Products
Solutions
Resources
AI Evals
Deploy AI with confidence
Grade LLM outputs with offline evals, shadow test in production with online evals, and control AI deployments with AI configs
Why Statsig for AI evals?
Statsig lets you benchmark, iterate, and launch AI systems without
code changes. Run offline and online evals, control deployments with AI configs, then optimize with online experimentation
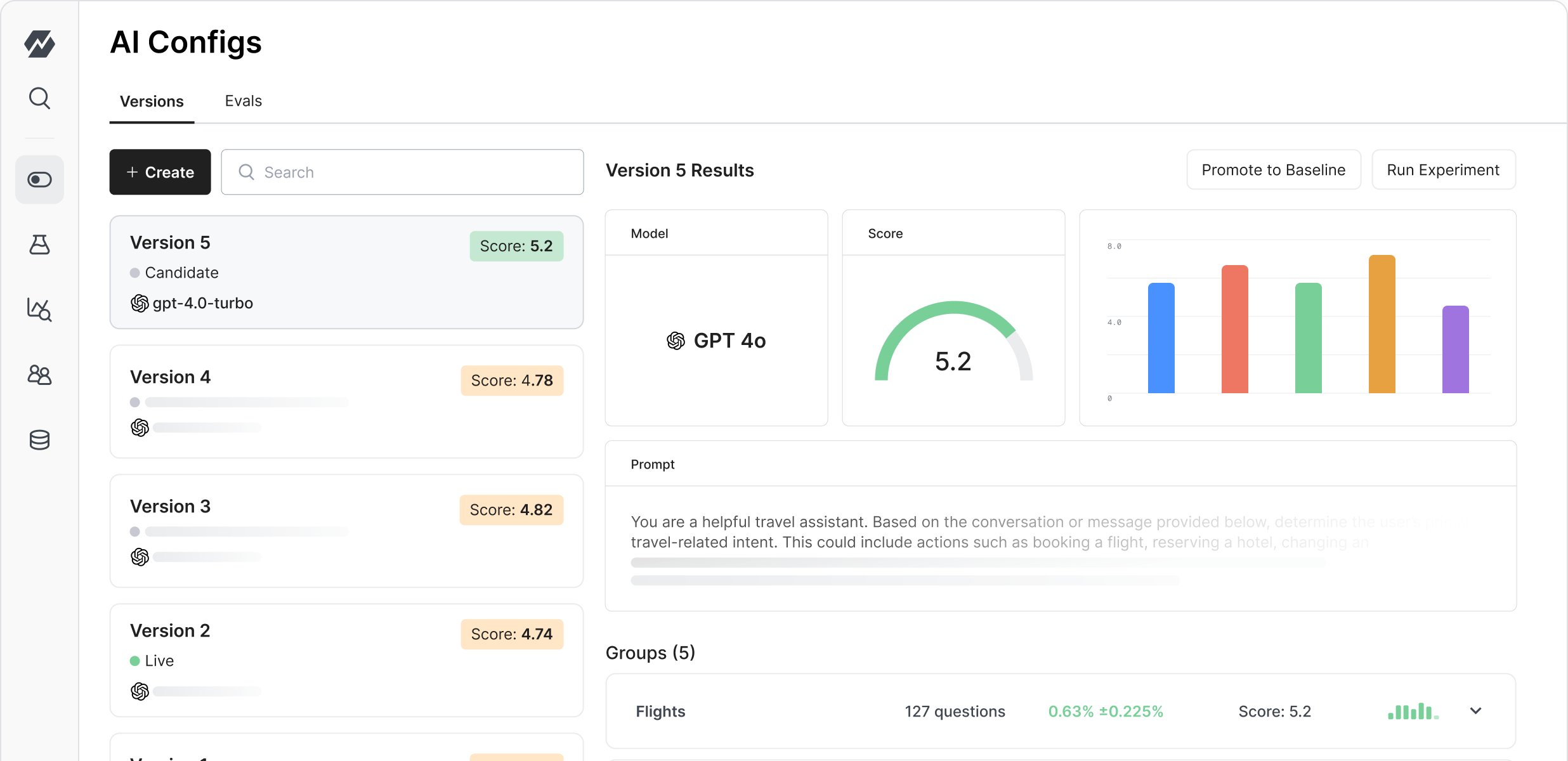
AI Configs
Store LLM inputs in an AI config to track versions, manage releases, and run automatic evals on every new configuration
Offline and online evals
Run offline evals on curated datasets to grade your AI outputs before you ship. Then keep these evals in prod to monitor output quality
Analytics and experimentation
