Products
Solutions
Resources


How top AI companies are using Statsig to build their products

10 months ago, AI was a shiny new toy for most developers. Today, we take it for granted.
AI-through-API has been deployed in production and is being served to hundreds of millions of users. As it’s become a normal part of software applications, we’ve learned a lot about how to build with it.
At Statsig, we’ve witnessed this firsthand through a number of industry-leading customers, including OpenAI, Anthropic, Character.ai, Notion, Brex, and others. These companies have made expert use of our platform to build their product. In this article, we’ll share a bit about how they’ve done this—and how any company building with AI can do the same.
There are a few common usage patterns—which are covered below—but, at their core, the best AI companies use Statsig to empower engineers, iterate faster, and democratize access to product data.
When engineers have tools that give them full, end-to-end ownership of product development, magical things happen.
This was true for the last generation of great consumer companies (Facebook, Uber, Airbnb, etc.) and it’s proving to be true for this generation as well. We pride ourselves on moving fast (it’s one of our core values) and it’s unbelievably cool to see companies use our platform to move even faster.
Build faster: Using feature gates
AI companies are building super fast.
For early-stage startups, the biggest component of “building fast” is shipping a lot of new code. And to ship a lot of new code safely, you need to have some system for managing releases.
This is true for any company building software, but there are a few reasons why release management systems are even more important for AI companies than everyone else.
First: Why is feature management important for any company moving super fast?
Well, when engineers can put every feature behind a gate, they can write code in production repos without releasing features to the public. This helps them do a few important things:
Work in the latest repo, allowing them to write code within the most up-to-date context
Test features in production, by allowing access only to themselves
Test features collaboratively, by giving access to their co-workers/teams
Gradually release features to larger groups of users
Target features to specific customers (particularly useful for B2B companies)
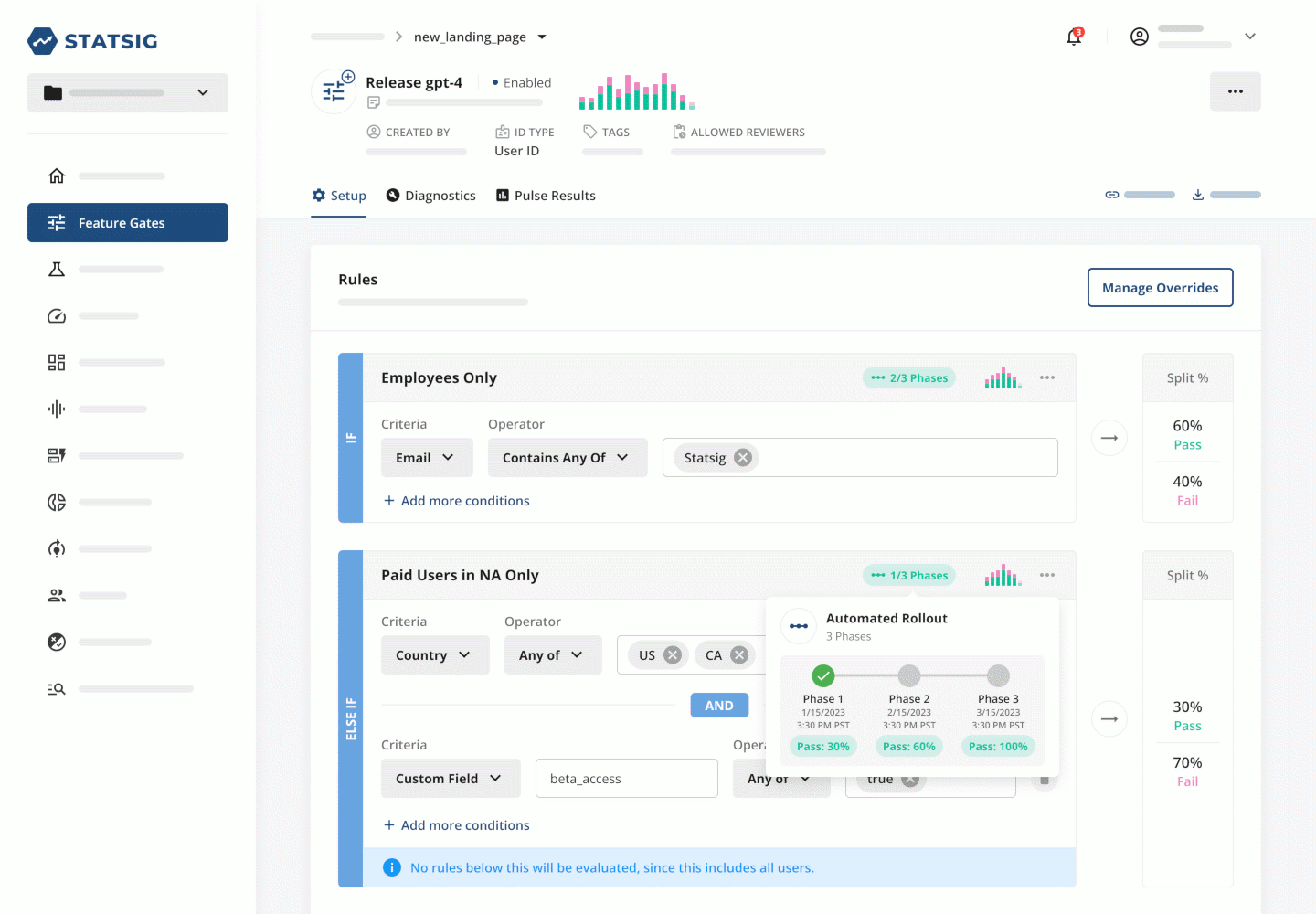
Using this playbook speeds up releases by eliminating roadblocks between writing code and deploying it, including coding in out-of-date repos, missing important context in code, and having to merge parallel branches. It also decreases risk by making testing much easier.
This process—which scales from 1 engineer to potentially millions of users—is good hygiene for any company. Tangibly, it means fewer bugs and better quality control. However, it’s particularly important for AI companies because AI apps have some unique characteristics:
Complex interaction effects: AI products often comprise intricate chains of prompts and rule-based evaluations. It’s difficult to see the impact of a change to one component in a localized testing environment - meaning testing in production is doubly useful.
Non-deterministic results: AI products can produce very unexpected outputs. Collaborative testing—where a team is running dozens of I/O loops each—can help surface potential bugs or edge cases.
