Products
Solutions
Resources




Ever wondered why some experiments lead to groundbreaking insights while others fade into obscurity?
It's not just luck—there's a method to the madness. Statistical significance is the magic wand that helps us separate meaningful results from mere coincidence.
In this article, we'll cover the concept of statistical significance, unravel its role in experimentation, and explore how it can make or break your A/B tests.
Understanding statistical significance in experimentation
Ever heard of statistical significance? It's a fancy way of figuring out if the results of an experiment are actually meaningful or just random flukes. At its core, it revolves around the concepts of the null hypothesis and the alternative hypothesis.
So what's all this about hypotheses? Well, the null hypothesis says there's no real difference between groups, while the alternative hypothesis argues that there is. When we run experiments, we're basically trying to prove the null hypothesis wrong. This is where p-values and significance levels come into play—they're the tools we use to determine if our findings are statistically significant.
Okay, let's talk about p-values. Think of the p-value as the chance of getting the results we did (or something even more extreme) if the null hypothesis were actually true. If our p-value drops below our chosen significance level (commonly 0.05), we've hit statistical significance! In other words, we've got strong evidence that our results aren't just due to random luck.
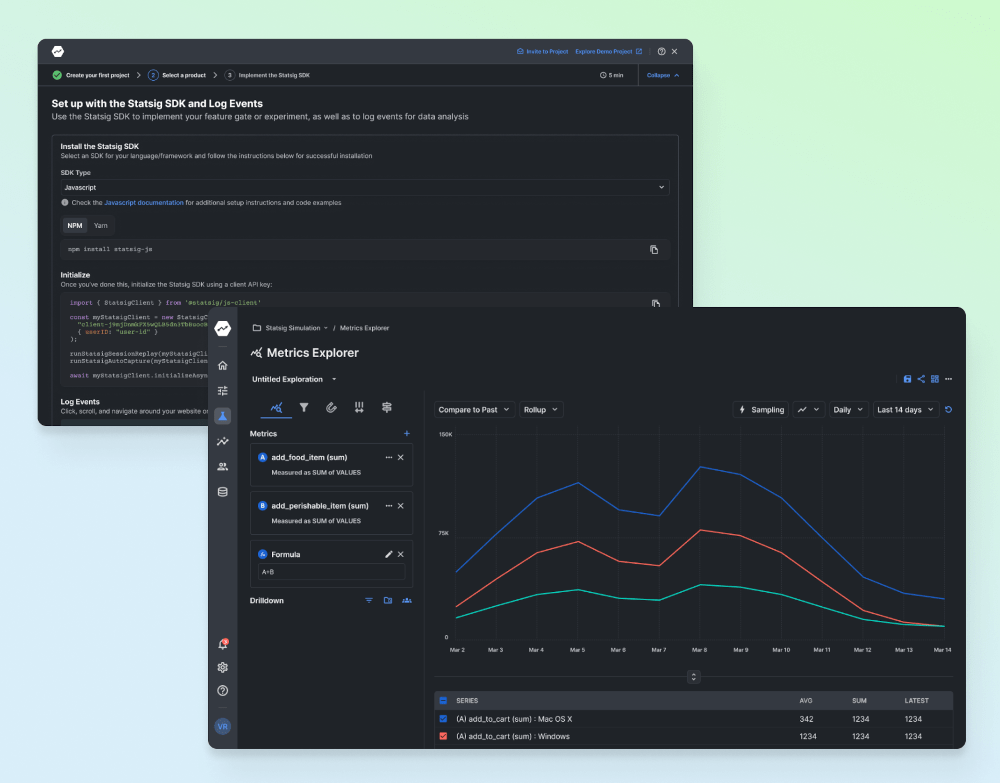
But wait, there's more! When setting up experiments—especially with tools like Statsig—we need to think about things like sample size, effect size, and variability. Having a larger sample size or a bigger effect size makes it easier to spot significant differences. Plus, if we can reduce variability—maybe by grouping similar subjects together—we can boost the power of our experiments even further.
