Products
Solutions
Resources
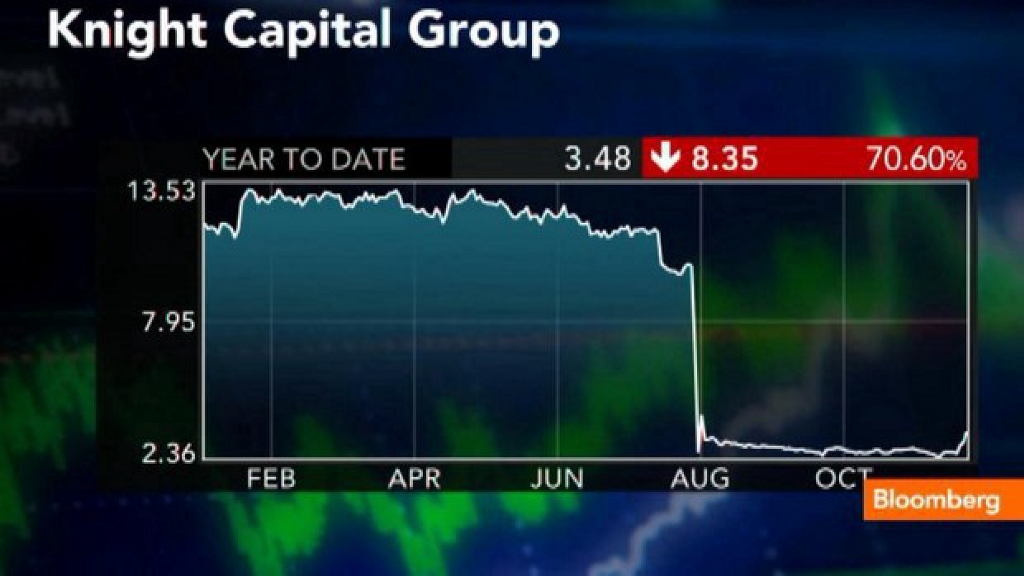
The demise of Knight Capital
Knight Capital was the largest trader in US equities in 2012 (~$21b/day) thanks to its high-frequency trading algorithms. They also executed trades on behalf of retail brokers like TD Ameritrade and ETrade.
Their demise came in 2012 when they developed a new feature in their Smart Market Access Routing system to handle transactions for a new NYSE program.
To control this new feature, they repurposed a feature gate created for a different trading algorithm called “Power Peg”. Power Peg was never meant to be used in the real world to process transactions. It was a test algorithm, specifically designed to move stock prices in test environments to enable verification of other proprietary trading algorithms.
Unfortunately, when they deployed this new code, it succeeded on seven of eight servers. Without realizing this, they flipped the feature on. Code on seven servers worked as expected. The legacy Power Peg feature came online on the eighth server and started executing trades routed to that server.

In a few minutes, Knight Capital assumed options positions worth $7 billion net — that resulted in a $440m loss when closed. With only $360m in assets, this made them insolvent; they had to be restructured and rescued by a set of external investors.
This proved to be a very expensive lesson in managing dead code and creating unique, well-named feature gates. Feature gates are cheap to create, never reuse them! Read more about the Knight Capital saga here, or check out unlimited feature flags in our free tier at Statsig.
Do you have a horror story with using feature gates? I’d love to hear from you!