Platform
Resources



Two weeks ago, we partnered with Madrona Venture Group, WhyLabs, and OctoML on a Seattle Seattle AI Meetup.
As with other AI events in Seattle, it was exciting and engaging, with awesome attendance: we hosted over 70 builders for an evening of great conversation around AI.
We had a rockstar panel with a wide set of experiences in the AI space:
S. Somasegar (Managing Director at Madrona) has been leading AI/ML investments for years—particularly in AI/ML ops companies.
Jared Roesch (CTO and co-founder at OctoML) did his Ph.D. in machine learning at the University of Washington, then was part of the co-founding team at OctoML in July 2019.
Alessya Visnjic (CEO at WhyLabs) founded her company in 2019, after spending nearly two years at AI2.
Our very own Vijaye Raji (CEO at Statsig) did extensive work with AI/ML teams during his time at Facebook.
This range of experience led to some interesting discussion—particularly around the history of AI/ML, the implications of the current AI wave, and the way the space will evolve over the next several years.
We’ll share a few key points below. If you want the full download, you can re-watch a recording of the entire discussion!
Takeaway #1: AI/ML has been here for a while, but this wave is different
Sometimes, it feels like AI just emerged in the tech scene in the last year. But that’s not true—companies have been incorporating AI/ML into their features for years.
Soma knows this better than anyone. He (and Madrona) have been investing AI for over a decade, particularly in AI platforms and tools.
Still, this wave is different. The new foundation models have made it easy for any company to launch features. Before, you’d have a whole team of people working on the AI / ML model that went into a feature. Now, anyone can use an API to access a model that’s insanely performant across a bunch of use cases.
This has dramatically increased the number of people who can build AI-powered applications, and the number of applications that are being built.
So while ChatGPT is amazing, the best part about this AI wave is that anyone can build apps with the same underlying model that OpenAI uses for ChatGPT. It’s a complete paradigm shift for builders, and for companies that are building tools for builders. As Alessya put it:
This is really the time to build AI applications. There’s both the capabilities and the tooling to make them acceptable in every enterprise experience
Takeaway #2: The current generation of GenAI can produce some seriously cool results, due to better models and better tools
A lot of the coverage of advances in AI focuses on the models themselves—gpt-3, gpt-4, and the APIs that let us access them. But tools play a huge role in making it easy to build and deploy AI apps.
