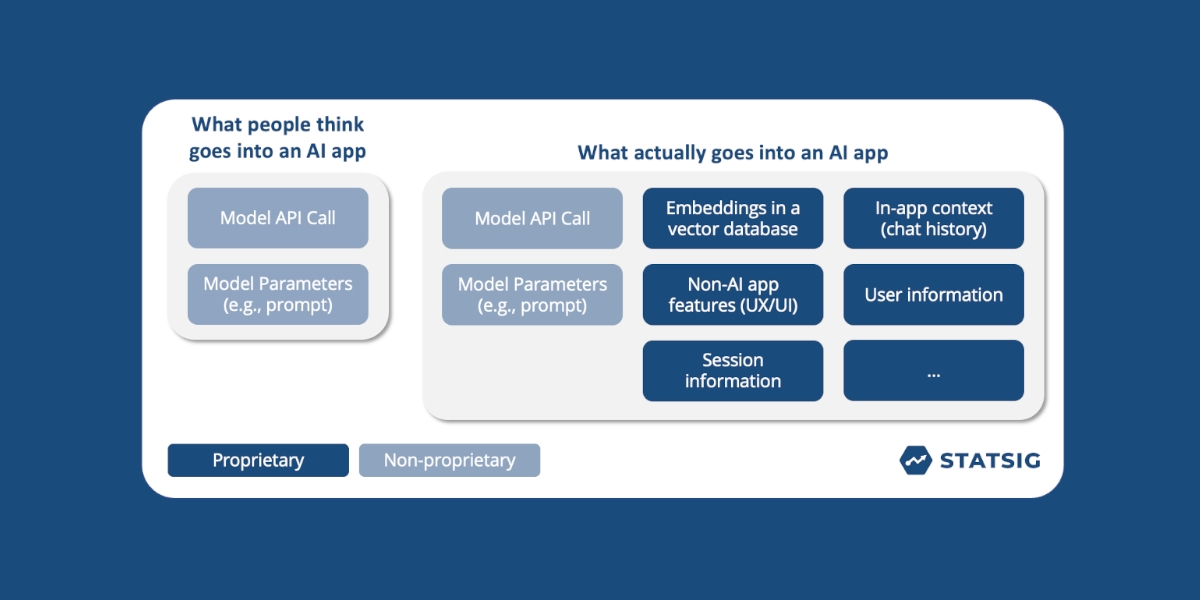
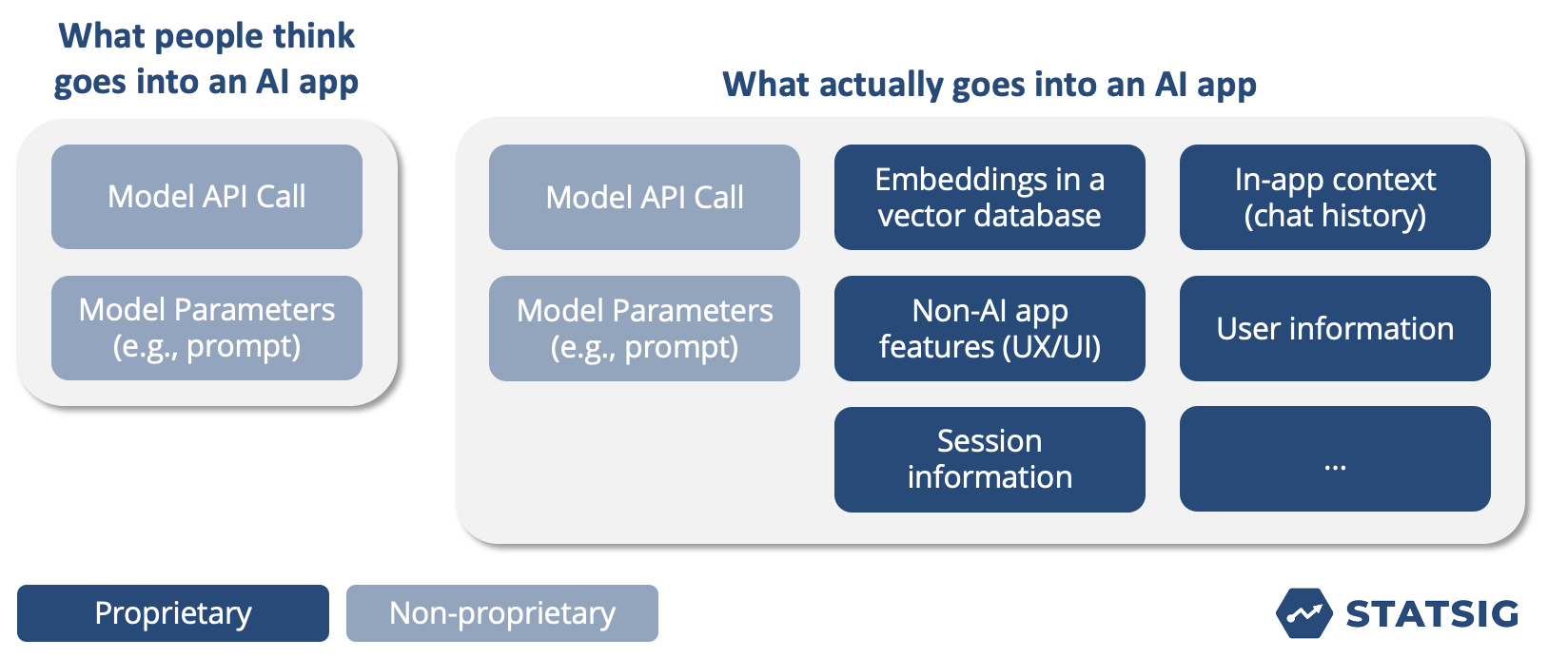
The model is no longer the edge. Off-the-shelf proprietary models are incredibly performant for company-specific applications with a few, minor tweaks. Any engineer can build a compelling AI feature with an API call, a vector database, and some tweaks to a prompt.
Small improvements in model performance will no longer give you a big improvement in application performance. Most of the “wow factor” from an AI feature will come from changes around the model (i.e., the data used in the vector DB, or prompt engineering) rather than improvements to the model itself. Unless you’re a company with very specific needs around cost or latency, proprietary models will serve you well. And you can build a proprietary model over time.
The “AI” part of the app is no longer hidden, it’s the star. The AI apps that have performed extremely well showcase the fact that there’s an assistant working for you—it’s not buried.
This means that companies have to think very, very differently about the way they build AI applications. Fortunately, we can learn from the best—and here’s how they’ve done it.
Step 1: Identify a customer pain point that generative AI can fix
Your journey to great AI features begins by finding an acute customer pain point.
There’s no one right way to discover problems or pain points. Your product and sales teams could probably name a few off the top of their head. If that fails, then customer interviews or a customer survey could do the trick.
Once you have a list of customer pain points, you should evaluate which are reasonable pain points for generative AI to solve.
There are a variety of tasks that generative AI excels in, but a few areas where it is particularly effective are:
Summarization
Expansion of an existing idea
Translation
Converting text to code
Intelligent revision/editing
The tricky part is that these are very general capabilities, which means they can be applied to almost any application.
Some ways that companies have leveraged these effectively include:
Improving search or discovery