Extra worry about compromising metrics: AI products can feel scary, especially for companies that already have established products. Launching new products or features via progressive rollouts effectively mitigates the risk of new product launches on existing product performance.
Example: Microsoft’s “new Bing” ran into substantial negative press when it began acting in unpredictable and even threatening ways, leading to the company releasing a new version. The ability to measure and react to this feedback without redeploying code provides a significant edge.
Custom features/models: Many B2B AI companies have tailored solutions for specific customers (i.e., specific prompts or models). A feature management platform gives companies a single control pane that they can use to manage who sees what.
Example: As AI regulation evolves, model versions might need to cater to specific jurisdictions. For example, ChatGPT was at one point unavailable in Italy due to non-compliance with local data protection regulation. After OpenAI added privacy controls, the service was once again made available.
This workflow is valuable even without advanced feature flagging management features (like gate launch analytics). But it really starts to hum when you layer on additional components of the Statsig platform—especially experimentation.
Build smarter: Experiments
Like feature management, product experimentation is important for every software company.
But it's even easier to understand why experimentation is so important for AI companies: there's so much we don't know about what works for AI apps!
Today, most companies are still stuck offline when testing AI inputs. First, companies will cycle through prompt / model / embedding / input parameter combinations until they get a configuration that works for their use case. Then, they use a manual scoring process to select the combination that makes its way to production, which looks something like this:
Come up with a big list of sample user inputs
Run them through a test script with the selected configuration to turn these inputs into outputs
Create scoring criteria for these outputs (typically using human-generated benchmarks or simple “1 - 10” scales)
Measure the test results using these criteria
Rinse and repeat with a new configuration
There’s nothing wrong with this approach. In fact, it’s a great way to select the initial version of an app that’s shown to end users. However, there are huge limitations to this approach:
The test inputs are constrained to the things that engineers can imagine inputting (versus what users are actually inputting)
The scoring criteria have little to do with the configuration’s impact on product performance
They often fail to capture the full extent of variation that’s possible (i.e., not testing all prompts or all embedding schemes with all models)
They fail to capture each configuration’s impact on factors not related to output quality (e.g., cost, latency)
This model makes sense when you’re working to create a production app or feature. But as soon as you launch your app or feature, there’s a better way to test: online experimentation. And that’s exactly how the best AI companies are approaching this problem.
Online experiments allow you to change any parameter in your AI application, whether it’s related to AI or not. These could include the model you’re using, the prompt you’re using, model temperature, max tokens, or non-AI components of the app (e.g., button color, default prompt). Our customers have found very interesting results from these experiments.
