Products
Solutions
Resources


Novelty effects, TLDR
Novelty effects refer to the phenomenon where the response to a new feature is temporarily deviated from its inherent value due to its newness.
Not all products have novelty effects. They exist mostly in high-frequency products.
Ignoring the temporary nature of novelty effects may lead to incorrect product decisions, and worse, bad culture.
Novelty effects are treatment effects. They should not be corrected with statistical methods.
The most effective way to find novelty effects and control them is to examine the time series of treatment effects.
The root cause solution is to use a set of metrics that correctly represent user intents.
When understood and used correctly, novelty effects can help you.
What are novelty effects?
Novelty effects are short-term effects in a product’s metrics that are attributed to the introduction of something new. In simple terms, something new will evoke a temporary reaction, which might wear off as the newness wears off.
When product decisions are made based on metric movement, it’s important to understand this phenomenon, so only the sustained impacts of product changes are considered.
Novelty effects are not bad and are actually sometimes valuable.
Considerations of novelty effects
A common mistreatment of novelty effects is to view them as a statistical error or bias. They should not be corrected using statistical methods, which could result in more erroneous decisions.
Novelty effects are part of the treatment effects that we are studying for (a new feature, a different button, or a different process), so there is nothing statistically wrong with novelty effects.
Novelty effects are considered risky in product development experiments because we are not just estimating the “observed treatment effect” We are using the results of experiments to make product decisions, where we are inferencing and extrapolating, as summarized by Tom Cunningham.
In other words, if we look at the results from an experiment that is dominated by novelty effects, and try to extrapolate the long-term impact, we will likely arrive at incorrect conclusions.
Typically novelty effects are much stronger than the effects of the features themselves in the short term, and only in the short term. Imagine this – the restaurant you pass by every day had a 100% improvement on their menu, their chef and their services. You probably won’t even notice the improvement. But if they changed their name, you will be intrigued to enter and find out what happened.
Ignoring novelty effects
Responsible restaurant owners won’t change names every other week to attract more customers. But what if you own hundreds of restaurants and set a quarterly KPI for your restaurant managers on the daily visits? Whoever attracts the most customers can earn the biggest bonus.
Your managers would be incentivized to change the name than change the menu. This path is easy and immediately “effective”. And that’s because people respond to incentives. If people care about KPI, and novelty effects give them a quick win, then there’s a good chance it’ll be used to achieve KPIs.
Pitfalls of novelty effects
So far, we have established that
Novelty effects are part of the treatment effects, so there is no statistical method to detect them generically
Novelty effects are dangerous and will spread if you don’t combat them
In practice, novelty effects are usually easy to detect and control if you have the proper understanding.
In some cases, the root cause of the mistreatment of novelty effects is the adoption of too simple an OEC (overall evaluation criteria) and reliance on short-term metrics, e.g., CTR (click-through rate).
While there is nothing inherently wrong with CTR as a metric, it is important to understand that CTR measures many different things. An increase in CTR can mean: 1) finding value; 2) being attracted by novelty; 3) click-baited due to misleading content, and so on. As such, an increase in CTR isn’t always good.
The solution is to have other metrics in OEC to complement CTR. For example, feature level funnel, and feature level retention, can tell us whether users finished using the feature as we intended and whether they come back to the feature.
Novelty effects in time series
It’s tempting to solve for novelty effects with statistical tests but it’s generally not advisable. Let’s go back to the core of novelty effects once again:
Novelty effects refer to the phenomenon where the response to a new feature is temporarily deviated from its inherent value due to its newness.
The keyword here is "temporarily." Given enough time, novelty effects will wear off.
When we study the observed effect of an experiment, we look at the cumulative effects, which is the delta between the treatment group and the control group, cumulative throughout the experiment duration.