“Auto-complete” features
Chatbots or assistants
Organic content generation
Start by holding a session and putting the list of pain points to solve and the list of AI capabilities side by side. It should be pretty clear which problems AI can solve, and which would be easiest to build—start with those!
Notion's AI product are great examples of this process.
Notion clearly began with customer pain points in mind. Here’s a screenshot from their initial press release:

Each of these bullets is a unique customer pain point. Notion is saying that their AI product can solve writer’s block, stop you from running out of ideas, catch mistakes, and summarize notes. These represent a compelling hook for initial customers to try the product and are well aligned with what generative AI products can do.
Notion was well-positioned to take advantage of these features, as a company that specializes in general-purpose writing/content. But the impact of their features comes from the fact that it’s embedded in their existing application, with existing context.
So how did they build a feature that captured this context? And how did they launch it so quickly?
Step 2: Build a v1 of your product by taking a proprietary model, augmenting it with private data, and tweaking core model parameters
Notion almost certainly built the first version of their feature using an out-of-the-box version of GPT-3. We don’t know exactly what the first stages of development looked like, but it would be shocking if the kernel for each feature didn’t start with an engineer and a foundation model API. As ChatGPT showcases, OpenAI’s models are very good at summarization, translation, and writing code without any additional modifications.
But Notion AI features can be more useful than OpenAI. Why? Because they are able to apply more context to the problem.
Their AI features use the context within the existing application (e.g., preceding sentences or lines of code) to make accurate inferences with less user direction. Within Notion’s AI, the first command is “continue writing”; a feature only made possible by the context in the preceding sentences.
