Products
Solutions
Resources



When building LLM-based apps, managing LLM inputs across your code base can be annoying.
You don’t want to have to copy and paste the different prompts + parameters you’re using every time. Plus, if a new model comes out, it would be nice to upgrade to the latest model with a single change.
Fortunately, it’s easy to use Dynamic Configs to store model inputs. This lets you control the LLM calls you use from one central system, and makes it easy to run experiments with different models (if you want to).
Below, we’ll walk through this process step-by-step, using our Statsaid test app.
Creating a Dynamic Config
Your first step towards simplified LLM input/output management is creating a dynamic config within Statsig.
To do this, navigate to the Statsig console and select the 'Dynamic Configs' option. From there, you’ll need to create a new config.
Integrating LLM values
Once your dynamic config is set up, the next step is integrating your LLM values into it. This might sound complicated, but it's just a matter of mapping your LLM inputs and outputs to the appropriate fields in the dynamic config.
The beauty of this system lies in its adaptability. No matter the nature of your LLM data—whether it's derived from user behavior, system logs, or elsewhere—you can slot it neatly into your dynamic config and let Statsig handle the rest.
Here’s what we started with within Statsaid:
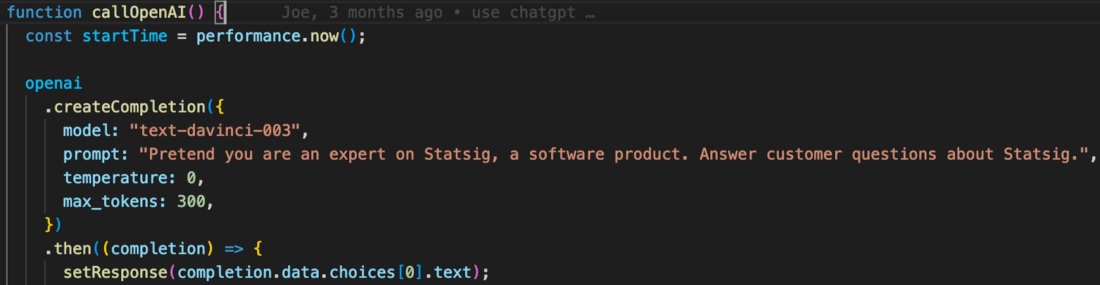
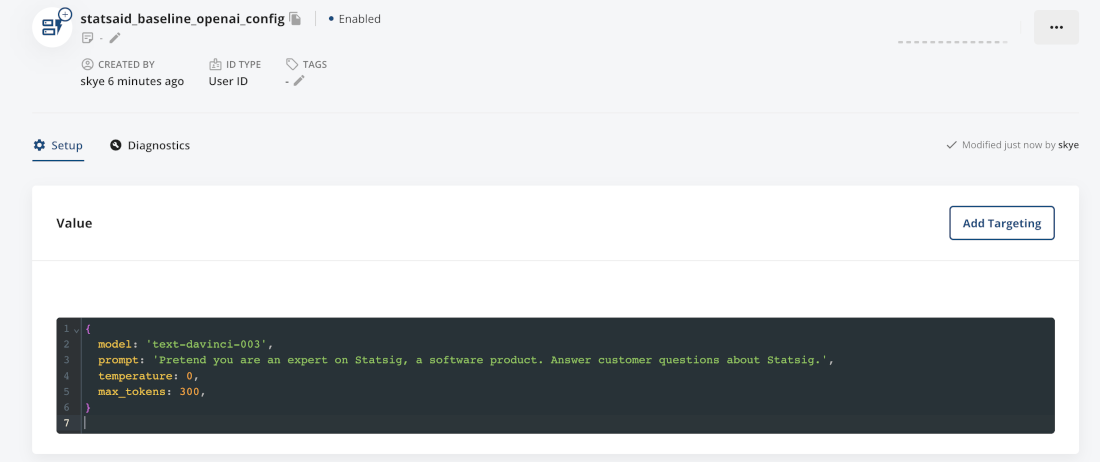
We’ll take the core inputs (model, prompt, temperature, and max_tokens) and map them to our dynamic config.
