Products
Solutions
Resources

The ultimate guide to building an internal feature flagging system
“Isn’t it just a database”? “Why do people pay for this?”
Feature flagging is a corner of the dev tools space particularly riddled with confusion about the function and sophistication of available solutions.
Sure, you could use just a database, but do you want it to:
Be available on the client side but still secure?
Evaluate in <1ms on your servers, and not slow down your clients?
Handle targeting on any user trait, like app version, country, IP address, etc.?
Have extremely high uptime?
Work on the edge?
The answer to a couple—if not all of those—will be yes. A great feature flagging platform should have all five.
Some of these are rooted in misconceptions of how modern feature flags work. Many believe that every time you “check” a feature flag, your code should spawn a network request, but when you consider that many companies have hundreds of flag checks per page, it’s clear that’s not possible.
Imagine you want to use feature flags to A/B test or gradually roll out a feature and measure its performance. Ironically, there is substantial evidence that slowing down your pages causes a massive drop in conversion. If your feature flagging solution slows down your page, that defeats the purpose of ever AB testing it: The variant that would always win is the page without feature flags on it.
Modern in-house feature flagging systems (plus some commercially available systems) solve all of these problems. In this guide, we’ll discuss the design decisions you need to make to build a feature flag platform, plus the infrastructure, UI & client-side development efforts to get it off the ground. We’ll also discuss some of the common mistakes and usability issues in-house platforms have.
Based on our experiencing building and scaling Statsig to hundreds of customers and >1 Trillion events logged per day, this guide aims to be an authoritative guide on how to build a feature flagging platform.
Our aim is that this document is an objective overview, but we’ve at times used the Statsig platform’s conventions in our examples (not just because we work there but also because it’s the best).
We welcome productive suggestions to improve the guidance we lay out here. If you’re working on tooling like this, we’d love to incorporate your opinions. Please reach out in our Slack community to chat.
Table of contents:
1. Client, server, or both?
2. Provide on-client values, or a ruleset?
3. What kind of SDKs will I build?
4. What kind of performance and reliability extras do I need?
5. Should I provide logging infrastructure?
6. What kind of utility should my UI provide?
7. Bonus features
8. Implementation
A. Building the UI
B. Building great SDKs
C. Building great infrastructure
9. Made it this far?
The absolute basics: what are feature flags?
In one line, feature flags enable the remote limitation of which users can see a feature. A few use cases it’d be common to use a feature flag:
test a feature in production (by “gating” it to only employees/ beta testers)
rollout a feature to only certain geographies (by “gating” on user countries)
run an A/B test (by gating a feature to a random 50% of userIDs)
Or Run a canary release (release a feature to a random 10% of userIDs, to check that it doesn’t break anything)
One of the great things about a robust feature flagging platform is it lets you do all of the above with a ton of control: if anything breaks you can quickly turn a feature off, and if your metrics look great, you can roll it out without a code release.
I’m a developer: what do flags look like?
In a developer’s workflow setting up a feature flag, there are usually two simple steps:
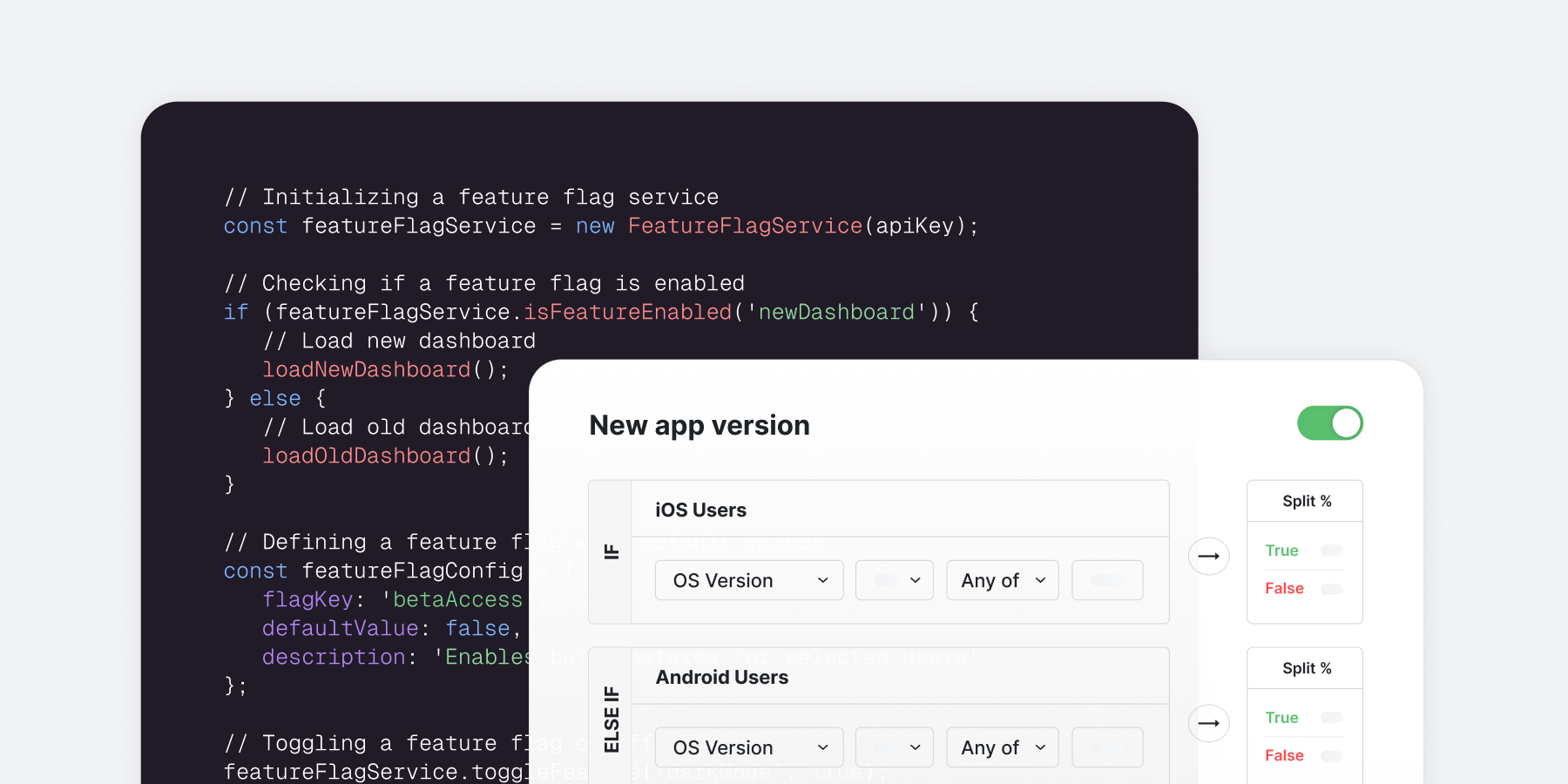
Set up the flag values remotely: Assemble a set of rules that define which users you want to see true and false. Maybe you want 50% of Canadian users, plus any employee, plus 10% of everyone else.