They can then add additional layers of context—prompt fragments, embeddings from a vector database, or even sub-prompting routines—to further improve performance. In fact, most of the components of an AI app have nothing to do with the “AI,” they have to do with data that’s unique to your product or application.
Almost every company has some unique data source that can be used to provide enriching context to an AI application. These come from chats, user profile information, or a company’s website. Combining this unique, proprietary data with a foundation model can produce almost immediate magic.
But how do you actually embed this sort of context into an AI application?
There are a ton of good approaches. The most simple method would be to simply pass app-specific variables with proprietary information into model API calls, but this gets complex quickly. Fortunately, there are toolkits (e.g., Langchain) that make this a lot easier.
This tutorial / open-source repo is amazingly easy to set up, and very useful in showing value quickly. We actually used it to build a fun side-project: a web-hosted Statbot. There are also some great how-to guides out there (such as Pinecone’s guide to getting started with Langchain, or CommandBar's Langchain guide) that showcase the best way to combine vector databases, context fragments, and LLM APIs.
Often, the first version of your context-full app is good enough to show to users. If it’s not, then there’s more tinkering to be done. This is where swapping models, engineering prompts, and trialing different sources of context is incredibly important. But it’s shockingly easy to create something that is “good enough” to show users.
Let’s circle back to Notion. The first version of their AI product was good, but it wasn’t perfect. You can even find examples of mistakes or bad responses in their initial launch demo!

Notion AI was still good enough because of the context of the existing application! The magic came when, in natural language, you could ask the application to spell-check your work, summarize a paragraph, or translate something into a new language. That’s amazing!
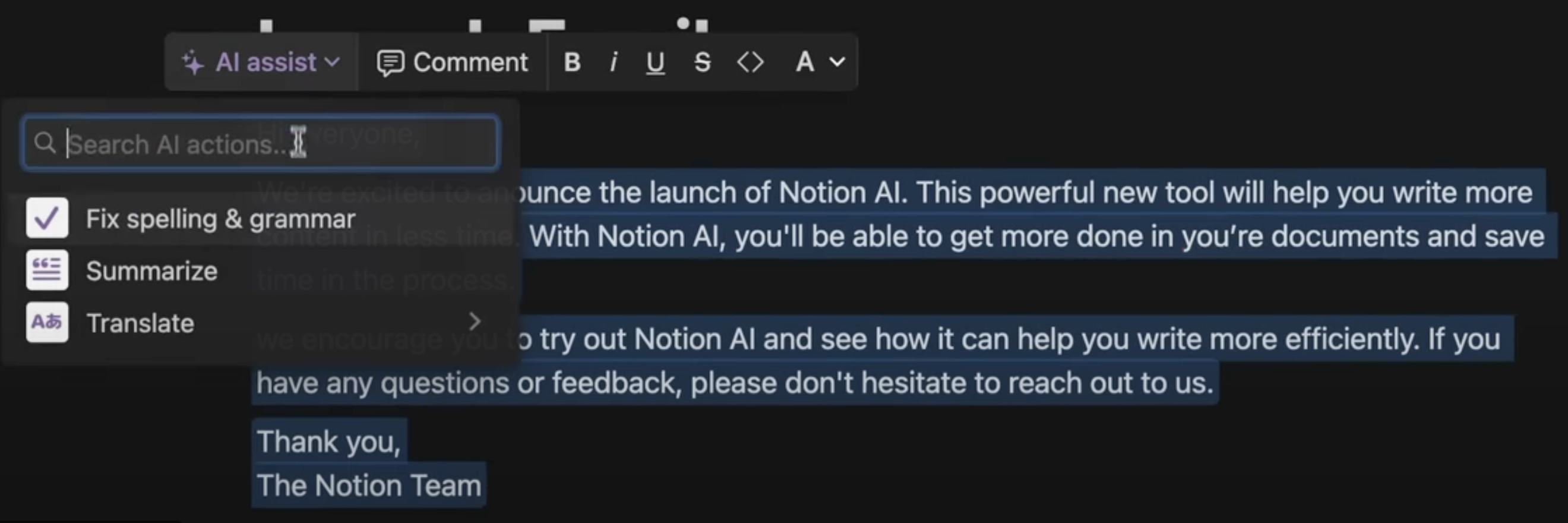
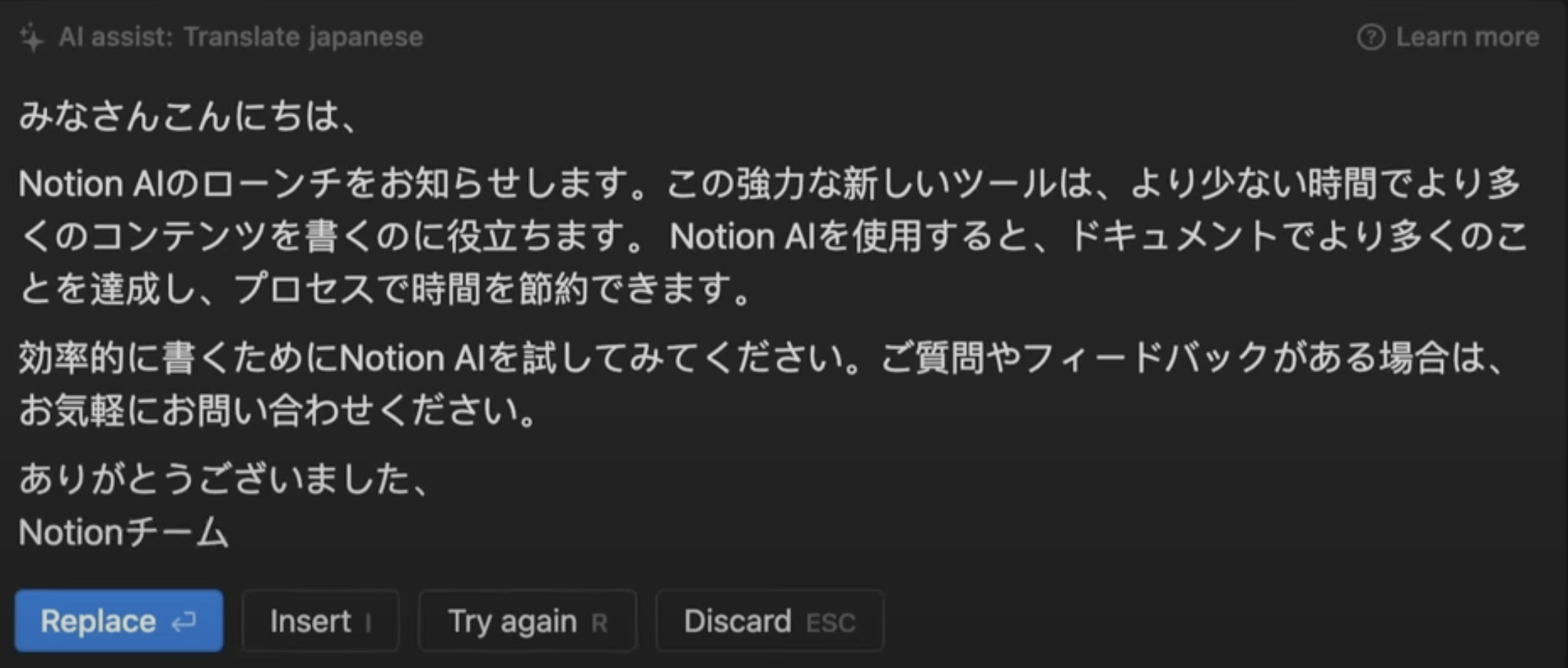
Importantly, Notion launched this feature before ironing out all the bugs. It was good enough, so they let customers start using it.
Once you hit that stage, it’s time to launch. But first, your team must set up measurement tools to ensure you can continuously improve your application in production.
Get a free account

Step 3: Measure engagement, user feedback, cost, and latency
Before you launch your app to users, you need to make sure you have measurements in place to track its success. The core metrics you’ll need to track for an AI app are:
Engagement
User feedback metrics (implicit and explicit)
Cost
Latency
App success metrics
Your first step when launching an AI feature or product is to get engagement. You must get a critical volume of users to regularly use your product in order to drive continuous, iterative improvements.
Set a metric that measures whether people are using the feature or not. For Notion, this could look like completing an AI request.
Next, you’ll want to establish metrics that capture user feedback on the feature.
The most obvious way to do this is to establish explicit feedback metrics. ChatGPT is famous for the “thumbs up / thumbs down” button, as a way to capture explicit feedback. Notion does this as well!

