Products
Solutions
Resources



Feature flags and experiments are indispensable tools in the software-building toolkit—but for different reasons.
Feature flags act as the straightforward gatekeepers of deployment, offering a choice—on or off—for introducing new features. Simplicity is key here.
Experiments, in contrast, help navigate complexity, offering detailed insights into user behavior and product performance through rich, data-driven feedback.
While these two tools are inextricably tied together, we're committed to providing the flexibility to use feature flags and experiments both individually and in tandem, because maintaining clear separation between these two mechanisms—not merging them into a completely singular structure and process—is a key ingredient to a healthy coexistence between experimentation culture and a fast clock speed.
This is something we’ve learned from firsthand experience, which is why we handle feature flags and experiments differently, in order to provide maximum value for each.
They’re fundamentally different, here’s why.
Feature flags, for shipping decisively
By providing a straightforward, binary choice—pass or fail—feature flags allow teams to centrally control features.
This clear-cut functionality is crucial for maintaining release momentum while being able to respond to feedback and market demands quickly.
When a feature flag is purely boolean, deploying a feature becomes a matter of flipping a switch. There are no variables within the feature that must be altered or replaced.
Using feature flags that return multi-type dynamic configurations, however, introduces a layer of complexity that can obscure the path to full implementation: When the time comes to transition to full deployment, references to those dynamic configurations need to be replaced, introducing potential points of failure and delaying the shipping process.
This necessitates extra diligence and refactoring that could have been avoided with a simple boolean check. And, as we all know, teams may be slow to clean up feature flags.
This mountain of technical debt is how companies get trapped into using a provider; you’re essentially building a monolith of dynamic configurations hosted outside of your application.