Call the flag in your code: While you’ll also need a line or two to set up and initialize your SDKs, at its very simplest checking a feature flag looks like this:
passed_my_gate = Statsig.checkGate(‘my_gate’, {user_id:’12345’})
That’s it. All you need is something to identify the gate, and a structure describing the user you’re dealing with in this code path.
Designing a feature flag platform
Feature flag platforms are surprisingly complex.
Instead of walking through the architecture of a great feature flagging platform, we’ll walk through a number of design decisions you should make in building one, and use those to illustrate the optimal design of a feature flagging platform. Here’s what we’ll discuss:
There are a number of design decisions you’ll need to make up-front, that’ll impact the development investments you’ll need to make. A few we’ll discuss:
Will my flags work on client-side, server-side, or both?
Will I assign users flag values on-client, or provide precomputed values?
Will I log when users are “exposed” to my flags? Will I log other events to understand variant performance?
Will I build SDKs for my developers to access these flags?
Will I provide additional fault-tolerance and caching mechanisms?
What utility will my UI provide for my developers: setup, debugging, A/B testing analysis, or more?
Bonus features: parameterization, remote configs, mutual exclusion, overrides, streaming? Segments?
We’ve made these decisions both working on in-house platforms and building Statsig. In the following sections, we’ll provide color on the pros and cons of each design decision, and give overviews of the architecture and effort needed so you have a sense of if its something you’d like to take on.

This image captures the “gameboard” of all design decisions you can make. We’ve added to this the choices Statsig made in designing our platform, and we’ll add some context on why we did.
Client, server, or both?
This is a big decision, and one most companies face when buying or building a feature flagging platform. The decision depends heavily on your current operating context, but also on the complexity you’re willing to absorb.
Feature flags on the client side: the case
Client-side feature flagging is often a no-doubt requirement for those seeking flags.
When we think of flagging a new feature, gating off the UI is often the first thing we imagine. However, modern web frameworks like Next have pushed more rendering to the server side, making server-evaluated flags capable of delivering on the common flagging use case of gating UIs.
In reality, we haven’t witnessed many customers push so much rendering to the server side that they fully forgo client-side flags, especially as some practices like asynchronous content loading remain a best practice.
Feature flags on the client side: how they work
It’s a common misconception that checking a feature flag on the client side should spawn a network request, but this is bad practice or the behavior of a nascent platform. Better is to have all of the necessary configurations on-device so that when a code path triggers a flag it can be evaluated in milliseconds.
Given that each client device only deals with one user at a time, it’s common that you’ll architect your service to provide the values relevant to that user when your feature flagging platform “initializes,” then you’ll have all of the flag values cached on-device for when they’re needed.
This involves building client-side functions to download those values and save them (for each platform you’d like to consume flags on), plus architecting a service that turns the rules you set up on the UI into evaluations for client devices.
Some platforms opt to provide the whole set of rules to the device, which offloads the complexity of evaluation from the server to the client. That design decision also comes with privacy concerns which we’ll explore in our second design decision.
To “make it real,” here are a couple of patterns you’ll commonly see in client-side feature flagging:
Common pattern: initializing the flagging system
Most platforms will provide a non-secret key that identifies the flags relevant to that user.
Add to that a representation of the user in an object, and that’s enough to fetch all of the relevant evaluations for that user. Once those evaluations are fetched, any flag evaluation can compute instantly.
It’s worth noting that initialization is one of the trickier parts of feature flagging for end users, as this is the one time you’ll have to wait for a network request before you can check flags.
Outside of just waiting for the network request, you have to employ other approaches like caching or Boostrapping, which we’ll discuss later on.
Common pattern: updating the user.
If your user object ever changes, their flag values could too. This is especially common when the user logs in and many of their properties become known. You need a mechanism similar to initialization that checks for updated evaluations.
Common pattern: checking a gate:
This one is dead simple: With the user object already known, all you have to do is Statsig.checkGate()
Feature flags on the server side: the case
Unless the only logic you’d like to flag is simple client-side changes (maybe you work on a marketing site), it’s likely you’ll want your platform to support server-side feature flag checks.
Even if your primary use case is to gate new UI features away from some users, if you only opt to limit access on the client side, you’ll open yourself up to potential abuse cases where users attempt to modify their own flag values and access new things.
Further, in many cases you’ll want to flag things only on the server side, like when the behavior of a service might change but the presentation on the frontend doesn’t. Rollouts or A/B tests on different ranking algorithms, choosing a large-language model to use, or even the impact of a performance upgrade, are all common amongst our customers.
Feature flags on the server side: how they work
Similar to client-side checks, a performant server-side setup should never need to make a network request to check a flag value. But unlike the client side, servers don’t deal with only a single user, meaning they need access to the flag values for every user that can access that server.
Typically, this means that server-side flag values aren’t “pre-evaluated,” they aren’t stored as a record of every user’s potential flag evaluations (which could be millions or even billions of values). Instead, the server usually has a list of all of the rules that you set up on the UI, and evaluates them at flag-check-time.
With properly optimized rulesets, this should still be incredibly fast, often with a negligible delay.
The development investments you’ll need to take to support server-side checks are different: you’re effectively moving the flag “evaluation” logic from a service that is called by your frontend onto each server you have that needs to use flags.
The service that provides access to the “rules” is actually much simpler than the one exposed on the client side: it just needs to provide the rules your users setup on the UI into a set of rules that the server side can evaluate against. The relative complexity of the code running on each server though, has increased, and you need to develop code that can performantly execute those evaluations, in the language your servers use.