There are many other methods to capture explicit user feedback, including bug reports, end-of-session feedback questions, net promoter score surveys, and more. However, implicit user feedback is often a better indicator of what customers think about your feature.
For Notion AI, great immediate implicit metrics would include:
Responses that are accepted
Responses that are accepted without edits
Responses where the user asks to continue writing
Responses where the user does not click “try again”
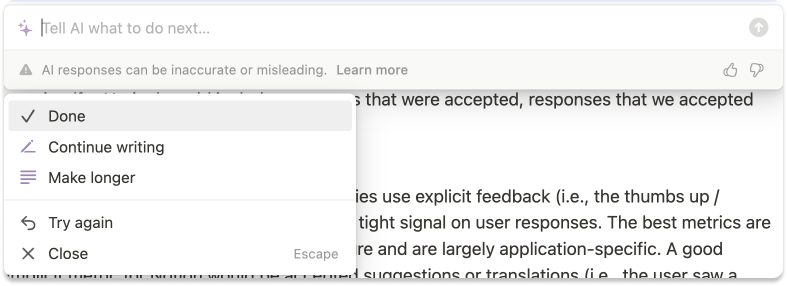
We could probably write a whole post about how to choose these metrics, but in general, they should be as responsive as possible (i.e., you can measure success in a single use of the feature) and relevant for a broad number of use cases (i.e., accepting without edits is useful for summarization and translation).
Of course, you’ll also want to track user accounting metrics for your AI feature as well. These are likely the best long-term implicit metrics you can use, though they take time to become relevant.
Next, you’ll want to measure model cost and latency. These are nice to have a benchmark for initially, to ensure your feature isn’t hemorrhaging cash. Over time, they can become incredibly important—especially when you’re thinking through the tradeoff between different models. The only way you can make tradeoffs between model cost, latency, and performance is to measure them.
Finally, you’ll want to track overall app success metrics. If the AI product is embedded in a separate surface or application, then the success metrics can be the same as the user feedback metrics. If the AI product is a part of a larger application, then you’ll want to be able to monitor the impact that AI product has on broader application metrics.
Doing this significantly reduces the risk of launching an AI feature within an existing application—if the AI feature breaks anything, you’ll know, and can roll it back.
Step 4: Put this product in front of real users as soon as possible
Once you’ve set up your metrics, it’s time to launch to users.
The best companies start with a closed alpha or beta. This is what Notion did! In November 2022, they announced a private, closed Alpha in their initial press release for the feature.

After this initial launch, they continuously opened up the product to more and more customers. Then, in February 2022, they launched it to everyone!

Progressive and partial rollouts are a great way to de-risk the launch of new AI features and learn a ton.
The closed alpha/beta should be used to capture verbal user feedback, plus run an initial tranche of experiments. These experiments should focus on big changes, where you could see a lot of impact even with a small number of users: things like swapping models, indices, or prompts can lead to massive change in performance, cost, and latency. You’ll be able to see the impact of some of these changes just by looking at responses, but others will require user data.
Once your pace of learning has slowed down and you have an application that’s performing well, it’s time to go to an open beta. Some tips:
Randomize entry to the beta, so you can see the impact the AI feature has on overall user engagement and satisfaction metrics
Conduct an ongoing holdout of users who didn’t see it vs. did see it
Expose new users to it over time, testing different, improved versions across each cohort
Conduct persistent experiments within each cohort, to create the “best version” to show to the next cohort
After you’ve arrived at a good spot, it’s time to put it into production! But the journey isn’t over.
Step 5: Continuously improve the product by experimenting with every input
After the app is in production, there’s so much more to do. With the rate at which the AI space is changing, there will be constant opportunities to improve the AI product by:
Swapping out models (i.e., replacing GPT-3.5-turbo with GPT-4)
Creating a new, purpose-built model (i.e., taking an open-source model and training it for your application)
Fine-tuning an off-the-shelf model for your application
Changing model parameters (e.g., prompt, temperature)
Changing the context (e.g., prompt snippets, vector databases, etc.)
Launching even new features within your AI modal
Again, Notion is a great example of this. Since inception, they’ve changed their UI significantly, added a new model (GPT-4), and introduced totally new features—all in production!
