Products
Solutions
Resources


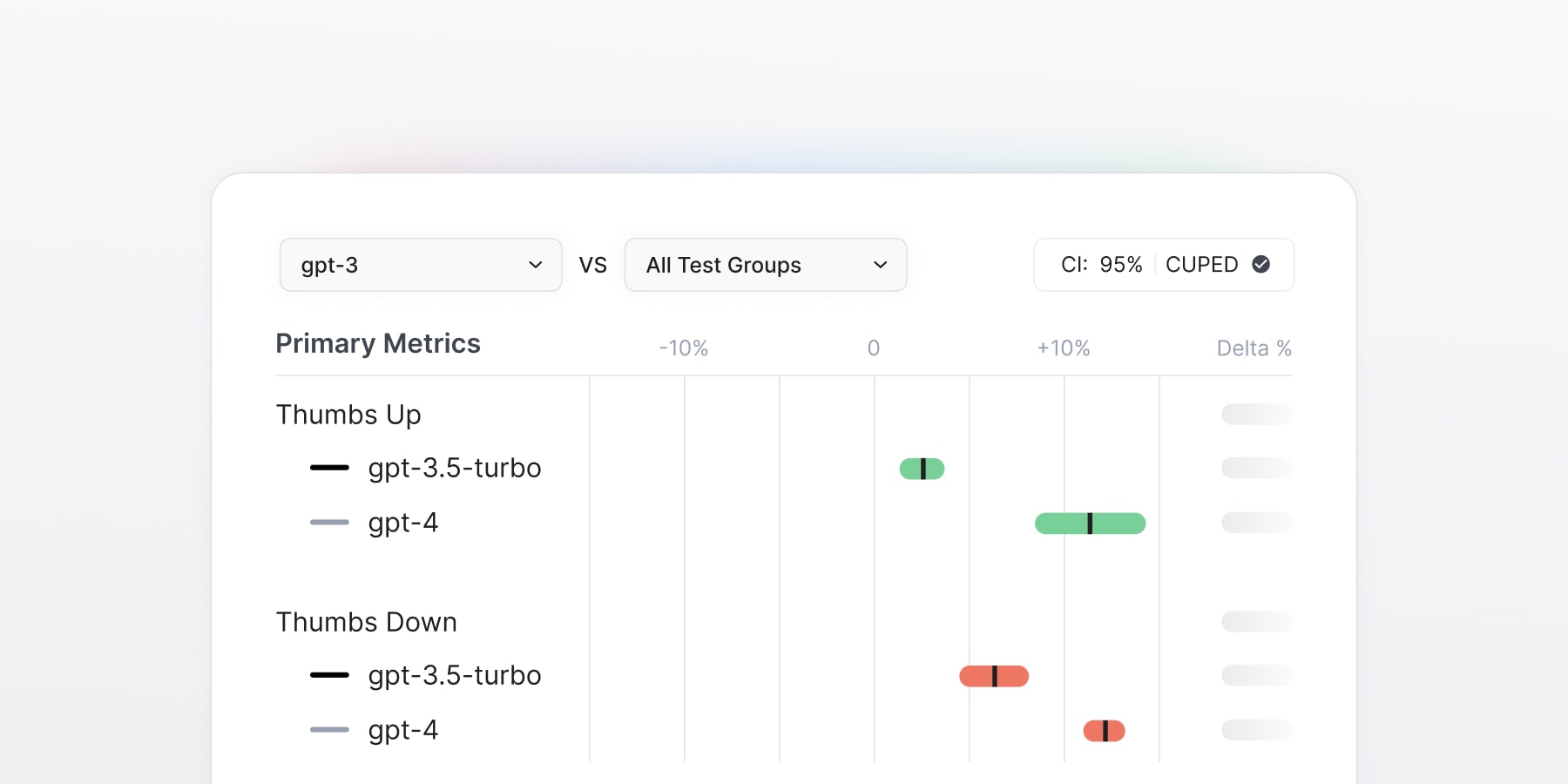
At Statsig, we’re lucky to have a front-row seat to how the best AI products are being built.
We see first-hand how our customers rely on experimentation to improve their AI applications — not only OpenAI and other leading foundation model providers, but also world-class product teams building AI apps like Figma, Notion, Grammarly, Atlassian, Brex, and others.
It’s not an exaggeration to say that every leading AI application relies on systematic A/B testing to test, launch, and optimize their product.
The issue with this statement is that it’s… boring. The power of systematic experimentation and A/B testing isn’t a secret. It’s been a core part of the modern product stack since the early 2010s — and that hasn’t changed with AI.
Now, as AI takes on more of the “build” in the build > measure > learn loop, measurement, optimization, and iteration become even more critical.
We've noticed some particularly interesting trends in how traditional experimentation is evolving to support AI development.
Trend 1: Offline testing is being replaced by evals
Traditionally, AI/ML testing focused on training custom models designed for specific tasks. Specialized research engineers were deeply involved from ideation through development, testing, and deployment—a process that could take months or even years to complete.
This version of offline testing was very academic. Researchers would test the model against various statistical tests and benchmarks (perplexity, F score, ROUGE score, HELM) to assess its performance for a given task.
There was also a heavy emphasis on data preparation and processing; training data had to be carefully prepared and split into training, validation, and testing sets which were used throughout model development.
After all this testing, models would be evaluated with human feedback, then shipped in production as an experiment.
As teams are starting to build with foundation models (rather than preparing their own models) a new paradigm for offline testing is emerging: offline evals.
Evals work by preparing a set of representative inputs - like a set of user questions or prompts - and run them through a test version of an LLM application. Engineers or PMs review the outputs for each version, and see which ones look better, then ship the version that seems to work the best.
| Input | Output (version 1) | Output (version 2) | Output (version 3) |
|---|---|---|---|
| What's the square root of 4? | 3 | 2 | Potato |
| What is sequential testing? | Running A/B tests one after another, but without tracking results | A method where results are evaluated continuously, allowing for early stopping based on statistical thresholds | Testing if your sequence of Netflix shows is fun enough |
| Where was Statsig founded? | New York City | Bellevue, Washington | The moon |
Usually, the results don't show such a dramatic difference - but systematic evals do reveal subtle differences in the outputs from different combinations of inputs - like prompts, models, context, and more.
This is a very effective way to get a sense of which changes work best. Unfortunately, this process is still slow and often requires a “test” version of the app built specifically for running evals.
These test apps may also lack critical components of the user experience, like context from previous chats, UI elements that contribute to the session, and other components that can interact with changes to a prompt or model.
Increasingly, teams are using a production version of their application to run offline evals - using logging to store outputs to different inputs, or just testing a few inputs manually. While this is inevitably results in fewer samples, it allows product teams to see a representative prototype in action.
Once they have a version that they feel good about, they just ship the updated version as an A/B test - giving them real signal from users on how it’s performing. This also gives data on how changes affect other aspects of application performance, like cost and latency.
Last month, we developed an automated workflow (available in Alpha) that lets you quickly make changes to prompts and models, test against an evaluation dataset, and ship to production as an experiment.
We’re leaning into this trend with a new set of tools that link offline evals and online experiments. Lots more to come here soon!
Trend 2: More AI code drives the need for quantitative optimization
Every company is using AI to write code. While the stats vary - Microsoft says 1/3 of code is AI-generated, and Anthropic recently said nearly 90% of their code is AI generated.
As this trend continues, the need for quantitative optimization of application performance is going to increase massively.