Without a natural point to refresh the values we have from the server, values are often updated on a polling interval or streamed to the server. Because this updating isn’t reliant on request time, you never have to wait for values to be ready before you check a flag or another config.
This is an advantage of server SDKs: they’re never more than a few seconds out of date, but nothing delays values being ready to look at.
Summary & recommendation:
To summarize the effort of building a robust client-side flag platform, you’ll need:
A client-accessible infrastructure service that turns your rules into evaluations for a user
Client-side code that downloads these values, caches them, and executes checks
And to build a server-side platform, you need:
A service that encodes your rules and provides them to each server you’re running your flags on
Code for your servers that downloads these rules and executes against them for each user object, plus polls in the background for updates to the ruleset
While it means a commitment to building and maintaining two services for flag delivery, and a service to consume those flags for every client/server environment you have, most internally built feature flagging platforms choose to provide both client and server-side flagging systems.
You’re also likely to find some synergies in the code you write across these two services - for example, the service that provides evaluated flag values to clients can borrow logic from the code that evaluates rulesets on your servers, provided they’re written in the same language.
Provide on-client values, or a ruleset?
As mentioned above, most feature flagging systems choose to convert rulesets into values for a user on the server, concealing the full ruleset from clients. In line with this, most platforms provide separate API keys for client and server instances, where the former can only collect values for a single user, and the latter can retrieve full rulesets.
This leads to more complex infrastructure builds but, has security benefits and reduces the burden on clients.
The case for only having ruleset APIs:
Only having ruleset APIs means that both your clients and servers using feature flags will consume the exact same API. This substantially reduces the infrastructure complexity your system will have, as you’ll have only a single service, with very limited processing burden.
It’s likely you’ll have few enough rulesets with few enough changes made to them that they can be accessed through a CDN. This isn’t just less complex, it’s also very affordable, as you’ll have next-to-no egress costs from your servers (many CDNs offer very cheap or free egress).
There are also rare but legitimate functionality benefits to using ruleset APIs on clients. Some client devices may serve multiple users or have frequently updating user attributes: if you want to update flag evaluations immediately for a new user without a network request, and without checking if the rules have changed, then ruleset-based APIs on client devices may have the advantage.
The case for having both ruleset (for servers) and computed (for client) APIs:
The main downsides you’re accepting if you choose not to have a pre-computed server is privacy and client-side evaluation complexity.
The former is the greater concern. If you’re allowing client devices to access full rulesets, you’re accepting that they’re public, which means you can’t safely store some of the logic you’d otherwise likely incorporate, like userIDs, variant names, etc.
You could take the approach of hashing some of these values which will obfuscate some (but not all) of the information a rule could contain, but you’re then subjecting your client to frequent hashing while checking values, and if it's a secure hash, those hashes will take time.
While efficient rulesets should limit the burden, you’re also asking client devices to compute every evaluation, which on less performant devices could certainly run into both memory and processing concerns.
Summary & recommendation:
Forgoing the build-out of a computed API will substantially reduce your infrastructure’s complexity and cost, at the expense of its security and client-side burden. Without substantially restricting the information that can be added to your feature flag’s rules, most designs will want both ruleset and computed APIs. Most modern in-house and commercial feature flagging platforms provide both APIs.
What kind of SDKs Will I Build?
When we say SDKs - we mean the APIs that the developers using your feature flags will write into their code to call them. These are a substantial part of the product - they’re not similar HTTP wrappers, given some of the logic we’ve discussed above.
Aside from all of the hairy implementation complexities we discuss in this article, there is another complexity at play in the success of a feature management build - will anyone actually use it? Without adoption, your build won’t succeed, and to succeed, you need to build convenient, ergonomic SDKs for your development teams to consume feature flags with.
Will I provide server-side SDKs?
Short answer: you probably have to. If you read the last couple sections, you’ll understand that the role of a server SDK is to convert encoded rules into feature flag values (sometimes as simple as True/Falses) for a given user.
Rulesets are usually just JSON blobs with the rules encoded for each flag. To understand how hard this is, let's take a look at the ruleset Statsig generates for a flag with three rules:
50% of Canadian users,
plus any employee,
plus 10% of everyone else.
Without going too deep into the details, this ruleset needs to include
Metadata: the flag name, salt (that you use to seed the randomization), the flag’s state, what ID the flag randomizes on, etc.
The rules: the rule’s pass percentage, operator type, field to operate on, the value(s) you’re searching for, etc.
To turn this into a flag value, at the very least your server-side SDK needs to be able to search this spec for the flag it's looking for, translate each of the available rules into logic to evaluate, and execute on the randomization behavior using the ID type and the provided seed.
Further—in the example of these rules—the Statsig SDK is also resolving country for each user from their IP Address to check if they’re in Canada, which is an unnecessary but convenient feature to add. One final requirement is you’ll want this to happen identically across every type of server environment you have (where the biggest concern will be the coding language you can execute).
This isn’t trivial, and it can’t be expected that developers will use a feature flagging system if they have to involve themselves in any of the above. This means you should be looking to provide an SDK that abstracts all of this away.
Will I provide client-side SDKs?
These are less of an obvious choice if you chose to provide precomputed SDKs in our last step.
When those values are fetched, they’re in a friendlier format to work with. If you’re curious, go to statsig.com and open your dev tools, then click Application -> Local Storage -> Statsig.com and take a look at the values presented there that have .evaluations. in them.
The flag names are hashed, but you’re seeing a handful of feature flag evaluations all device, where the name, value and rule_id are all there one layer deep in JSON.

You’ll definitely want your developers to have an easy way to save down these evaluations from the server, and it's probably a good idea to provide an easy way to access those (but it would only be a line of code or two if you didn’t).
Should I provide SDKs for other situations?
Another situation you might consider is providing SDKs for serverless or the edge.
Your Server SDKs might work alright here, but you may run into constraints around the runtime of your serverless functions (as they’ll have to load up the ruleset each time, spawning a network request).
You might want to maintain up-to-date rulesets somewhere the serverless functions can access, like a Redis instance, or in the case of edge function providers, many of them provide solutions for fast access to small amounts of data at the edge, like Vercel Edge Config or Cloudflare Workers KV.
If you’re a heavy serverless user, you may want to integrate your rulesets with these storage solutions.