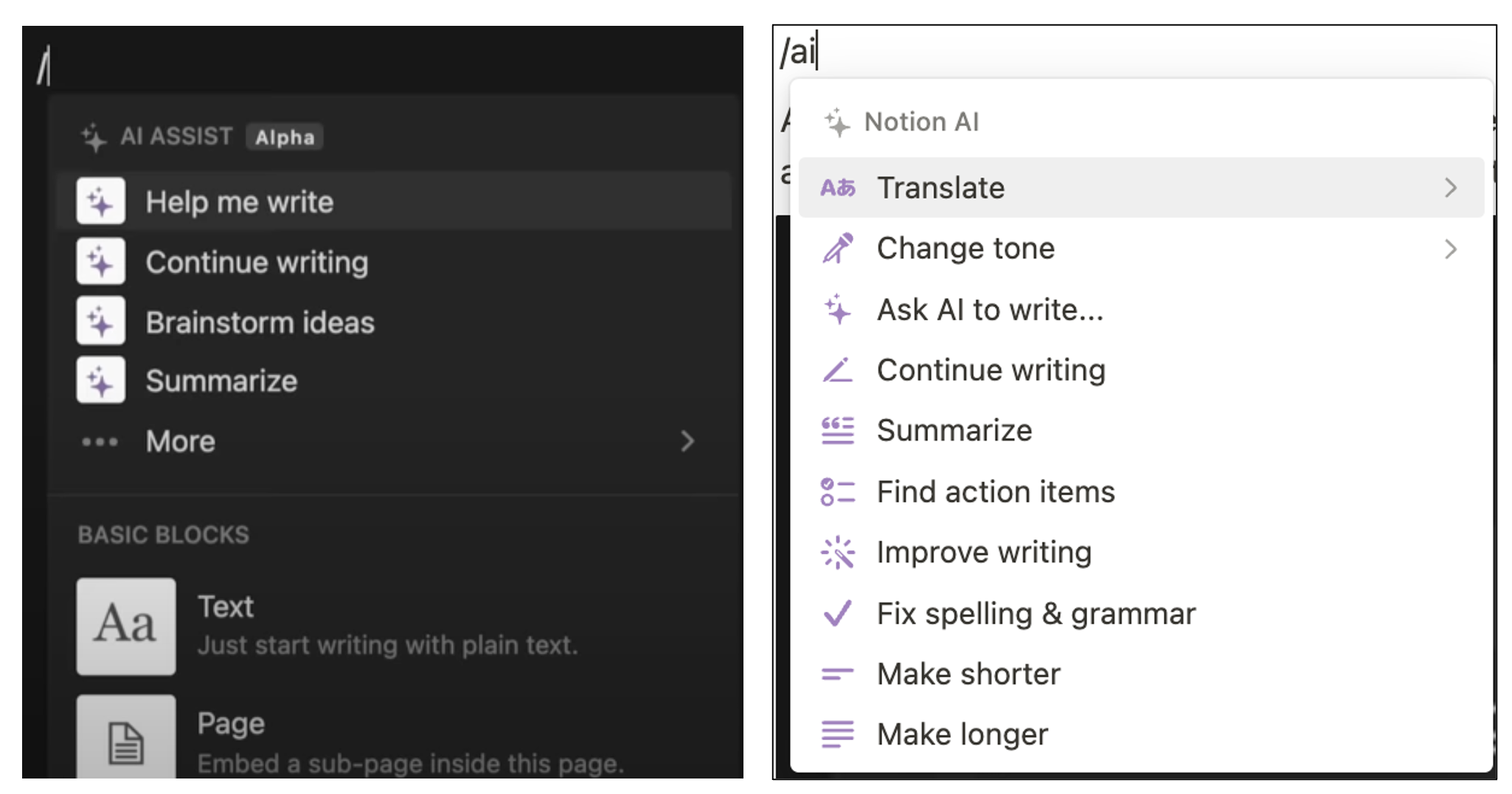
All the work in setting up the right metrics to measure success supports future changes down the road. Having success metrics gives you the confidence to launch new features because you’ll see the impact quickly. If you made a mistake, just roll it back.
When your engineer comes up with a new method or new model, your response should be “Let’s just try it.” You’ll never know how well something could work for your specific application if you don’t test it out.
Providing a system for experimentation that any engineer can access builds a culture of experimentation. In the rapidly changing AI space, this culture - where everyone feels empowered to try something new and ship it - can lead to massive breakthroughs.
This is a hard culture to build, but it starts by getting stuff out there and measuring how well it works.
Hopefully, now you have a better idea of how to do that.
Get started now!