Products
Solutions
Resources



When building apps using large language models, developers are presented with an interesting choice: choosing model temperature.
This innocuous number can have a massive impact on model performance, as you can see below:
This is obviously exaggerated, but the question remains: How do you choose the right temperature for a given application?
A higher temperature invites greater creativity and variance, but risks producing errors—so what’s the right tradeoff? How can you optimize this for a given use case, or a given application?
Let’s discuss the ways you can use Statsig’s Autotune (our Multi-Armed Bandit), to solve this problem.
Understanding model temperature
In simple terms, model temperature is a parameter that controls how random a language model's output is.
A higher temperature means the model takes more risks, giving you a diverse mix of words. On the other hand, a lower temperature makes the model play it safe, sticking to more focused and predictable responses.
Model temperature has a big impact on the quality of the text generated in a bunch of NLP tasks, like text generation, summarization, and translation.
The tricky part is finding the perfect model temperature for a specific task. It's kind of like Goldilocks trying to find the perfect bowl of porridge—not too hot, not too cold, but just right. The optimal temperature depends on things like how complex the task is and how much creativity you're looking for in the output.
What is Autotune?
Autotune is Statsig's Bayesian Multi-Armed Bandit, which tests and measures different variations, and their effect on a target metric.
Autotune continuously adjusts traffic towards the best-performing variations until it can confidently pick the best variation. The winning variation will then receive 100% of traffic.
At a high level, the multi-armed bandit algorithm works by adding more users to a treatment as soon as it recognizes that it is clearly better in maximizing the reward (the target metric).
Throughout the process, higher-performing treatments are allocated more traffic whereas underperforming treatments are allocated less traffic. When the winning treatment beats the second-best treatment by enough margin, the process terminates.
Autotune is best used when you have a system with a single, powerful input that can be paired with a single, influential output. Interestingly, AI-powered apps that have passed an initial round of offline testing and prompt engineering meet these criteria.
Get a free account

Using Autotune to optimize model temperature
Assuming you’ve already set up an account with Statsig and have an AI-based app up and running, it’s easy to set up an Autotune to optimize temperature.
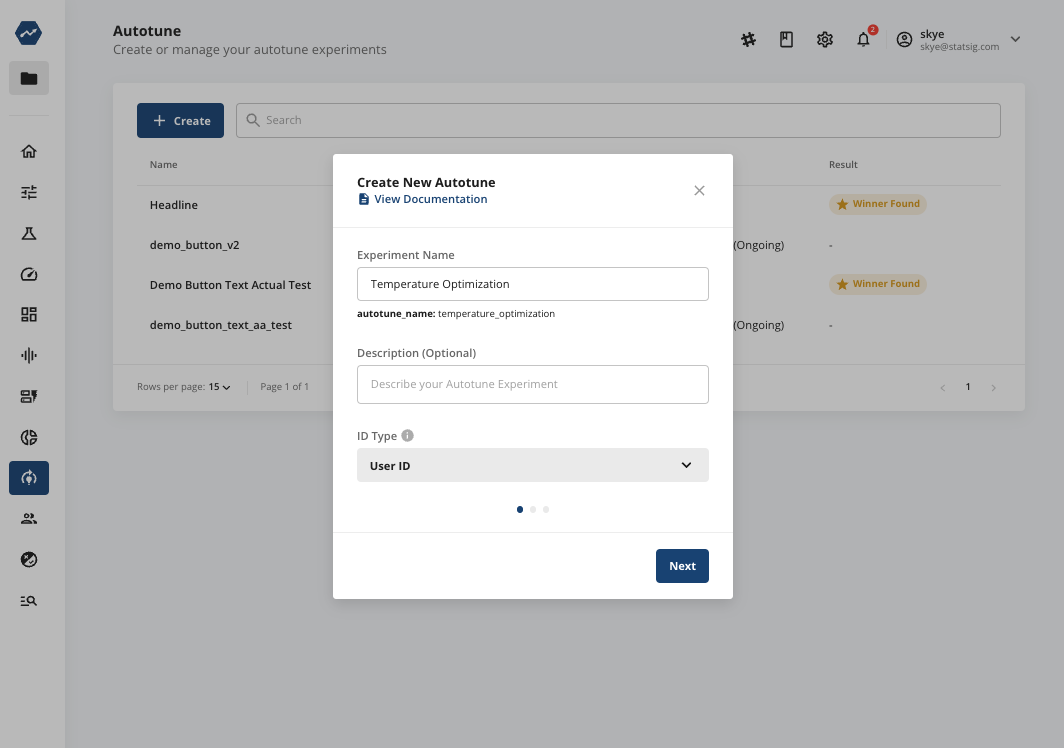