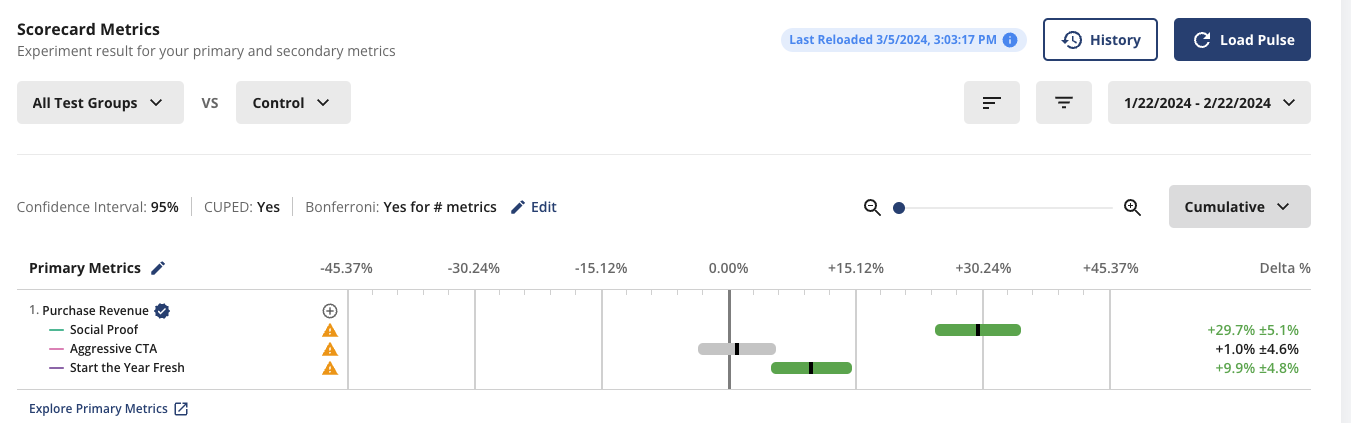
Drawing conclusions from the cumulative effects allows us to have more statistical power. It is fine if the expected treatment effects do not change, which is not the case with novelty effects. With novelty effects, even short-term metrics like CTR will behave differently when the newness wears off, so alternatively, We should look at a daily view of the treatment effects.
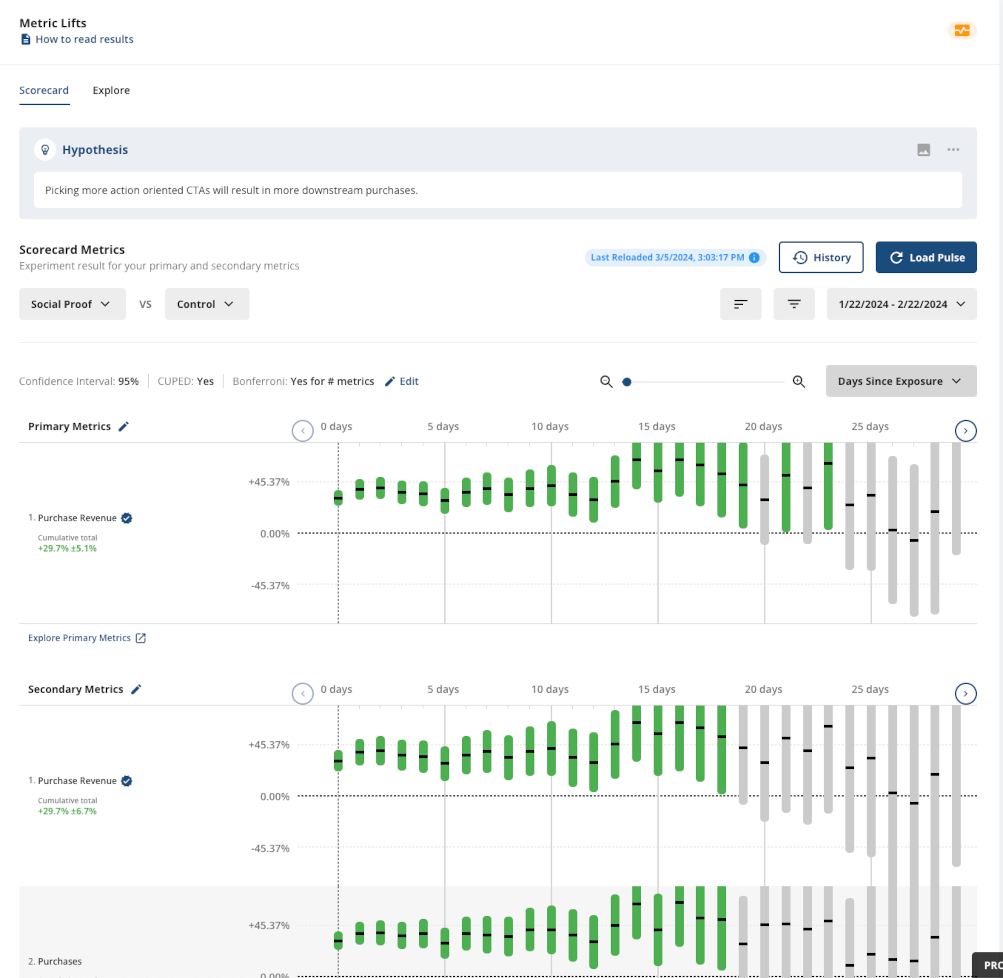
Or days since exposure view.