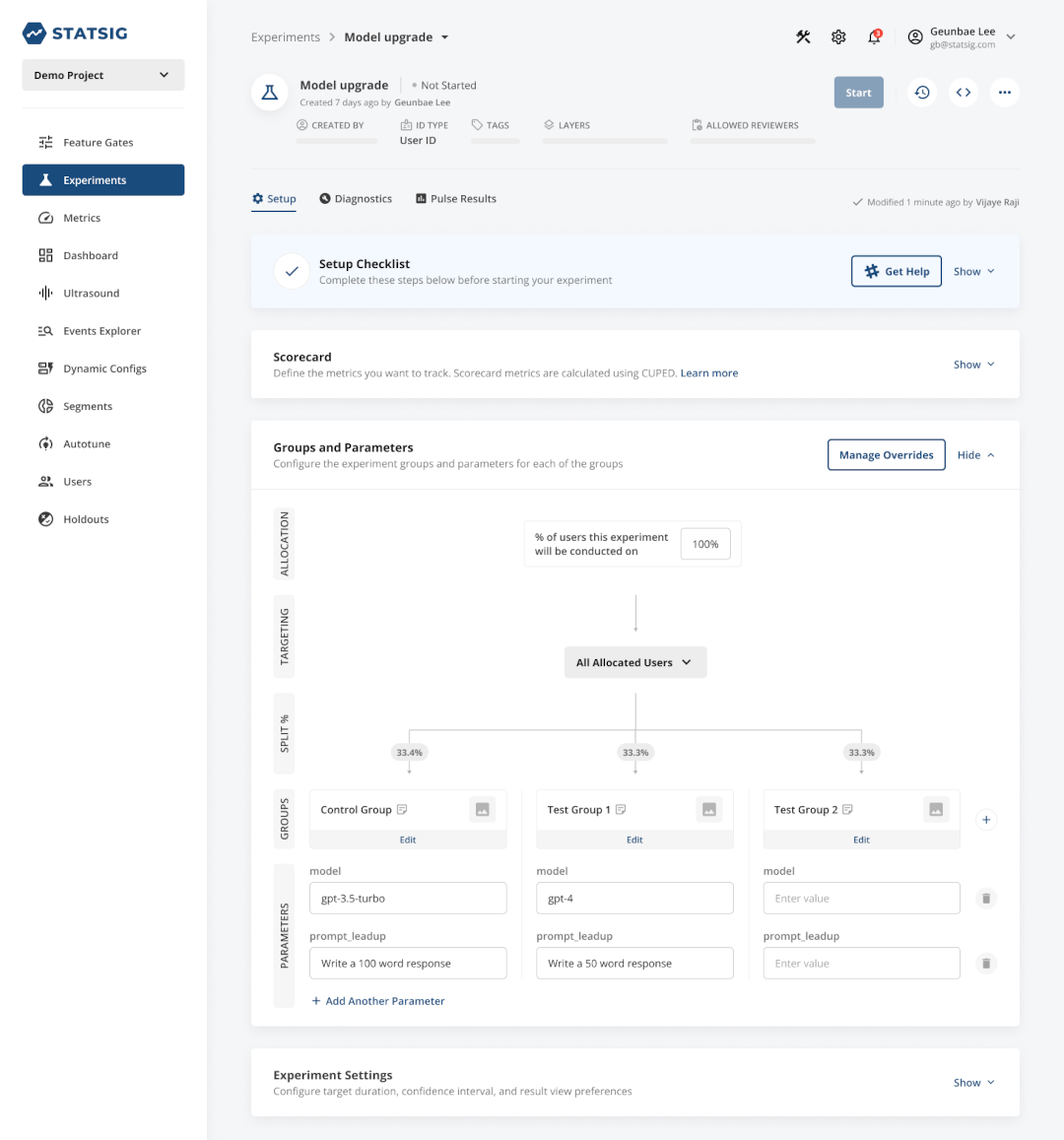
The most common thing that AI companies run experiments on is, unsurprisingly, the model behind their feature. Models have a huge impact on response quality, latency, and cost. It’s also very easy to swap models out.