Summary
You'll almost certainly need some baseline SDKs for your developers to consume your flagging service. You'll be able to narrow the effort here to only the languages and environments that your teams work in, which should be a manageable workload. Lastly, your effort here could be assisted by the abundance of open-source SDK code available, take a look at the Statsig SDKs here.
What kind of performance and reliability extras do I need?
Reliability options:
Both client and server flag systems should likely have built-in, local fault tolerance.
Either system relies on the ability to fetch values from a remote server, but even high-uptime servers only have four 9s, meaning you’ll want some ability to recover if the server becomes unavailable. Typically, client-side implementations can recover in these situations by caching values in local storage each time they receive them (as we explored on Statsig.com in the previous section).
This provides fault tolerance for the vast majority of users who have visited your website before. For users that haven’t visited your website yet, you’ll want to set up logical defaults for when values aren’t available. In the case of feature flags, this is usually as simple as defaulting to false if your feature flag calls fail.
Of course, servers don’t have access to similar stores. While they can hold the values in memory for the lifetime of the server, new servers starting up would fail without values in the case of a ruleset server outage. An alternative is setting up a data store for your server so that it can save and retrieve rulesets, often from a simple cache like Redis.
You can choose to ask each server downloading your ruleset to update the Redis cache, and any new server can take the latest ruleset cache in the case of a ruleset server outage. Some commercial products take this concept a step further, providing the option to have a whole server dedicated to downloading and storing the rulesets, which each separate server loading the rules can poll or stream values from.
LaunchDarkly’s Relay Proxy and the Statsig Forward Proxy provide a service like this. The advantages of a solution like this would be different when adopting a commercial product vs. building your own. For example, one of the main examples of LaunchDarkly’s relay proxy is that only one server requests rulesets, reducing the ingress cost you might incur—but this may be irrelevant building in-house if your flag system was entirely managed within your network.
For an in-house solution, one server responsible for providing up-to-date values to the other might be able to take responsibility for converting the UI configurations into rulesets, and could ensure that values were consistent across all of the servers downloading rulesets.
Performance options:
Perhaps the single largest performance concern with feature flagging solutions is first loading values for a user on the client side. There are two common approaches here, neither of which is a technical revelation but both of which can make loading time a non-problem.
The first is caching values from each session and relying on cached values by default. This means you need to design your client-side code so that on startup, it checks local storage for cached values, and relies on those to present the user with the desired experience.
This will substantially degrade the responsiveness of your flagging system: if you need to turn a feature off urgently, you can’t expect that it’s been disabled for users unless it's their second time visiting since the change.
The second approach to eliminating wait time before you have values is to piggyback on other requests your client is making to your servers, generate the value for them server-side, and package it with those responses.
For example, if you’re using a Next.js web server to serve client-rendered frontend code, you could package the values for that user with the returned HTML, eliminating the need for a second consecutive request to get flag values. Of course, this requires additional server-side functionality: your server code that manages rulesets has to be able to create a set of all evaluations for a particular user and pass it down in a format that your client-side codes can work with.
At Statsig we call this "Bootstrapping" the SDK, and it's our recommended approach for performant front-end applications.
Another common concern is keeping your servers performant when they’re managing large rulesets. Managing the size of your rulesets is one important tactic. Commercial solutions provide tactics to isolate which flags’ rules you like to include in which payload, often identified by the SDK key you use.
Another tactic to consider is implementing streaming: streaming can substantially reduce the memory burden on your servers, as only changes to rulesets can be propagated to SDK as they happen, rather than polling for changes on a regular interval.
Summary and recommendation:
This is pretty dependent on the constraints of your domain, but most sophisticated software builders will likely want at least some of the above, with bootstrapping perhaps the most common option.
A practical approach is to start without any of the above, and add them in as constraints dictate is necessary
Should I provide logging infrastructure?
Logging infrastructure is SDK and server-side code that enables you to send individual events back to your feature flagging platform.
If you use something like a CDP (Segment), Product Analytics Platform (Amplitude), or something else like Snowplow, you're likely used to seeing in-code event logging with syntax like .track() or .logEvent(). We're talking about functionality like this, but for both metrics collection and logging exposures to individual flags.
Why provide logging infrastructure for "exposures"?
In short, if you'd like to know when your users encounter one of your flags, and what it evaluated to when they did, then you'll want to have exposure logging in place.
The obvious value here is debugging, imagine the frustration of pushing a big feature to prod behind a gate, rolling it out to 10% of users, but receiving no clear feedback on if users are actually seeing it and your flag is evaluating correctly.
This isn't the only value though, if you'd like to employ more sophisticated techniques like measuring the impact of a rollout on user behavior, you'll need to record those exposure events.
Why provide logging infrastructure for other events?
If you'd like to collect events/metrics to analyze the performance of your rollouts, then you'll either need to build this, or enable integrations to import outside data, like from those platforms mentioned above: CDPs or Product Analytics platforms.
You might find building this worth it if:
You've built logging infrastructure for exposures, you've already done the hard work here, and
It's a nice bonus for developers to be able to work with both event logging and feature flags in the same SDK or namespace.
Summary and recommendation
This is another one where you can appreciate some Statsig bias: We believe in the value of measuring every rollout, and you'll need both of these event logging types to make that happen.
Generally, we think that not logging exposures is bad practice, making debugging substantially harder, and recommend that all platforms invest here.
What kind of utility should my UI provide?
Setup
At the very least, your UI should provide simple tools for constructing flags and rules, that’ll then be converted into rulesets on your backend.

This is not an extremely complicated task, but its recommended to pay some attention to the usability here. Cascading evaluation of rules can be unintuitive to some users, especially if you choose to include functionality for randomization and multiple variants.
Most commercial feature flagging platforms provide UIs to set up rules like:
Time targeting
App Version
Attributes parsed from your user agent: Browser name, browser version, operating system, device type
Attributes parsed from your IP: Country, locale.
Environment (Development, Staging, etc.)
Of course, every rule you choose to support on your UI, you'll also need to build server-side evaluation support for.
Debugging
This is optional, but is some of the highest utility functionality you might include.