Vijaye shared a bit about how we built our first customer-facing AI feature at Statsig (an AI-powered Slackbot), and how magical those results were.
Out-of-the-box toolkits were essential for the implementation of this AI feature, as the below graphic shows.
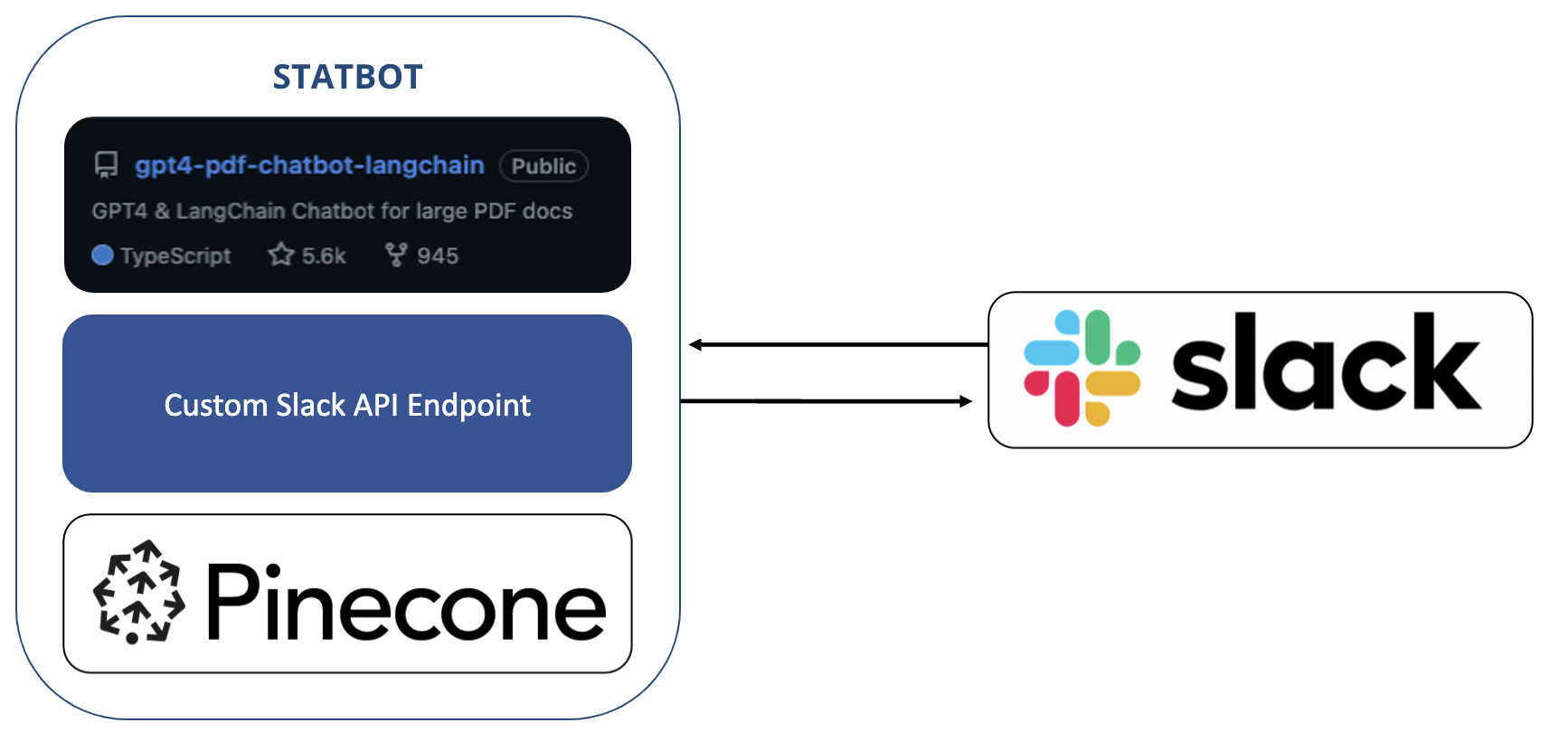
Our team was able to take an open-source repo, combine it with a pinecone vector database containing our docs library, and build a pretty robust Slackbot in only a few days. The only part we had to build from scratch was a custom API endpoint.
Our final implementation was a bit more complex, and uses Statsig to track user feedback and serve treatments to users. Still, the fact that we could build a v1 is a testament to the amazing products and toolkits available to builders today, including OpenAI APIs, Langchain, vector databases like Pinecone, deployment tools like OctoML, and observability tools like Whylabs.
Best yet, these implementations produce magical “wow” moments - like the ones Vijaye described above.
Takeaway #3: We don’t know how many models there will be, but regardless, companies need tools to deploy models quickly
There are varying viewpoints on the number of models that most companies will build with.
Some people think that large companies like OpenAI will have an inherent advantage since they can spend billions of dollars training a massive general-purpose model. The sheer R&D dollars required to train these huge models might mean that a few foundation model players will corner the model API market.
Other people look at the progress that open-source models have made, and think that it will actually be much better (and cheaper) for companies to train their own small models for specific use cases. Jared has some thoughts on this—and how tools will make an open-source world possible.
We don’t know how the future will play out, but regardless, tools will be essential for every company. Think about it—even if there are only 2 - 3 big foundation model players with 4 - 5 primary, multi-modal models, companies still need to add in their own context, adjust prompts, and change other model parameters.
When you add those in, a single company will be left with hundreds of unique model configurations to deploy and test. And they’ll need tools to help them deploy those models, observe the output, and measure the impact of changes.
Vijaye summarized the need for testing different configurations nicely.
Closing thoughts
We’re so excited to be part of a vibrant Seattle ecosystem that’s building the tools for the “AI goldrush”, and we’re looking forward to future meetups.
And if you weren’t lucky enough to make it to this event, fret not: We recorded it!
Get a free account
