Products
Solutions
Resources


You’ve got a problem on your hands:
You want to create processes that give autonomy to distributed teams.
You want them to be able to use data to move quickly.
You can’t compromise on experiment integrity.
What are you going to do?
Developing (standardized) processes that can scale experimentation without compromising quality is tough, and carries risk.
If things go poorly, you might inadvertently waste resources, dilute the quality of insights, and even lose trust in the experimentation process altogether.
Today, we’re going to highlight the features that enterprises like Atlassian, which have thousands of globally distributed engineers, use to scale experimentation in a controlled manner.
To accomplish this, they've leveraged the Statsig features that come baked into core product workflows, which allow standardization and adherence to best practices, as well as allow new users to ramp up smoothly.
Let’s spotlight some of those.
1. Templates
Templates enable you to codify a blueprint for config creation that fellow team members can use to bootstrap their own feature gates and experiments. If you have a standard rollout you want to leverage across a team or organization, you can easily convert it into a template so everyone can reuse the config with pre-filled values.
With templates, you can:
Create a new template from scratch from within Project Settings or easily convert an existing experiment or gate into a template from the config itself
Manage your templates all in one place within Project Settings, restricting which roles on your team have the ability to create and modify templates via Statsig's role-based access controls
Enforce usage of templates at the organization or team level, including enabling teams to specify which templates their team members can choose from
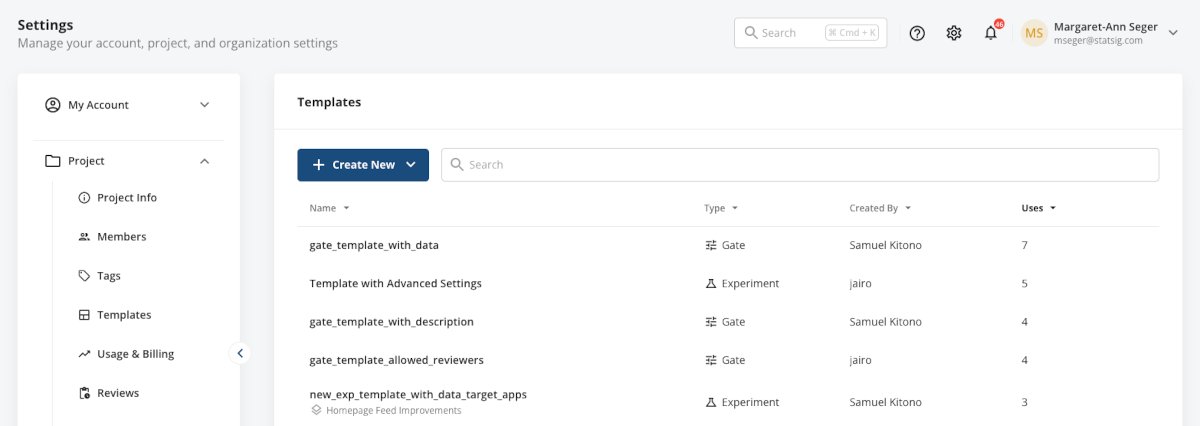
Read more about Templates in our documentation.
2. Teams
Given varying experimentation and feature rollout workflows across different teams, it often makes sense to enforce best practices at the per-team level.
Teams enables you to do just that:
Define a team-specific standardized set of metrics that will be tracked as part of every Experiment/ Gate launch
Configure various team settings, including allowed reviewers, default target applications, and who within the company is allowed to create/ edit configs owned by the team
Get a tailored Console experience, with listviews auto-filtered to your team(s) and Home Feed ranking tailored to updates from your team(s), not to mention easier search for configs that belong to your team(s)
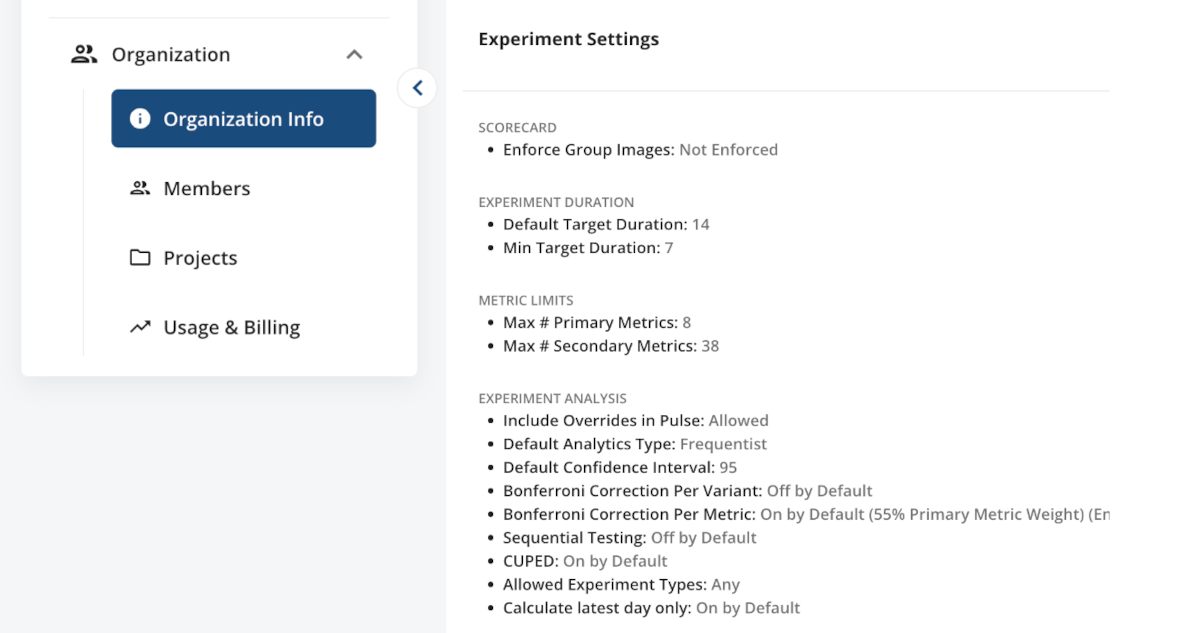
3. Experiment Policy Settings
Organization Admins can set defaults for new experiments and enforce these defaults to ensure consistency across all experiments in an organization. This allows you to tailor Statsig to your unique requirements while safeguarding against unintended misuse as more experimenters onboard.
Admins can set a range of parameters, such as default experiment duration, maximum number of metrics in the Scorecard, and statistical defaults like default confidence interval, enabling CUPED, and the use of sequential testing.
Setting new users up for success
While the above controls are crucial for enterprises, we still want to ensure that new users can learn quickly and self-serve when setting up their first experiment or feature gate.
At every step in the workflow, we have added features to make using Statsig within a large organization more intuitive. Consider 'Verified Metrics,' which help you build a centrally managed, curated list of trustworthy metrics.
This means that when a user is setting up an experiment, they intuitively know which metrics are trustworthy when they see the verified blue icon next to it.
When you consider such features along with our collaboration features discussed in a previous Spotlight—'Experimentation is a Team Sport’—you begin to see how Statsig goes beyond merely providing sophisticated tooling for running product experiments.
Rather, we are driving a cultural change, encouraging more users to run more experiments, faster, while still maintaining a high quality bar.
Get started now!