First, create a new autotune experiment, with the ID type of your choice. Assuming you’re running a consumer app or website, a user ID is likely the best choice:
Next, add variants around your desired temperature. We’d recommend not going too high, to avoid some users being exposed to some outlandish results:
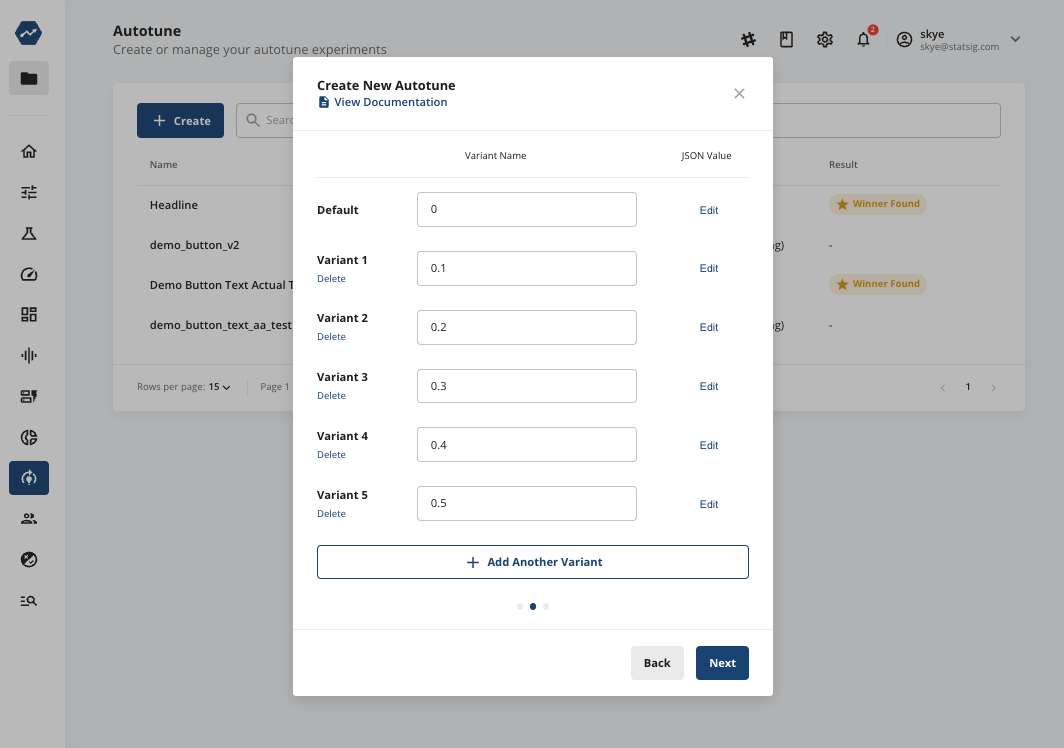
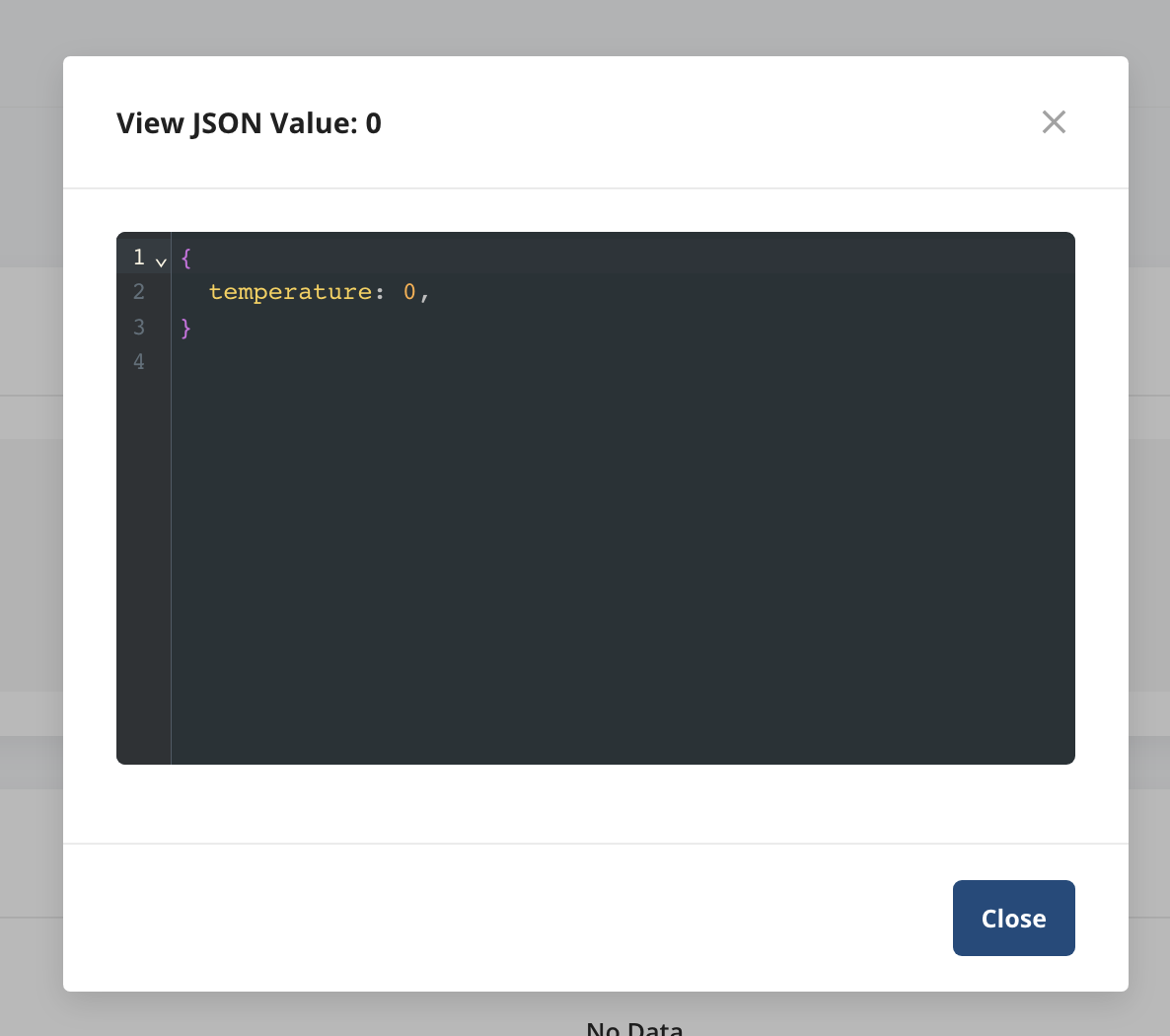
For each variant, make sure to set the temperature param value in the JSON value:
Finally, you’ll want to define your success value. For many AI apps, this could be the rate of “helpful” button clicks (or, inversely, the rate of not “not helpful”). Alternatively, it could use engagement rate, a key button click, or any other user event metrics. In this example, we’ll use “click:”
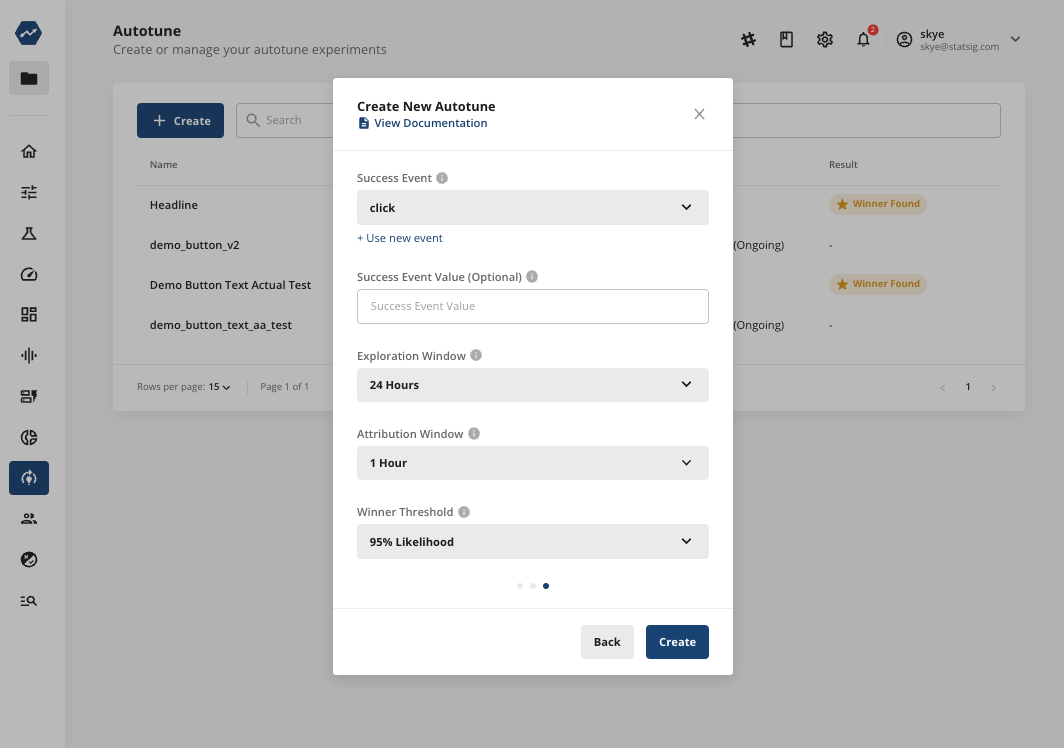
You can also adjust:
Exploration window: The initial time period during which Autotune will enforce equal traffic distribution
Maximum time window: The maximum time after an Autotune event where the success event is counted
Winner threshold: The threshold at which Autotune will declare a winner (though the default values should serve you well)
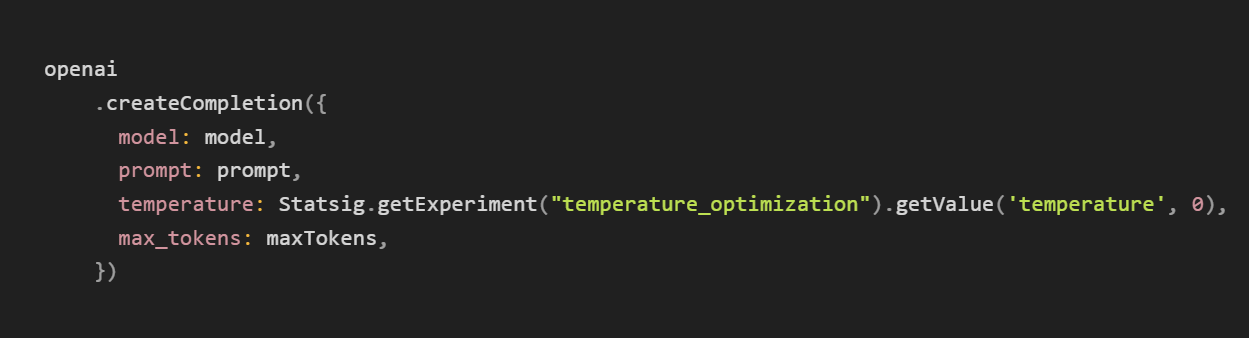
In code, you’ll just need to grab the temperature parameter from the Autotune experiment and pass it into your LLM model.
Now, just hit “create,” start your Autotune experiment, and you’ll be off to the races!
Just right?
Autotune is a useful finishing touch to optimize the performance of a mature application.
While model temperature is likely the most effective short-term application, this tool can be applied to any value with many variants (e.g., max characters, chatbot name, etc.) and a single, quantifiable output.
Unfortunately, Autotune results can’t be taken at face value. Just because you found an optimal temperature—with a given model, in a given surface, at a given point in time—does not mean it’s the right long-term solution across your app.
For more complex use cases, you’ll have to experiment with multiple model parameters, continuously. Still, we’re bullish on the impact that tools like Autotune can have for AI developers.
As more and more LLMs are released and put into production, online testing will become more and more important. The only way to know if your implementation of a black box AI model is effective is to measure the impact of every change you make. AI companies that build with a best-in-class set of developer tools will be able to launch features safely, quickly, and confidently. Those that don’t may get left behind.
Fortunately, Statsig makes best-in-class tools (like Autotune) available to everyone, so no one should be left out of the race. It’s time to get running! There’s so much out there to build.
Join the Slack community