First, as engineers ship more AI-generated code, they need a way to catch bugs, performance degradations, and other potential issues. To do this, you need two things:
Good logging on all the product metrics you care about
The ability to link these metrics to everything you release
Second, systematic experimentation paired with tools like product analytics and observability is the only way to scale this effectively.
We’re seeing more and more customers leaning into this trend: using AI to build new features quickly, testing them in production behind a 0% feature gate to ensure there are no unexpected interaction effects, and launching them as an A/B test to make sure they have a positive impact on product performance.
As agents begin to ship new features themselves, teams will need to a way to manage their work - and ensure it’s moving the product in the right direction. Again, putting changes behind a feature gate and running A/B tests is the single best way to do this.
Our team is using Devin in this exact way. We feed Devin customer requests or support tickets, ask it to find and fix the bug, test it in a dev environment, then wrap the update in a feature flag, add relevant log events, test in prod, and finally deploy it as an A/B test. This process allows us to use AI to turn requests incredibly quickly, without compromising safety or polish.
We’re adding capabilities that enable anyone to use us in this way, such as the Statsig MCP server that helps agents create gates or experiments independently, and additional tools for developers building with AI (like Cursor rules).
Trend 3: Every engineer is a growth engineer
Today, engineers can focus more on the impact of their work rather than the heavy lifting of building features. As LLMs write more code, the marginal effort to ship a simple idea drops to zero. That means you can test far more ideas, faster.
In classic SaaS product-led growth playbooks, teams tested different drivers of “aha” moments — like Notion or Canva offering readymade templates in the new user flow.
Now, with AI, you can try 10x more ideas. The challenge shifts from building features to identifying which ones actually move your product and business metrics. Every engineer, even non-technical stakeholders can be growth engineers now!
Example: It has become common for chat interface-based apps (like ChatGPT, Vercel V0, Lovable) to experiment with suggested prompts to help users quickly discover and realize value, which subsequently drives engagement and retention.
Even at Statsig, AI isn't just changing how we build products, but also how we drive growth. For example, we built an AI onboarding agent that lets you add Statsig to your React project with a single command. We’re continuing to improve by testing features like OAuth support to make the developer experience smoother and reduce time to value even further.
Trend 4: Product value comes from your unique context
As foundational models improve at generalized intelligence (get you to 80% of the solution), your differentiated domain knowledge, understanding of user problems, and surfaces to apply AI will make all the difference.
Which is to say - incorporating AI into your product isn't as simple as plugging in an off-the-shelf LLM. You need to make it more useful with the right context, data, and understanding of users’ workflows.
Take the case of Grammarly vs. ChatGPT. ChatGPT can certainly produce high-quality grammar and language writing. Yet Grammarly has built a $700m+ ARR business that continues to grow by focusing on productivity use cases.
They've built integrations where people actually write (making it real-time), style guides, strategic suggestions based on proprietary writing samples, faster ways to incorporate these suggestions, and more.
It’s easy to build an AI application, but making one that’s actually useful is a different story. You need a lot of A/B testing to optimize your product and make the user experience seamless.
Today, thanks to MCP servers, it has become easier for your product’s novel context to be integrated with AI. This means more than ever, you need to focus on testing and optimizing your models, prompts, and datasets to deliver real, differentiated user value.
And as we move toward an agentic world, agents need experimentation too!
Agents are complex, multi-step systems that often execute a large number of tasks. That makes them perfect candidates for online experiments: change one component in a single node, and you might see significant downstream effects on key metrics like performance, cost etc.
If you’re interested in partnering with us as we build experimentation tools specifically focused on optimizing agents, please reach out!
Request a demo

Closing thoughts: AI is part of every product
Gone are the days when there are non-AI products and AI products. Today, every product has AI embedded in it. This means that testing and optimizing AI applications is important for everyone - not just a few companies based in San Francisco.