Products
Solutions
Resources


Online experimentation: The new paradigm for building AI applications

In the 1990s, building software looked a lot different than it does today.
Here’s a rough outline of how it worked:
First, product managers would come up with a new idea for a product and lay out a release timeline. Engineers would then spend months or years working on a single version of this new product. At some point, initial versions of the product might be tested with focus groups—but this was largely an afterthought.
As the deadline approached, a centralized group of PMs and engineers would review the product, make last-minute cuts, and print a master disk. Tens of thousands of copies would be made in factories, which would then be put in boxes, shipped to stores, and placed on shelves.
Fast forward to today, and this process feels comically antiquated. Working in one central repo? Printing a master disk? Going to a store to buy a CD? It seems as strange as riding a horse to the office.
We believe a similar transformation is underway in the way that people build AI-powered applications. The concept of spending months or years running offline tests on a model will soon feel as out of date as printing a CD, and continuous online testing will feel as natural as daily code pushes.
A new world of generative apps
The age of AI has arrived.
It’s only been a few months since the launch of chat GPT, but a lot has changed. Dozens of new foundation models—GPT-4, Alpaca, LLaMA, and Stable Diffusion—have been launched, AI communities have been galvanized, and developers are building at a pace we haven’t seen in years. The opportunities seem endless.
Large technology companies, including Statsig customers like Notion, Microsoft, and Coda, have been quick to enhance their product suites with these models, delivering AI-powered features to millions of users. Simultaneously, an enormous number of generative native startups have flooded the internet with entirely new applications.
We’re in the midst of a paradigm shift: AI is on the precipice of fundamentally changing the way we work and the way we live. It’s an exciting moment, but it presents developers with a number of challenges:
How can you launch and iterate on features quickly without compromising your existing user experience?
How can you move fast while ensuring your apps are safe and reliable?
How can you ensure that the features you launch lead to substantive, differentiated improvements in user outcomes?
How can you identify the optimal prompts and models for your specific use case?
We believe the answer is a change in the way companies approach AI/ML testing:
In the past, AI/ML research engineers led the development of AI features. Their efforts were largely focused on offline testing: building and refining training data, engineering specific features, and tuning hyperparameters to optimize metrics like precision and recall. This process took months and was often completed without direct user feedback.
Today, we live in a world where new, pre-trained foundation models come out each week, and AI features can be built by any engineer. In this rapidly changing environment, speed is far more important than precision. The companies that will win this wave of AI development will embrace a new paradigm of testing—one focused on quickly launching features, rapidly testing new combinations of models, prompts, and parameters, and continuously leveraging user interactions to improve performance.
But this speed cannot be reckless—guardrails must be in place to ensure the pace of change does not compromise a company’s reputation or degrade its current product.
Ultimately, the only way to truly test the capabilities of generative AI is to put it in front of users. The only way to do that safely is to use the right tools. Fortunately, Statsig makes those tools available to everyone.
Stuck offline: Evaluation based on the traditional AI/ML testing paradigm
Traditionally, AI/ML testing focused on training custom models designed for specific tasks. Specialized research engineers were deeply involved from ideation through development, testing, and deployment—a process that could take months or even years to complete.
This version of offline testing was very academic. Researchers would test the model against various statistical tests and benchmarks (e.g., perplexity, F score, ROUGE score, HELM) to assess its performance for a given task. There was also a heavy emphasis on data preparation and processing; training data had to be carefully prepared and split into training, validation, and testing sets which were used throughout model development.
After all this testing, versions of the model would be evaluated with human feedback—but this feedback rarely came from users. Instead, small groups of employees or contract workers (sourced via products like Mechanical Turk) would score responses or run through test applications. This evaluation was useful, but often provided a very different type of feedback than real users.
Only after this rigorous process would the model be put in front of actual users. Even then, online testing was often limited. Developers might create a few experiments with a flight of highly similar models, but this was often an afterthought relative to the extensive offline testing.
All of this made sense in a world where performant models were tightly-guarded trade secrets that required an immense amount of work to develop. However, that is not the world we live in today.
While the old process is out of date, offline testing is certainly not dead. We’re already seeing success in using models to evaluate models, both in conjunction with human feedback and in standalone, iterative refinement. These methods are promising, and point to a future where models are used to evaluate AI features before they are shown to a single user. However, these methods are not a practical way to drive rapidly improve AI features today.
Coming online: Evaluation based on user impact
With the rise of publicly available foundation models, the nature of AI development has changed. Companies no longer need to spend months or years building their own models; instead, they can leverage the latest models via an API. What was once the domain of a select group of research engineers is now available to nearly any software engineer.
This combination of performance and access has opened the door to a new AI testing paradigm: one that resembles the rapid iteration of Web 2.0 companies far more than the staid practices of research scientists.