Track eval performance, cost, usage, and user metrics in one place. Then optimize your app with analytics and online experimentation
Prompt and model versioning
Use AI configs to store your unique model, prompt, and input configurations, then automatically run evals and manage releases
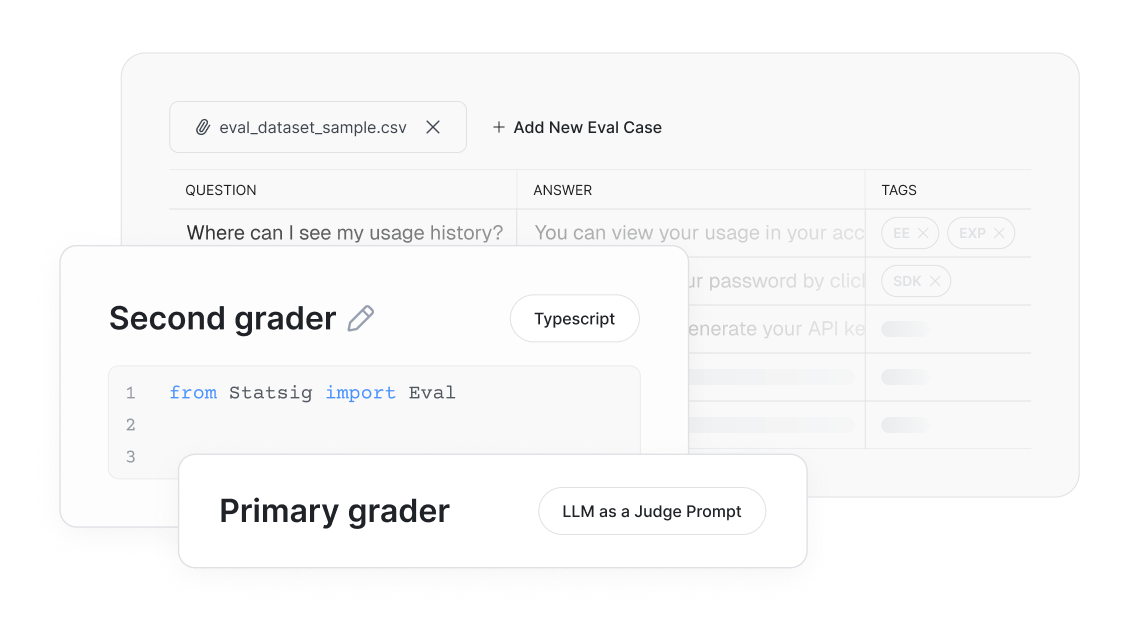
Automated grading pipelines
Upload datasets, invoke your model, and let Statsig score outputs automatically using LLMs - no bespoke scripts required

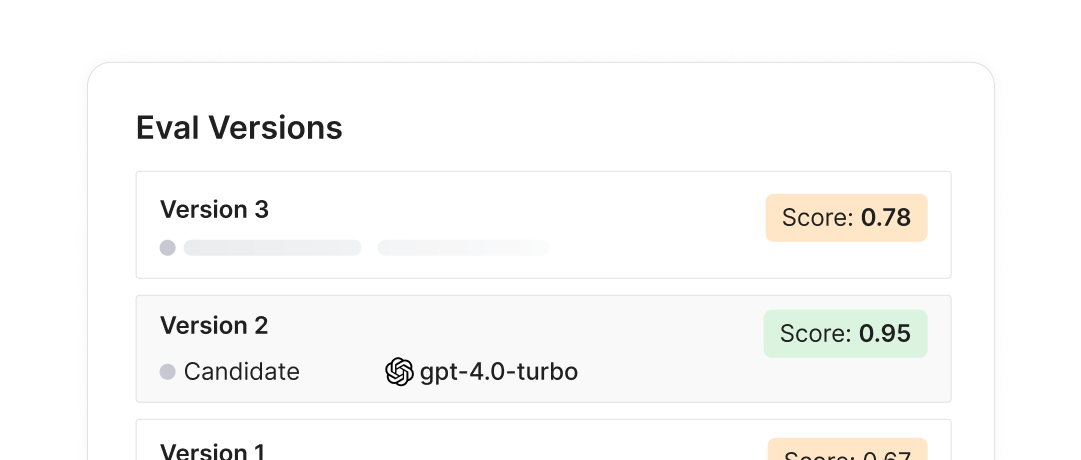
Online evals
Serve the "live" version to users while silently grading candidate versions to pick a winner with no customer impact
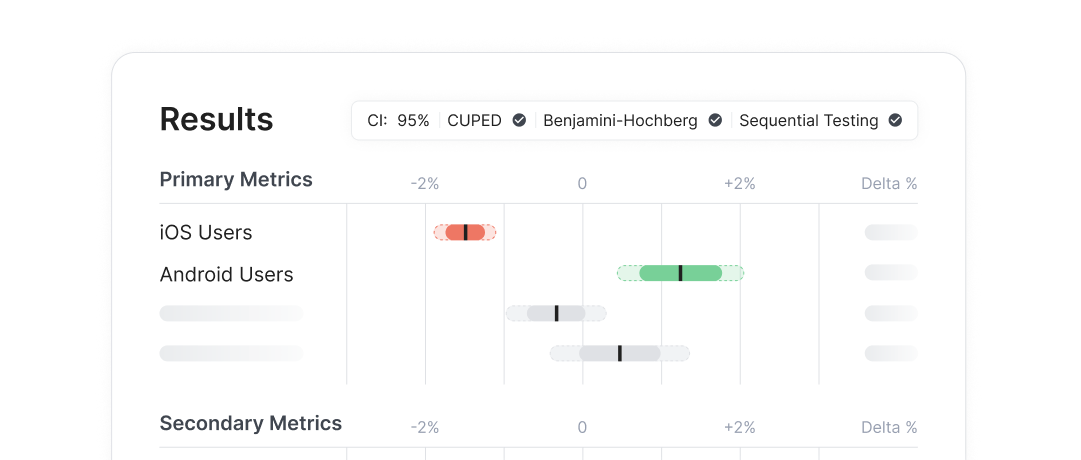
Real-time evals dashboards
Track average ratings, score distributions, and other eval metrics, then extend to online success metrics like cost, latency, and performance
Lightweight SDKs for any stack
Log evaluations from backend, frontend, or serverless code using familiar Statsig SDKs - now extended for AI workfloads
Enterprise-grade, AI-ready infra
We power trillions of events daily serving customers with hundreds of millions of MAUs. The biggest and best AI players trust Statsig
At OpenAI, we want to iterate as fast as possible. Statsig
enables us to grow, scale, and learn efficiently
Dave Cummings
Engineering Manager
It has been a game changer to automate the manual lift typical
to running experiments. Statsig has helped product teams ship the
right features to their users quickly
Karandeep Anand
President
We've successfully launched over 600 features by deploying
them behind Statsig feature flags, enabling us to ship at an
impressive pace with confidence
Wendy Jiao
Staff Software Engineer