The debugging functionality you can consider providing goes deep: you can consider providing evaluation explanations and other debug information in your SDKs, logging records of actual user assignments, and providing tooling to understand the evaluation of an individual user object. To explore each:
In-SDK Debug Info: When you check a Gate, a lot is going on. You’re relying on the success of multiple systems: your flag rules are propagating correctly to your ruleset servers, your SDKs are evaluating them properly, and the developer hasn’t made any mistakes. They’ve initialized the SDKs correctly (and with a correct SDK key!) and they’ve called the right method and flag name. Great debug info helps you understand each step: where did this data come from, did it evaluate expectedly, and when it evaluated, what did it evaluate to? Once again using Statsig as an example, this is what a feature flag object looks like when you get it post-evaluation:
<insert eval in devtools>here we know what our value was and that it evaluated expectedly (Network:Recognized, which tells us the value came from the network, and was a recognized flag), plus we know which rule we landed on (rule_id) and when the value was last updated/propagated to us.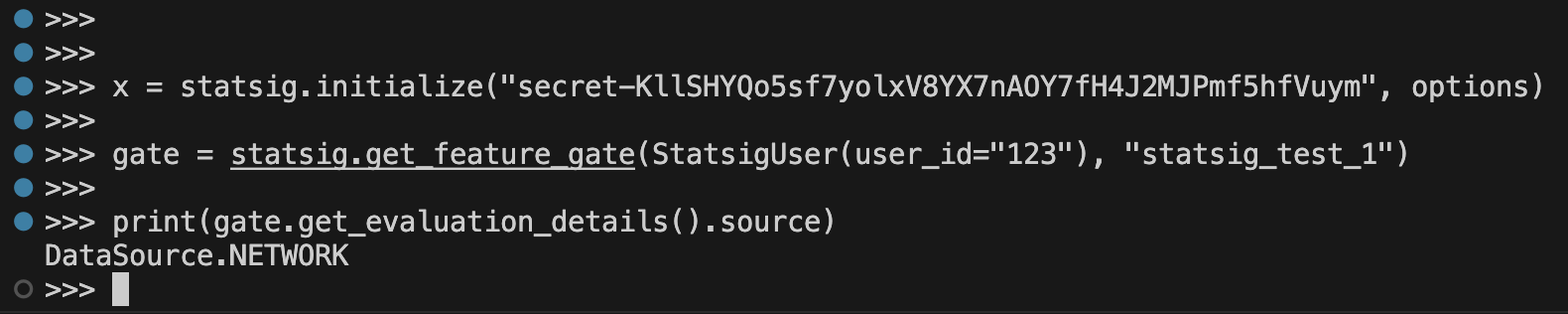
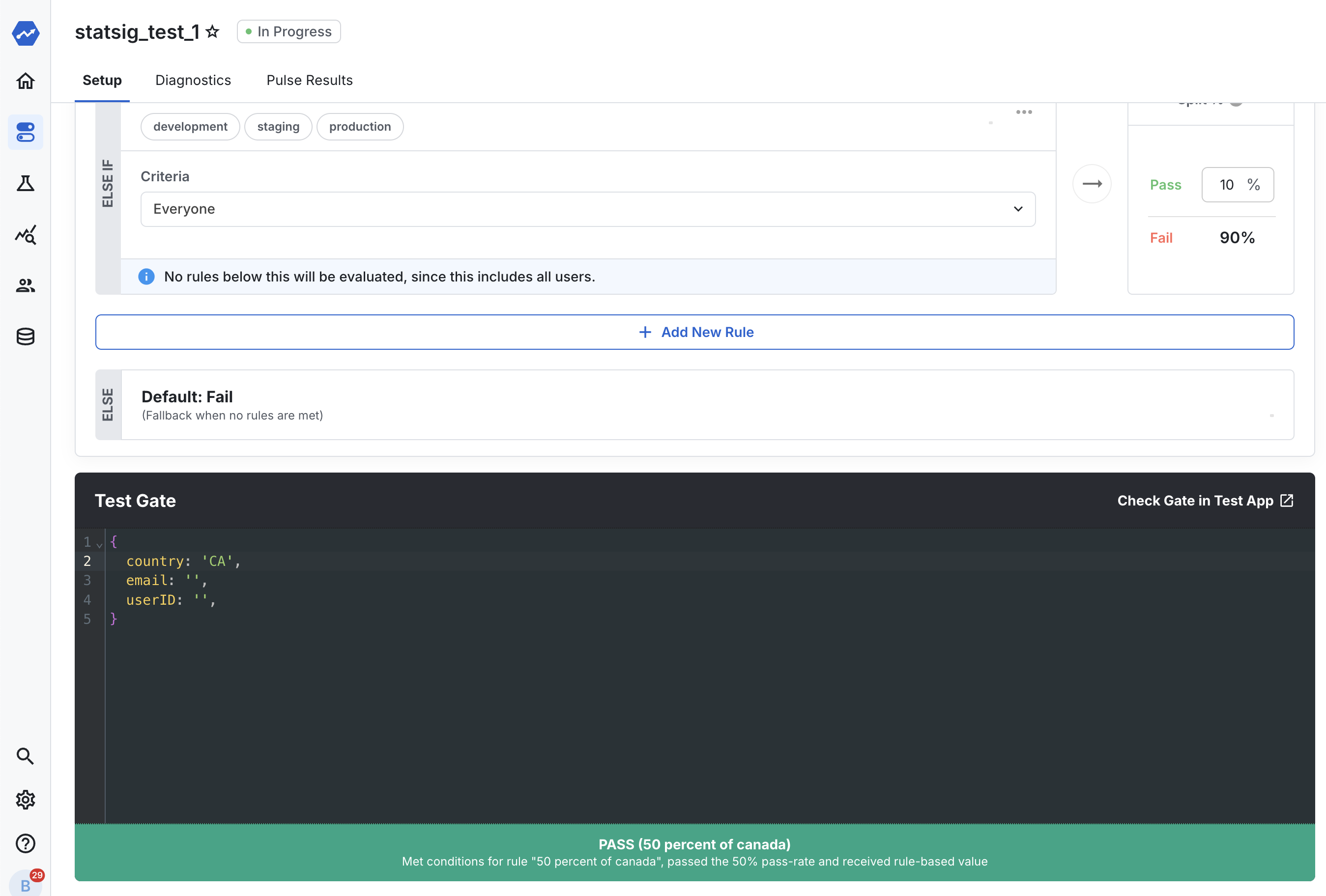
Debugging a user object: Stacking a bunch of rules in a feature gate can get complicated. It can be hard to know which rule your user landed on, especially if you’ve implemented advanced functionality like IP -> country resolution and user agent parsing. A simple UI to resolve a user to the rule they should hit is priceless for debugging. If you set up hashing by seed properly, the user should evaluate to the same thing in this tool as they would on the frontend, every time.