The “evaluation flywheel” will look something like:
Build compelling AI features that engage users
Flight dozens of models, prompts and parameters in the ‘back end’ of these features
Collect data on all inputs and outputs
Use this data to select the best-performing variant and fine-tune new models
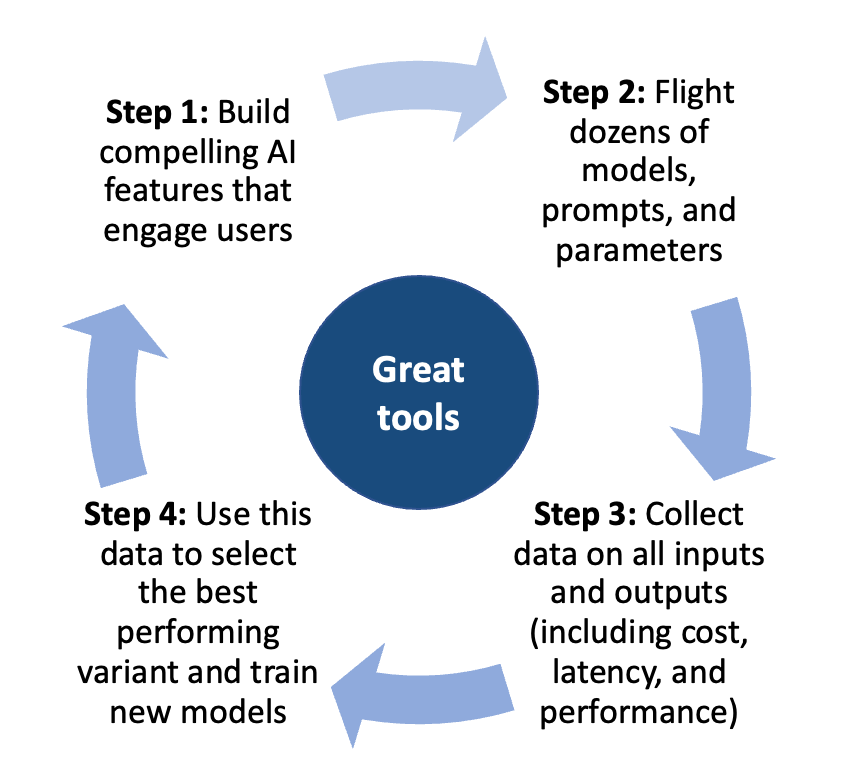
While this flywheel may seem simple (of course you’re going to iteratively improve features over time) there are so many things that can cause friction and grind it to a halt. This is where using the right set of tools matters. Our toolset enables you to do the right things quickly, such as:
Feature gates, which take the risk out of launching new features with partial and progressive rollouts
Off-the-shelf experiments, which make it effortless to test flights of different prompts or models
Standardized event logging, which can be used to track model inputs / outputs and user metrics
A world-class stats engine, which shows you the statistical effect of every change on every output you care about
A single store for all of this data, which can be used to fine-tune and train future models
In the long run, turning the evaluation flywheel and iterating quickly will be critical to building new and differentiated experiences, and the companies at the forefront of this next wave will be those that turn it the fastest.
How to embrace online testing
AI is everywhere. Smart companies are wondering how they can get a piece of the pie, and smart engineers are wondering how they can start companies.
In this new gold rush, the pressure to launch features quickly is immense. But the risks are palpable—for every AI success story, there’s an example of a biased model sharing misinformation, or a feature being pulled due to safety concerns.
In order to embrace online testing—and avoid painful failures—companies need the right set of tools. Tools to enable partial or progressive rollouts of new features, with user metrics guiding decisions at every point along the way. Tools to compare the performance of different models, prompts, and parameters. Tools to measure model cost, latency, and performance—and enable a tradeoff conversation between them.
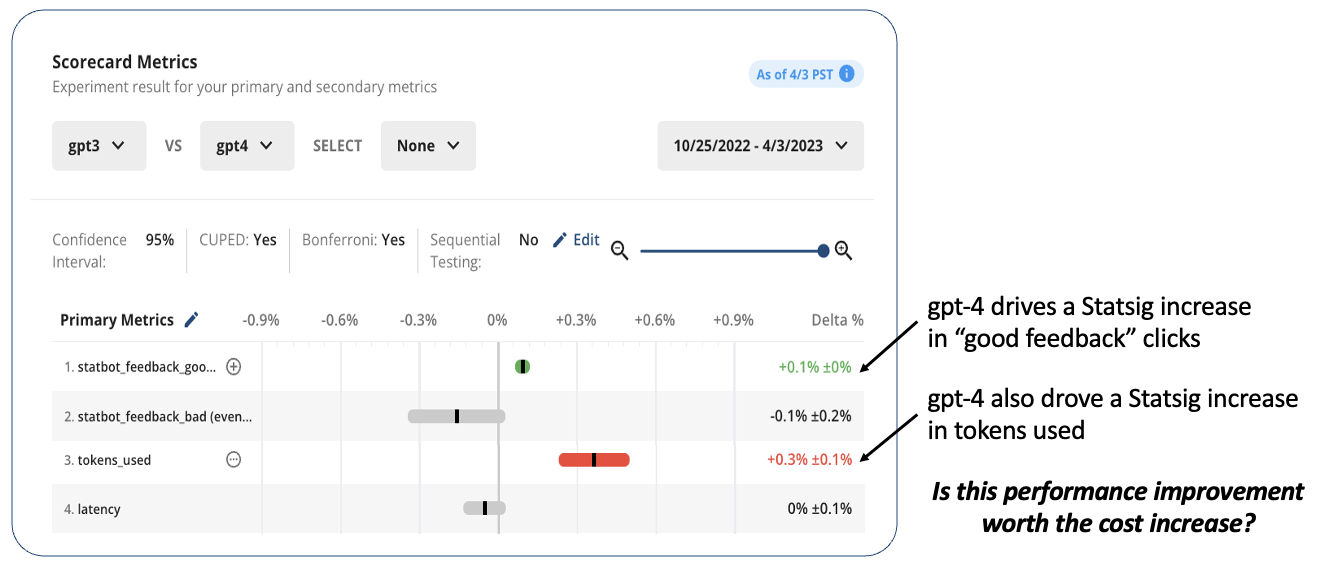
Companies also need to embrace a culture of experimentation. To rapidly iterate on new ideas, learn from failures, and so on. This can be hard, but a great toolkit and accurate data make it a lot easier.
Statsig was built to give every builder access to these tools, bridging the gap between big tech and everyone else. In this moment of explosive change, that mission feels more pressing than ever.
If you'd like to learn more about how to actually use Statsig in this way, we wrote a deeper dive on how to use Statsig to experiment with generative AI apps.
Join the Slack community