Experiments, for seeking understanding
Conversely, experiments are the quest for deeper understanding.
They are not just about A/B testing atop a feature flag; they are a comprehensive exploration of user interaction, product performance, and all the factors that influence success. Experiments are where hypotheses are tested, where data is scrutinized, and where the unexpected is uncovered.
To put it bluntly, experiments are not just about whether a feature should be turned on or off, but understanding the why and how behind user behavior and product metrics.
The distinction between the two
At Facebook, our team lived through the transition from experimenting with just feature flags, to quick experiments. Our original feature flagging tool was called Gatekeeper, and we used it for every feature.
As the quick experiment tool evolved, and its experimental rigor increased which ultimately caused us to lose our ability to create simple A/B tests like Gatekeeper originally allowed.
The experiment setup flow had to include primary metrics, a hypothesis, statistical methodologies, screenshots of the experience, group and parameter configuration, etc.—all of the important features for running a successful experiment.
Gone were the days of quickly spinning up a new feature, adding a new flag to control access in code, and then shipping it that day so that you could start gathering data instantly.
Our cadence began to slip.
Back to basics
Quick experiments (which now did not live up to its name) slowed down our releases so much that a new tool was born: “Instant A/B.”
Instant A/B was literally just a button that would automatically configure the entire experiment for you, with just a simple boolean parameter for a quick A/B test.
There and back again.
Having learned from this experience, we understand firsthand the importance of keeping simple A/B tests quick and easy to create, while still providing rigorous experimentation options as well.
Thus, Statsig deliberately distinguishes between feature flags (for immediate action) and experiments (for deeper inquiry), which satisfies the conflicting needs of Product Managers, Engineers and Data Scientists, and so on.