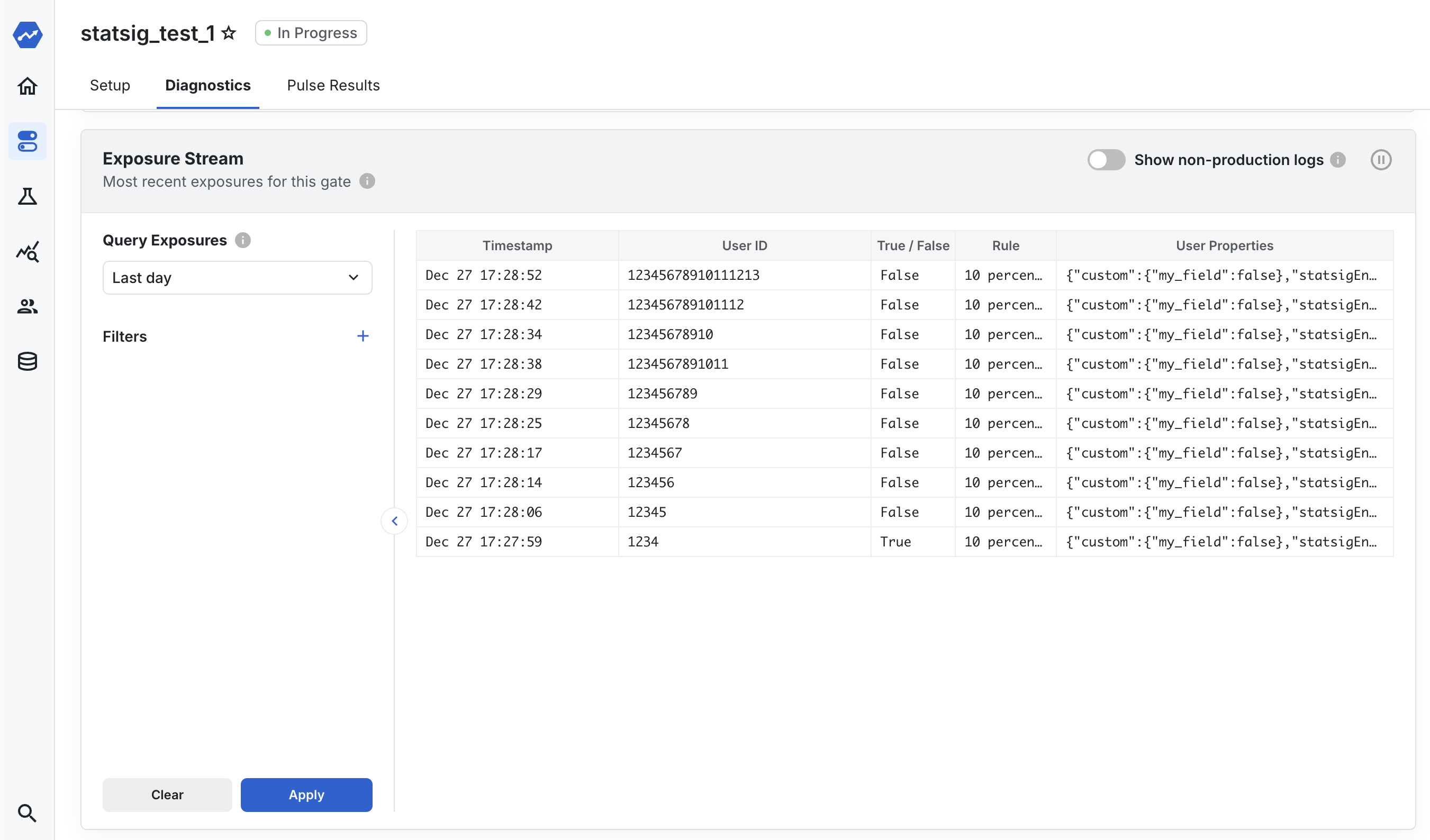
Debugging via actual evaluations: When you launch a feature to thousands or millions of users, feature flags can add a level of uncertainty when you’re adding rules and randomness to what users are seeing. A strong additional functionality for debugging this is real-time feedback on which variants users are being assigned to. This isn’t trivial, it requires the construction of SDK-side logging infrastructure (discussed in the next section in detail) to send an event to the server on every assignment. But this functionality can be table-stakes for monitoring your users, and when combined with debug information from the SDK, can provide aggregated insights on if your flags are executing properly.



A/B test analysis
(You’ll hear Statsig’s internal bias come out in this section.) But if you’ve got here, you’ve done all of the work to set up robust bucketing infrastructure—why not measure how users behave in each bucket?
This isn’t just providing analysis on simple things like copy changes, but also substantial feature releases and canaries where you aren’t sure the impact it’ll have on users. This also isn’t trivial: you’re signing up to log not just exposures to each variant, but also metrics about each user group’s behavior (discussed in detail next section).
On top of that, you’ll need to build a data pipeline that joins exposures to each variant (by userID) on user metrics, and display it in a way that’s both understandable and capable of further analysis and breakdowns. Many internal flagging platforms are used for this, but it isn’t always well-integrated, sometimes analysis is performed ad-hoc by data scientists, rather than automatically by a data pipeline.
Team management
If you’re looking at building an in-house platform—let’s suppose you have a sizable team of engineers using your platform internally—you’ll likely need to layer on features to segregate their work from one another, for performance, privacy, and usability benefits.
For example, if the teams using your platform end up creating thousands of flags each, not only will the usability of the UI degrade as they are flooded with content from other teams, but performance will degrade too, as each team will likely be downloading one another’s flags each time they initialize their SDK.
Creating teams and segregating features by them (or by a separate divider, in Statsig this is called “Target Apps”) becomes worthwhile. Having the ability to reduce repetitive work by putting together templates for each team can be handy, too.
Bonus features
Non-boolean returns
One feature that developers love is returning non-boolean values from feature flags.
If you can return Strings, JSON, etc., you can enable a whole new set of use cases that can speed up your team’s ship speed. You’ll have to take on a little bit more complexity here, as it's possible that serving JSON and other large configuration values can strain your infrastructure, and you’ll also need to build compatibility into the SDKs you write.
