Products
Solutions
Resources
A common challenge in A/B testing arises when we want to track customers from logged-out to logged-in states. Consider, for example, testing a new variant of the account creation flow. This begins with logged-out customers, but we also want to monitor key metrics and events once they complete the flow and log in.
Later on, we may even want to place them in new experiments as logged-in users. This is possible by selecting the right type on Unit ID to fit the needs of each experiment.
Proper Unit ID logging is crucial for obtaining valid results from online experiments. A Unit ID is a unique identifier for every entity in our experiment, which we use to track the group they belong to and metrics of interest.
A common example is User ID, often tied to an account created by the customer. When User ID doesn’t exist or is not available for all relevant metrics, a Stable Device ID can be a good alternative. This post explains how to select the right Unit ID type for your experiment.
Why Is Unit ID Important?
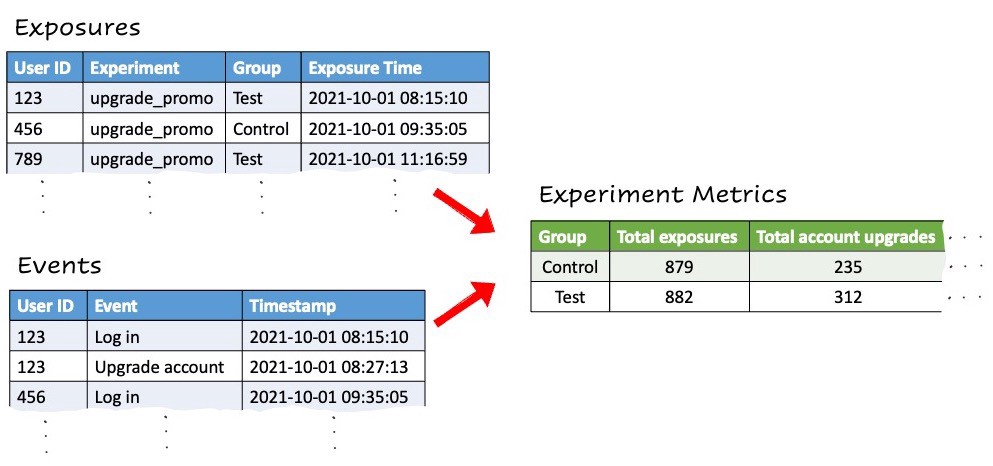
Comparing key metrics across test and control groups requires joining 2 different sets of logs: Exposures and events.

Exposures: Every time we run a check to determine which experience is delivered to a user (e.g.: test or control), we create a log containing:
Unit ID: The unique identifier used for random group assignment
Experiment name
Group: The experiment group they were placed in
Time when the check happened
Events: Any user actions and events that an app or website owner chooses to log: Purchase, Logout, Page Loaded, etc. Typically, these logs include:
Unit ID: Unique identifier for the entity connected to that event
Event name
Time when the event took place
To gain insights, we need to combine these 2 data sets and compare the event logs across the different experiment groups. This is only possible if the exposures and events contain the same type of unit ID.
Example 1: User-Level Experiment
Consider an experiment aimed at increasing upgrades to a premium tier of our product. Since we’re targeting existing customers, we already have a well defined User ID for each one. The logging works like this:
A customer with User ID 123 logs in. We run a check that randomly places them in the test group. For the duration of the experiment, they will continue to receive the test group treatment when logged in to their account. Our exposure logs map User ID 123 to the test group.
If this customer chooses to upgrade to premium, we’ll also have an event log for the Upgrade event with User ID 123.
At the end of our experiment, we can take all of our exposure logs and join them with the Upgrade event logs. We’ll know exactly how many users from each group upgraded their account after being exposed to the experiment.
Example 2: Device-Level Experiment
Now consider an experiment with a different objective: We want to test some changes to our landing page, trying to increase the number of users that create an account . We must decide which version of the landing page to show a user before they have a chance to create an account, meaning we don’t yet have a User ID at the time of the exposure check.
Instead, we create a Stable Device ID for them, which we use to log their experiment exposure. Conveniently, we can also log this same ID with any client side events from this device, such as Create Account. This now looks very similar to the example above. We can tell exactly how many devices in each group created an account after seeing the landing page.
We can go even further. If our treatment is great for increasing sign ups, but gains us less engaged customers, we want to know that. Beyond account creation, we care about their engagement during their first week: How many times did they log in? Which features do they use?
All of these logged-in actions will contain the User ID for the new account, but keep in mind our exposures are logged with Device ID only. We anticipated this and continue logging the Stable Device ID for all client events even after User ID becomes available. Since we set this up as a device-level experiment, we can produce a full suite of metrics for logged-out and logged-in events based on Stable Device ID.

What If We Want Both Types of Experiments?
That’s completely doable, as long as we decide up front which unit type to use for each experiment. In Experiment 2 above, customers that were targeted based on Stable Device ID will also have a User ID associated with their logged-in events. At that point, they could become part of Experiment 1 and produce valid metrics for our upgrade experiment based on User ID.
When Do We Use Device-Level Experiments?
User ID is often the preferred Unit ID type , but these are some scenarios where device-level experiments are a better option:
Client side experiments where User ID is not know, typically targeting logged-out or anonymous users.
Tests where we want to connect logged-in and logged-out events by the same user. Even if we know the User ID for some events, a device-level experiment can give us the full picture of what’s happening before and after logging in or out.
Drawbacks and limitations of device-level experiments:
No tracking across devices: When the same customer uses our product from multiple devices, each one is assigned a different Stable Device ID. For the purposes of our experiment, each device is treated as a separate unit with its own exposures and set of metrics. In fact, multiple devices belonging to a single customer could each end up in a different experimental group. If this is a concern, a user-level experiment is the best choice.
Multi-user devices are treated as a single unit: When multiple users access our product from the same device, the experiment cannot distinguish between them. All of their combined activity is attributed to a single experimental unit.
Not suitable for long term studies: When a customer clears their browser cookies or changes devices, a new Stable Device ID is created that’s not connected to their previous one in any way. If longitudinal understanding of the user journey over long periods of time is critical, User ID is the most reliable.
Not supported for server side experiments: Stable Device ID is only available with our client SDKs.