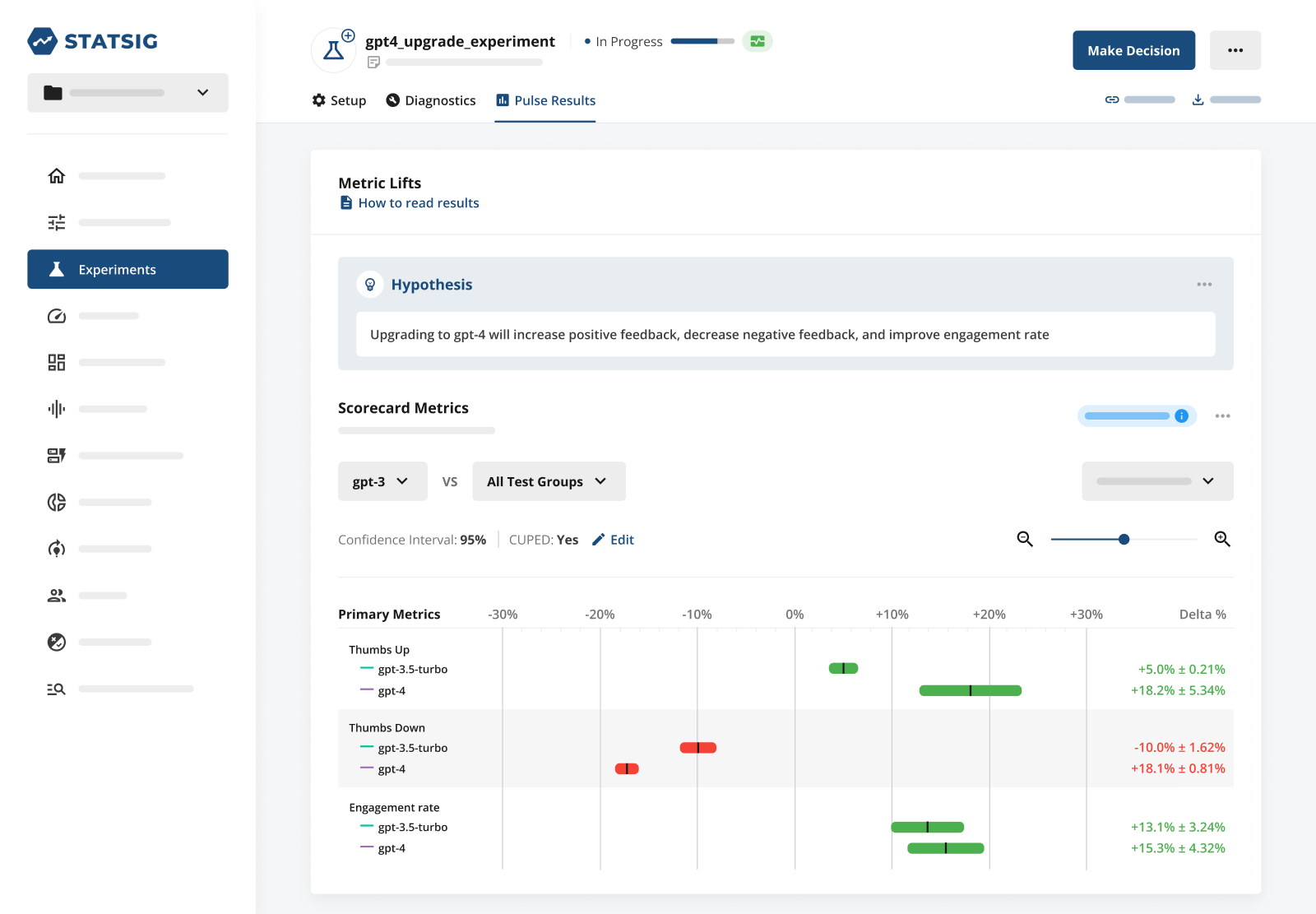
Model experiments can be especially valuable when performed for an individual feature. Different features demand different combinations of performance / latency / cost. By experimenting with the model used for each specific feature, you can find the optimal configuration for every feature, increasing performance and saving money.
Example: A company has two AI features: a chat app for their docs page, and a data labeling workflow that enriches data for customers. The chat app only deals sends ~3,000 calls per day, but the data labeling workflow sends 100,000 calls per day.
The chat app is a high-performance, low-latency use case, where cost isn’t a huge concern. The data labeling workflow has lower performance and latency requirements, but high volumes mean cost is very important. Experimentation can find the optimal model for each application.
Prompt experiments are also very popular. Anyone who has built with AI knows that different prompts have a huge impact on output quality—particularly changes to what output the model is being asked to produce, or changes in the examples used in the prompt.
However, more subtle changes to prompts can also drive big changes in the user experience. One particularly interesting example is experimenting with model tone (i.e., asking a model to deliver a “sincere” vs. “informative” vs. “funny” response). Another variation of this is asking the model to respond as a different persona (i.e., “pretend you are a developer” vs. “pretend you are a data scientist”).