You may also want to write methods with strongly typed returns on your SDKs.
Streaming
If the time-to-propagate of your feature flags is an important constraint, you might also consider building streaming into your client-side SDKs.
In typical setups, your values are only refreshed at specific times defined by how you set up your SDK—sometimes when your page first loads or your app is first opened. This means using a feature flag as a “kill switch” isn’t always literal, and it might take until that next refresh for the feature to actually go away on client devices.
Streaming changes from the server down to client devices solves this, at the cost of some engineering complexity.
Reusable rules
In all likelihood, your developers will find themselves defining the same rules frequently across all of their feature flags. For example, if you’re rolling out AI products these days, you’ll find yourself excluding the EU frequently, due to regulatory requirements.
It’ll be handy if you can file the rules that you use frequently into one object and reference it across gates. In Statsig, this is called “Segments,” and they can be used in both gates and A/B testing analysis.
Summary and recommendation
All of these features are at most "nice-to-have"s, but this is another section where it's worth polling your future users for what they'd most like to see in your platform. Successful platform builds require a lot of buy-in from users, and the nice-to-haves can make a difference there.
Who does what?
Curious what you'd be getting in the market? Here is our gameboard, with the features of each provider you can find in the market filled in:

Implementation
If you've made your design decisions, it's time to get to nuts and bolts. In this section, we'll share what we've learned implementing and scaling a feature flagging platform across the UI, SDKs, and Infrastructure.
Building the UI
Managing Complexity
Feature flagging systems often end up with sprawling complexity. The power of feature management tends to end up integrating itself with product analytics, QA, and A/B testing, of course. At Statsig, we've had to refresh our UIs several times when customers complain of the increasing complexity.
We've noticed it most in:
Defining feature gate rules of various types, plus combining, reordering, and reusing them
Managing varying priorities and making the UI "for everyone:" Some customers would prefer our experimentation product be front-and-center, while others would prefer our flags be
Managing the mass of information that makes debugging possible: A comprehensive view of the debug info you need is rules, exposure logs, and version history of a config—all of which consume additional valuable real estate
We suspect most internal builds will follow a similar path that we've seen at Statsig:
You start with a simple, elegant product
Your customers make continuous, bespoke feature requests - which you deliver on
Your product becomes unwieldy, and you have to overhaul your design paradigms
(return to step 1 and collect $200)
While it's worth being aware of this pattern and attempting to break the cycle, a more practical approach may be to accept your UI will be ever-changing, and resource to overhaul it in the future. While it'll require more effort in the long-term, it's likely your program will be more successful when you continually take your users' feature requests.
Searchability, sharability, and general usability
While the success of our product at Statsig may not always be 1:1 with the success criteria for an internal platform, we certainly share one high-level goal: we want our users to feel comfortable and motivated to use our product, and spend meaningful time using it. Usability and ease of navigation contribute to this, as does integrating with tools you use alongside your feature flag provider: your productivity stack, CI/CD tooling, and more.
Earlier we touched on some basic usability tactics like team filtering. A couple others we've embraced at Statsig are powerful global search, highly usable list views, and sharability.
Global search was our most recent addition and might be the most valuable: often when you visit Statsig you know exactly which flag you're looking for, and global search makes it only a few clicks away.
Most commercial flag providers, Statsig included also have powerful list views: today you can use ours to sort by creator and owner, see the most recently created or edited, and see at a glance which are actually being used.
Lastly, we've found that flag usage is surprisingly collaborative, so shareable flag links can be a nice touch.
Integrations are another interesting feature to consider. Across internal and commercial builds, we've seen them span everything from your IDEs to task management to Github.
In IDEs, commercial flag provider integrations often provide the opportunity to view the state of flags in your code, and jump straight to them in a dashboard. Some providers have also provided integrations that make it easier to actually add the flags.
In a similar vein, tooling that lets you locally toggle flags while testing (rather than in-code overrides) can also be helpful. Vercel provides this functionality through its toolbar. Task management integrations are usually pretty simple, offering the ability to link a flag and show its status for a given ticket in Jira or Linear.
GitHub integrations are also simple but high utility. A common feature is finding all codebase references to a feature flag linked right from that flag, or integrations of Github actions with flag states.
Building great SDKs
The customer of every flagging platform is developers, and one way to lose developers quickly is by making their coding experience clunky or confusing. A few principles we've seen in flagging tools loved by developers: They're ergonomic, well-tested, and well-documented.
What are they, actually?
In short, SDKs turn the experiment values you've set up in your UI into in-code values.
This might feel like a small job but it can involve a lot more. Network requests, parsing rulesets, caching, and logging exposures are all in the SDK's job description.
We described a bit of this above, but here is the lifecycle of an SDK:
The SDK is initialized. In code you likely provide it with an SDK key, using which it pulls down the latest values from the server. Depending on your ruleset vs. computed design decision we described above, and if you're on a client or server, you might pass a user to the server, that you'd like to get values back for (more secure), or you might just request all rules, and tests a user for them locally.
You check a flag. The SDK grabs the latest values from memory, and either returns them immediately (in computed SDKs) or computes the correct value on the spot (in ruleset SDKs). Now, the SDK should also track an exposure to let you know who saw that flag.
You flush exposures. The SDK sends all of the exposures to those flags, plus any other log events you've set up, to the server.
It gets a lot more complicated than just this. Statsig's first javascript-client library (which we admittedly let get a little bit bloated before rebuilding it,) has a whopping 79 top-level methods. You won't just end up with checkGate(), but also getGate(), overrideGate(), and getGateWithExposureLoggingDisabled().
Ergonomic
If you're a developer excited to get cracking on an internal flagging platform, brace yourself. Here is where you might need a PM, or at least need to pull out your product toolkit.
Ergonomic feature flagging SDKs anticipate developer workflows and provide features to deliver on those before anyone asks for them. While a great feature flagging platform can be understood with a quick glance of the docs, an even better one can be understood solely through typeahead.
A few tips we have from building Statsig, and that we see across the industry:
Make things consistent and guessable.
getFeatureFlag()is a great method name.getTreatment(),getVariation(), while concealing valuable deeper functionality, prevent easy typeahead and delightfully quick adoption.Make things as flexible as possible. So often, developers want to turn a feature flag into an A/B test without waiting for a deployment structure. Truly ergonomic SDKs will allow for this on the backend.