One last thing—just because we've achieved statistical significance doesn't mean our findings are practically significant. A low p-value tells us we've got strong evidence, but the actual effect size and confidence intervals might be tiny. That's why we also look at confidence intervals and consider the real-world impact. Balancing statistical significance with practical significance is crucial for making smart decisions based on our experiments.
Applying statistical significance in A/B testing
In the world of A/B testing, statistical significance is your best friend. With platforms like Statsig, you can easily figure out whether the differences between your control group and your variant are the real deal or just random noise. By crunching the numbers and calculating p-values, you can see if your experiment's results are actually due to the tweaks you've made.
Before you dive into an A/B test, it's a good idea to set a significance level—most folks go with 0.05. If your p-value ends up lower than this, it's a sign that the differences between your groups are statistically significant. In plain English, you can trust that your changes are actually influencing user behavior.
But hold on—statistical significance isn't the whole story. Just because your results are significant doesn't mean they're making a big splash in the real world. The actual effect size might be tiny, so you'll need to think about how these changes align with your business goals.
To really nail your A/B tests, make sure you've got a big enough sample size to catch those meaningful differences. Using something like a power analysis can help you figure out the minimum number of users you need based on your desired significance level and effect size. Remember—the bigger your sample, the more reliable your results.
And don't forget about timing! User behavior can shift depending on the day or even the time of day. So, it's smart to run your tests long enough to smooth out these temporal effects—usually at least a full business cycle. This way, you'll get results that truly reflect how users interact with your product.
Common misconceptions and pitfalls in interpreting statistical significance
A big misconception out there is thinking that p-values give you the probability that your hypothesis is true. Not quite! A p-value actually tells you the likelihood of getting results as extreme as yours if the null hypothesis were true. It's a subtle but important difference.
Another trap is getting too hung up on statistical significance and forgetting about practical relevance. Just because your results are statistically significant doesn't mean they're game-changers in real life. Always consider how your findings fit within the bigger picture of your experiment and what you're trying to achieve.
Watch out for biases, outliers, and confounding variables—these sneaky factors can mess with your results. Take Microsoft's experience: they found that library accounts were throwing off their A/B tests because of huge book orders. Spotting and tackling these anomalies is key to getting accurate insights.
Finally, if you're making multiple comparisons, you might bump into more false positives—that's when significant results pop up by pure luck. To keep things legit, techniques like the Bonferroni correction adjust your significance levels, helping you maintain the integrity of your findings across different experiments.
Best practices and advanced techniques for achieving statistical significance
To design experiments that pack a punch, you've got to nail down your sample sizes and effect sizes. Bigger samples and more pronounced effects make it a breeze to spot significant differences—which means you're more likely to get results that matter.
Want to boost your experiment's power without upping the sample size? Variance reduction techniques like CUPED can help by cutting down on metric variability. By controlling for factors that could cloud your data, these methods make your experiments more efficient.
Remember, it's all about balance. Sure, p-values give you statistical significance, but don't forget to consider the effect size and what it means in the real world. Zero in on insights that are not just statistically sound but also actionable and in line with your business objectives.
Feeling adventurous? Multi-armed bandits and Bayesian methods offer cool alternatives to traditional significance testing. These techniques can optimize your experiments by dynamically steering more users toward the best-performing options—maximizing learning while cutting down on lost opportunities.
Don't set it and forget it! Keep an eye on your experiments for any anomalies or biases that might creep in. Techniques like interaction effect detection can spot when experiments are messing with each other, so you can avoid drawing faulty conclusions. Staying vigilant with data validation means you get solid insights to fuel your product enhancements.
Closing thoughts
Understanding statistical significance is a game-changer when it comes to running experiments and making data-driven decisions. By embracing the concepts we've discussed—and maybe leveraging platforms like Statsig—you can ensure your findings are both statistically sound and practically meaningful. If you're keen to dive deeper, check out the links we've provided throughout the post. Happy experimenting!
Request a demo