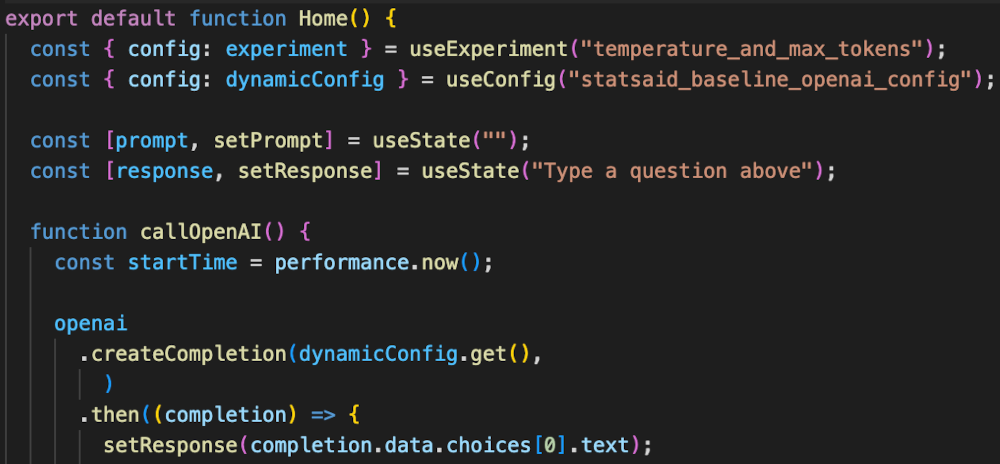
Finally, you need to call the config in the area of code that you’re running. Since we’re running this in a nodeJS app, we need to first pass the value of a config to a variable, then pass those to a function.
That’s it! You’re ready to roll. Any changes you make to the config will be reflected in your application—including adding or removing parameters.
If you want to swap to a different config, you can find + replace the existing config reference in code.
Doing cool stuff: User targeting
Now comes the fun part: using your dynamic config to do cool things—like user targeting!
In the case of Statsaid, you’d just have to add some targeting rules to the dynamic config. Let’s say we see an influx of French users, and we want to add a target so that anyone who loads our app in French gets a French LLM response. Obviously, you’d want to translate the app fully, but this is a fun example.
To start, you’d add a rule that targets users in France. All other users would be routed to the English version.
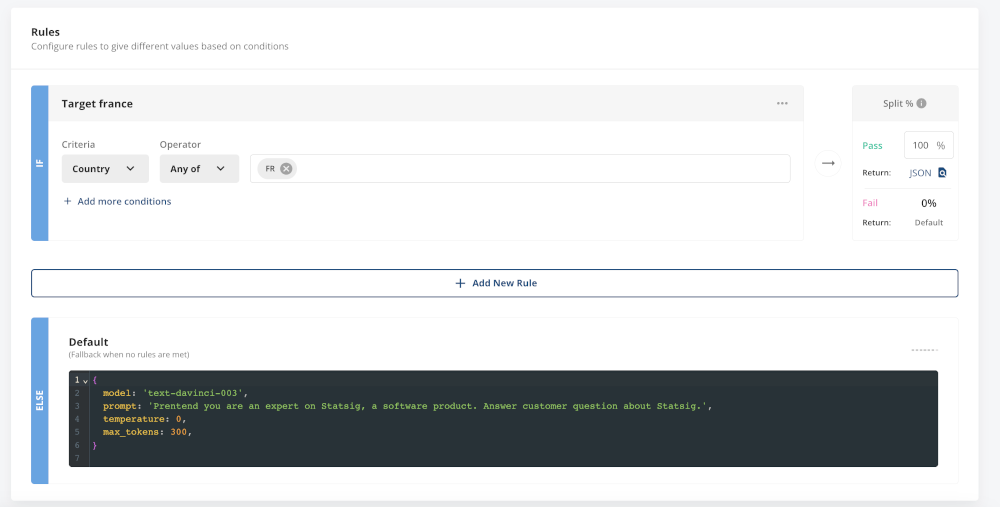
Then, you update the JSON value that’s passed to users in France. In this case, we’ll keep the same prompt, with a short edit to translate the output to French.
Boom! You’ve localized your LLM inputs. Now to add the rest of the world…
Clean configs
Using configs to store LLM call parameters makes it way easier to run these sorts of tests or experiments. Plus, it cleans up your code. What’s not to love?
If you’re ready to start your config journey, sign up for Statsig! We have a generous free tier, plus an awesome startup program. Learn more below.
Get a free account