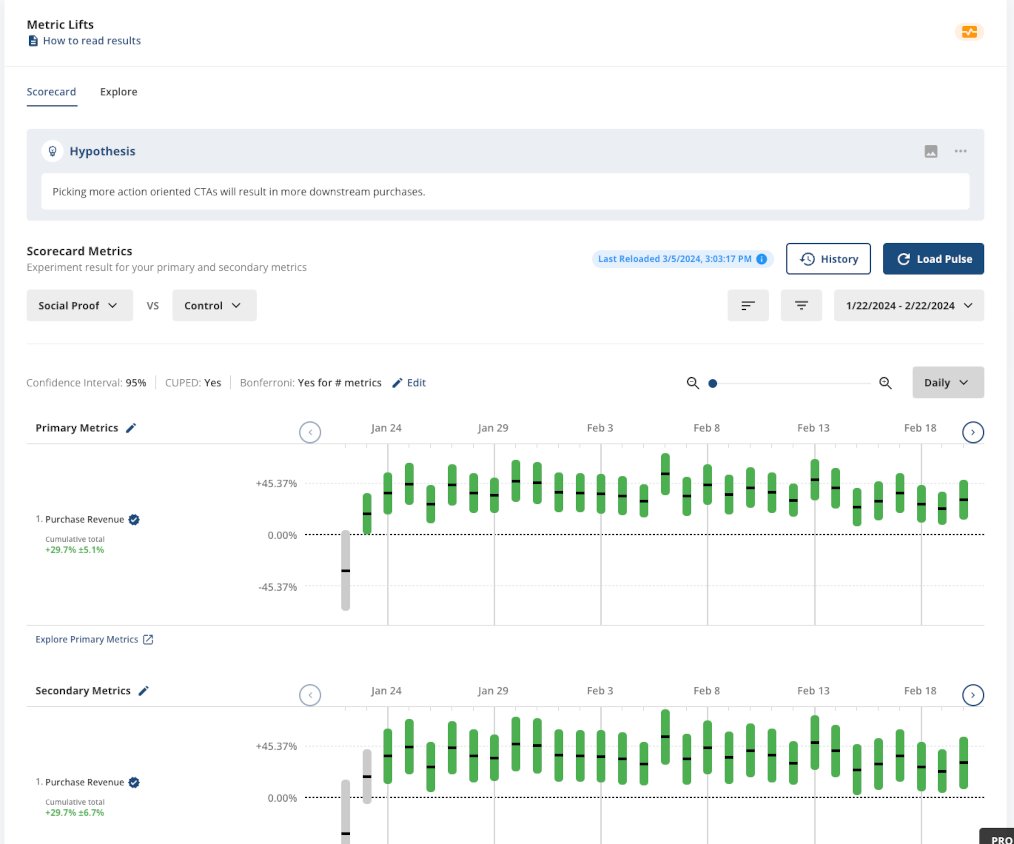
The necessary condition is that the short-term effects are different, and wear off over time. You will usually see a higher daily delta on CTR at the beginning, and then become lower and stay lower. But for certain changes, the other direction can happen as well. For example, when Facebook changed from a timestamp-based news feed (EdgeRank) to a machine-learning curated news feed, users’ initial reactions were not welcoming.
How to safely control for novelty effects
Eye-balling data to draw conclusions has challenges for two reasons:
Apophenia, or pattern-matching biases, would trick you into conjuring conclusions that are not there.
Lack of statistical power
As a result, we should be cautious about sentencing the temporary deviation in treatment effects as novelty effects. Luckily, the downside of ignoring those deviations is low, so we recommend to
Use the “days since exposure” view in your experiment results to find suspects of novelty effects – shallow metrics such as CtR behave differently between short-term and long-term
Throw away the first few days of data where you believe results might be driven by novelty effects
Make decisions on your experiments using the remaining data, where we believe the effect converges to an equilibrium, long-term value.
Don’t be paranoid
Novelty effects are a luxury. For a user to feel novelty, she needs to have expectations of her experience with your product, which is not the case for most businesses. Products where users can detect differences in experience are where you’d see the largest manifestation of the novelty effect. This is a good thing.
The other piece of the puzzle is the degree of change. For McDonald's, a change in the UI may not trigger novelty effects, but re-introducing McRibs probably will. So the simple formula is
Novelty ∝ Surprise X Frequency
If you want to be more careful, bucket users in terms of frequency of usage. Higher frequency users will be more likely to have novelty effects. Also, new users are not likely to experience novelty effects, but the other direction of this logic doesn’t hold: If a feature is impactful on existing users but not impactful on new users, you can’t claim its novelty effect, as many more factors are innate different between new users and existing users.
Related reading: CUPED explained
Take advantage of novelty effects
Remember, novelty effects are just psychological effects due to human nature. It is part of the treatment. So why not use it? For example
Drive more traffic into your strategic moves (such as ML-ranked news feed)
Synergize with other campaigns (banners, promotions, ads) to amplify your message
Design a combined approach for feature rollout – such as nux at the beginning to explain the change
Use historical experiments to build priors for novelty effects
The principle is that your job as a product data scientist is to improve your product and your business, not to design the experiment for the sake of answering hypothetical questions (learning is important but don’t learn useless things). If you can use your knowledge and design experiments to make your business more successful, do it.
Introducing Product Analytics