The benefits of a unified platform
While distinct workflows between feature releases and experimentation is crucial, housing them within the same platform and using the same toolkit to implement them offers a multitude of advantages:
Centralized analysis and control
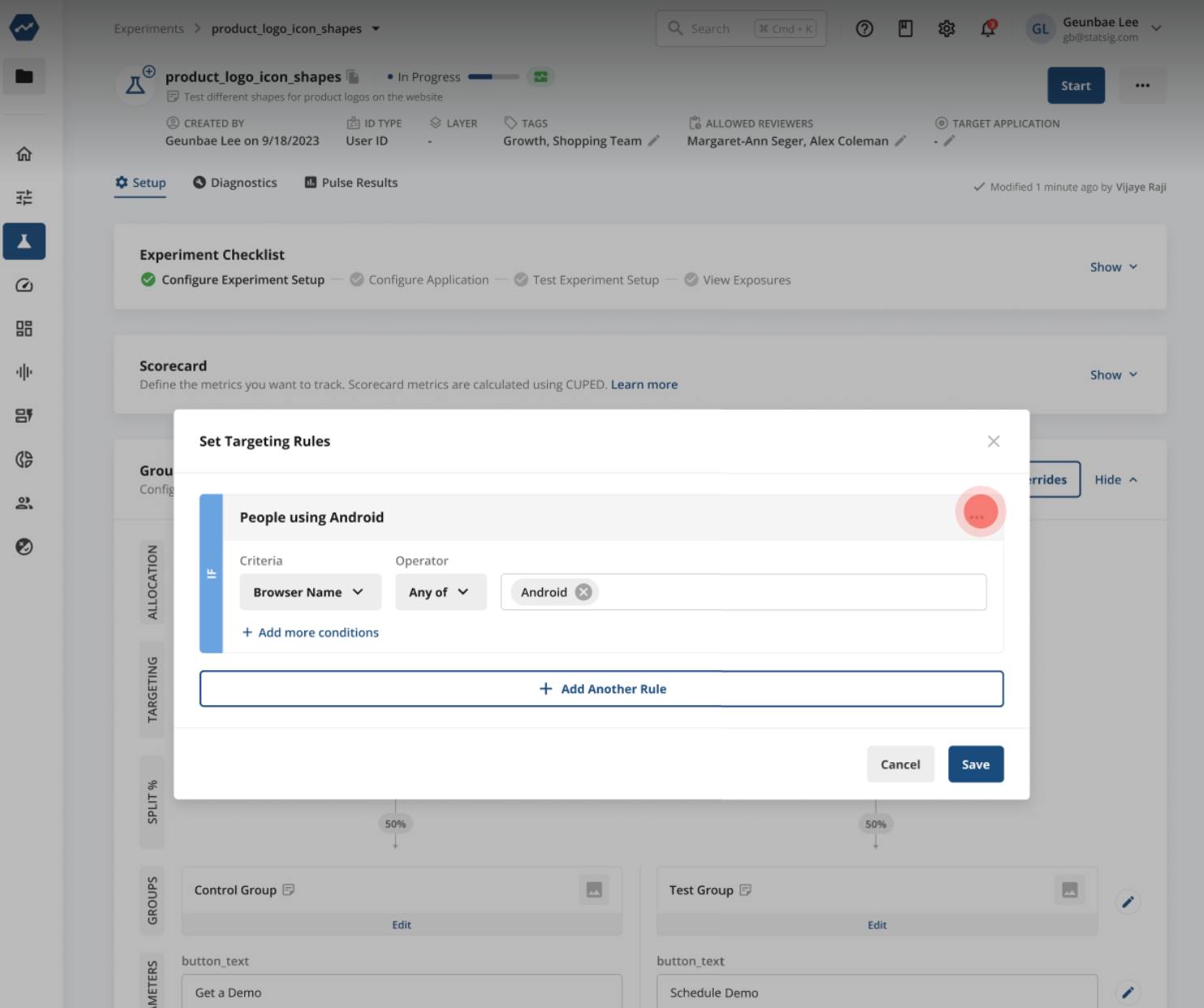
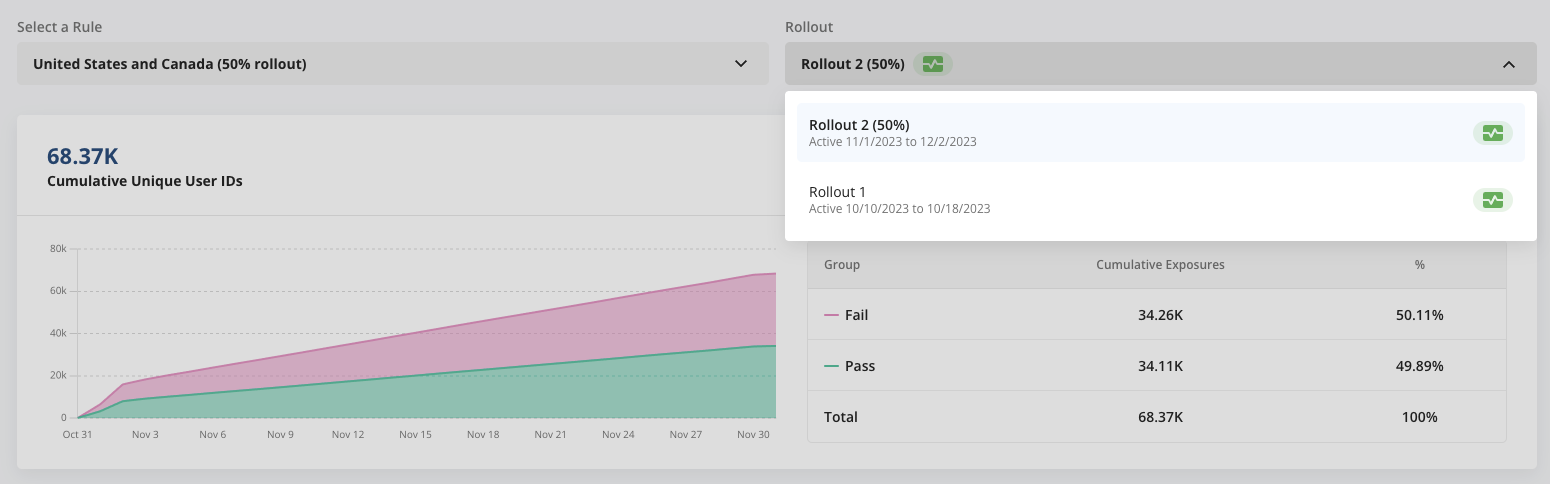
Having both tools in one place means interactions between features and experiments are automatically managed. This includes automatically applied global holdouts and other complex interactions that are cumbersome to handle with other tools. And although they’re separate concepts, it’s simple to add feature targeting to an experiment when needed:
Data consistency and real-time diagnostics
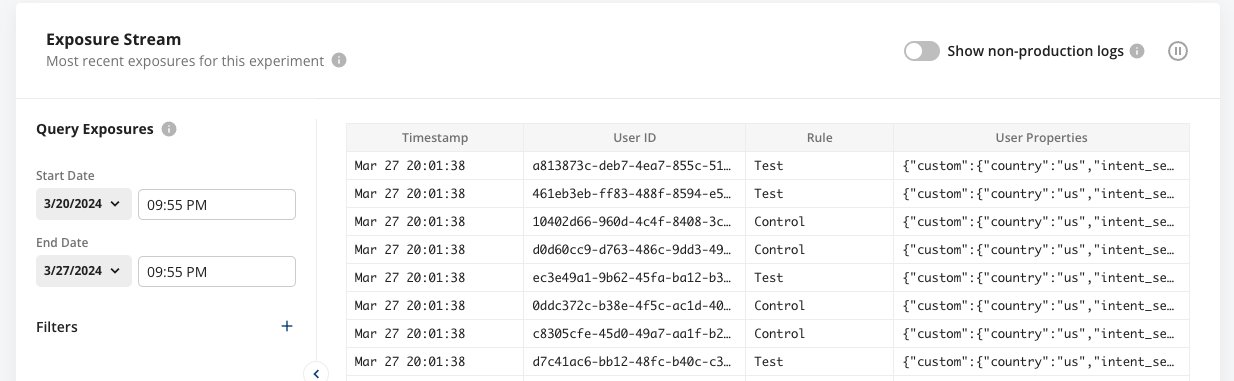
With Statsig, there's no need to juggle data pipelines or wait for insights. The console offers real-time diagnostics, ensuring that data discrepancies are a thing of the past.
End-to-end visibility
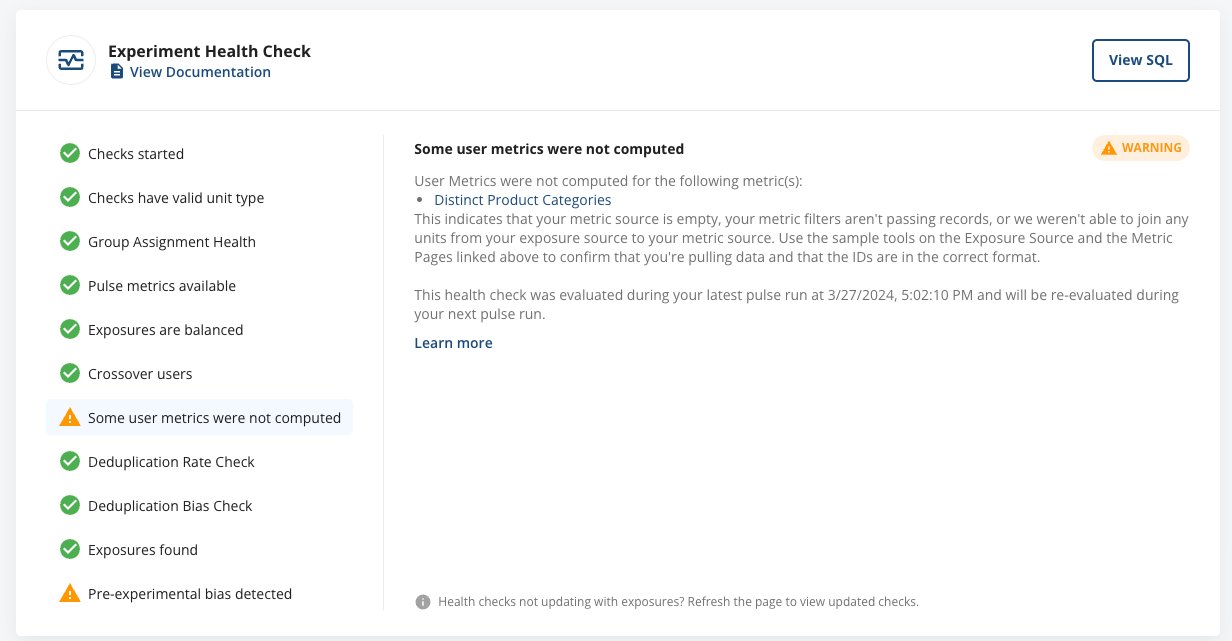
Debugging becomes less of a headache when all diagnostics are under one roof. This unified visibility fosters developer agility and reduces the complexity of troubleshooting.
Dual paths to discovery
Statsig's deliberate choice to allow A/B testing results in both feature flags and experiments opens up two avenues for discovery. Formal experimentation can coexist with a zero-lift approach for product and engineering to measure feature rollouts, fostering a culture and documentation of continuous learning and rapid iteration.
Our stance
The distinction between feature flags and experiments within a unified platform is an important one: They're fundamentally different, and should be used for different things.
More than a matter of convenience, this is a strategic approach that enhances decision-making clarity, accelerates the release process, and helps cultivate true experiment culture without slowing down development speed.
By embracing this philosophy, Statsig empowers teams to navigate product development's complexities together.
Request a demo