Advanced functionality that fits developer needs: We won't run this to ground as every workflow looks different, but each team will need features that make this system ergonomic for them. Do you need to run programmatic tests on flagged codepaths? You'll likely need a way to override feature flags locally. Need a way to make sure users never see false if they first see true for a flag, or vice-versa? You'll need something like sticky bucketing.
Documented
Unless you want the valuable time of your platform team to be spent educating users, you'll likely want to invest in thorough, easy-to-consume documentation.
Great docs should usually contain, for each feature:
An overview of the motivation, or why you'd use something
An in-depth technical guide to using it (with thorough code samples), and
Guidance on what to do next, like which features to use next, or what else needs to be setup. This task can balloon quickly, as you'll also want to do step 2 for each language or environment you're supporting.
While we have no sage advice for how to make doc writers' lives easier, a couple things we feel strongly about are to:
Have our engineers write docs, and
Not reinvent the wheel when it comes to docs.
On the first, it's important to remember that this is a product for developers. Their time is valuable, and it's worth any platform team's engineers taking the time to build empathy with their customers' needs, and writing docs for those.
And to the second point: we use docusaurus for docs writing, and have heard positive things about Mintlify. In our opinion, it's worth using something built for docs, but not boiling the ocean with something homegrown.
Tested
Something we learned early on in building SDKs across 20+ languages is that building a unified testing framework for all of your functionality (across languages) is well worth the investment.
This effort has a dual payoff: it substantially de-risks SDK code releases—especially where we found layered logic is likely to cause frequent unforeseen issues—and also ensures that the behavior of your SDKs is consistent across every language you provide them in.
At Statsig, we have a framework that creates an environment in each of our 20+ languages that we can write typescript tests directly against, meaning we only have to write tests once for each new feature, rather than in 20+ languages and testing frameworks.
Building great infrastructure
Earlier, we alluded to a few design decisions that have a substantial impact on your infrastructure, whether you choose to have ruleset or precomputed SDKs, and if you choose to build logging infrastructure. These make a substantial difference in the infrastructure you'll have to build, but no matter what you choose, you'll still be wrestling with the same issues: uptime and consistency.
Overview of what you're building
Depending on the design decisions you've made, there are at most three components to a great feature flagging infrastructure: the first, which every build will have, is an API that serves rulesets. The second, which most builds will have, is a "computed" values API. And the third—if you choose to have it—is event logging infrastructure.
No matter which you choose to invest in, reliability will be your main goal, with outages of each piece having different consequences.
Building a ruleset API
At its simplest, a ruleset API is a way to accurately represent the feature flags you set up on your console, in a way that can be read for any user by your SDKs.
We shared a snippet above of what the Statsig ruleset looks like for a single feature flag with three targeting rules. In short, it'll be a list of rules that your SDK is responsible for turning into values, for any given user.
Rulesets are usually JSON, and assembling them consistently in a structure compatible with all of your SDKs is (obviously) critical. This needs to be a somewhat performant service as well, if you expect changes to your ruleset to be frequent.
Commonly rulesets can be served on a CDN, so long as you're willing to invest in the necessary mechanisms to break caches when a ruleset becomes out of date. This provides a nice cost-benefit, if you're cautious of your server and egress spend, and makes ruleset retrieval faster.
Of course, this is a critical piece of infrastructure. If this ruleset SDK ever goes down, the servers and clients running your SDK won't be able to receive updated values, and in many cases, will outright fail. Built-in redundancy across regions is a must.
Building a computed values API
A computed values API takes ruleset and a user and turns it into the values (trues and falses, at the simplest) for that single user.
As we've said a couple of times, most client-side flagging implementations choose to use a computer values API for privacy: Would you really like people to see who fails your black_list_these_emails feature flag?
If you've built out a great ruleset API, and great server SDKs, then building the simplest version of a computed values API could require only a little bit of effort on top of that.
As a server SDK returns values for any user (on the server side), you can simply turn this server SDK into a service that can send those values down to the client with the proper authorization. Of course, you'd want it to be pretty optimized and efficient, as it's not out of the picture that you'd receive dozens of requests to this API for each DAU when they're using your platform.
Building logging infrastructure
Logging infrastructure accepts requests from your SDKs, either telling you that a user has seen a particular feature flag, or logging other important product events, that can then be linked into A/B tests or feature rollouts, processes them, and stores them in a friendly, usable format—often somewhere like a Data Warehouse.
Statsig and ByteByteGo recently collaborated on an article explaining how Statsig streams more than 1 Trillion events per day in our logging infra. While we'd encourage you to read it as a soup-to-nuts primer on best practices, a few takeaways:
We separate "reordering" and "processing" events, with the focus of the recorder being on ensuring no events are ever lost, and the focus of the processor to apply refining logic to events and getting them ready to use.
We have a message queue layer that uses Pub/Sub and GCS (object storage), with Pub/Sub passing around pointers to data in GCS (rather than moving such an enormous amount of data itself, which would be costly).
The final service is routing, which sends our data wherever it's needed. Most relevant to this article, much of it is sent to our data warehouse, BigQuery.
Logging infrastructure's difficulty is typically cost. If you're building a high-volume service, you can end up with a volume of events that end up expensive based on Load Balancer or Ingress costs alone.
Depending on how you use your data, reliability will be key here too, as A/B tests are commonly run over several weeks, and Data Scientists tend to be picky with discarding results when data has been dropped or lost.
Made it this far?
If you've read this blog up to this point, you're probably pretty serious about building a feature flagging platform. The last thing we'll leave you with is a view of how much effort something like this is.
Statsig signed its first customers about a year after we started out, meaning it took us about 10 engineering years (we had ~10 engineers in that first year) to build something good enough that even one customer was willing to take a chance on us. Building a great platform is an investment measured in years and millions of dollars.
Statsig is now into the multiple hundreds of engineer-years spent building our platform, which now goes far beyond feature flags and includes the industry's best experimentation, a full-fledged Product Analytics platform, and more.
If 8000 words later, you'd entertain buying, rather than building, a feature flag platform, we'd love to chat. Don't hesitate to book a call with us!
If you think we've missed anything, we'd love to hear your feedback in our community Slack. Feel free to ping me there.
Request a demo