Because these changes don’t have significant effects on the information content of a response, they are very difficult to measure using an existing testing paradigm. But intuitively, we know that different tones will drive different feelings in users, moving important metrics like engagement or stickiness.
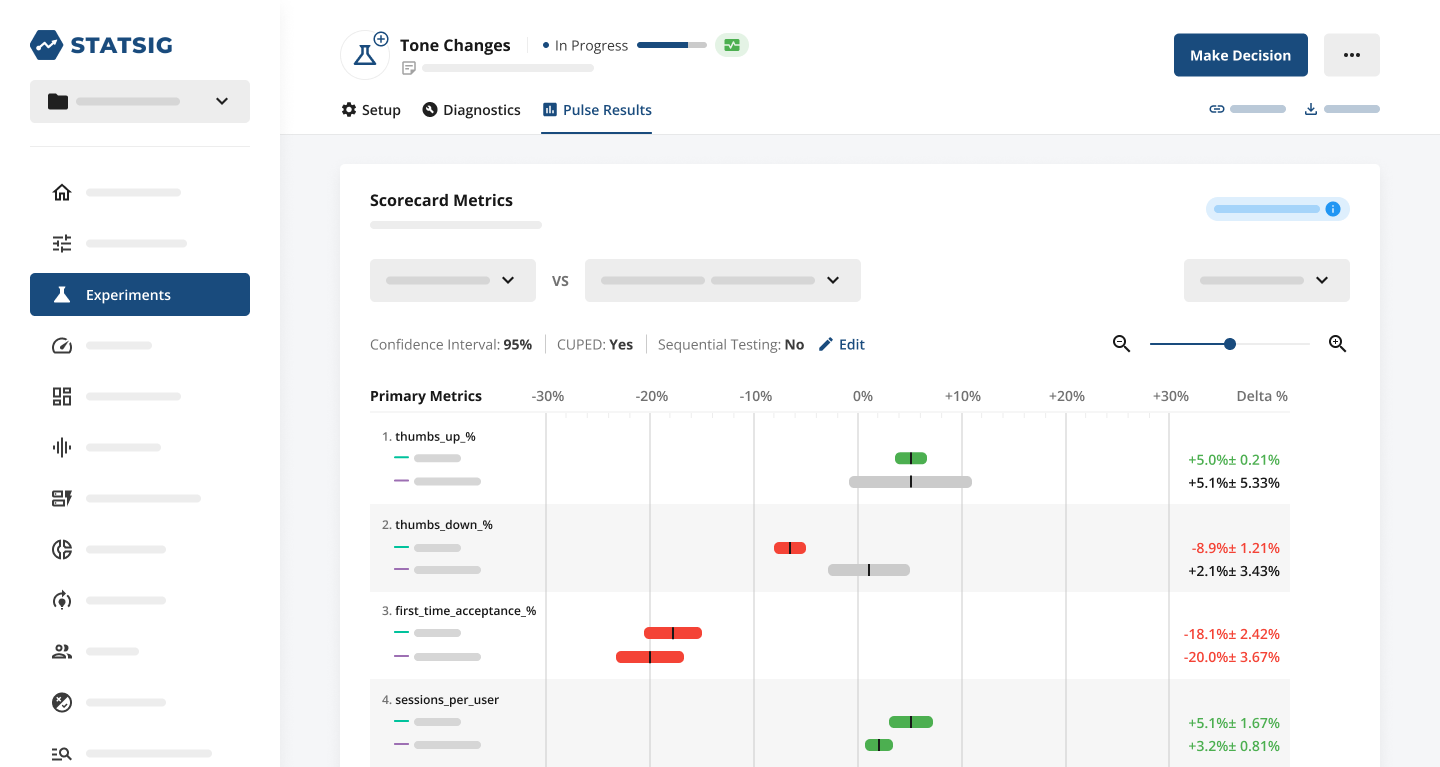
We’ve seen very successful experiments with a number of other AI inputs, from temperature to max token count to vector DB used to—but you probably get the sense of how this works from the descriptions above.
Another unexpected area where we’ve seen a ton of experimentation is on components of AI features that have nothing to do with AI, like new user flows to larger buttons to name a few. Experimenting with these types of application components can dramatically change the way that users interact with your application.
The best example of this type of experiment is in changes to the “sample prompts” and default text in the input field for chatbot-style apps. Changes to these fields can dramatically increase AI application’s engagement rate, without any substantive changes to the product.

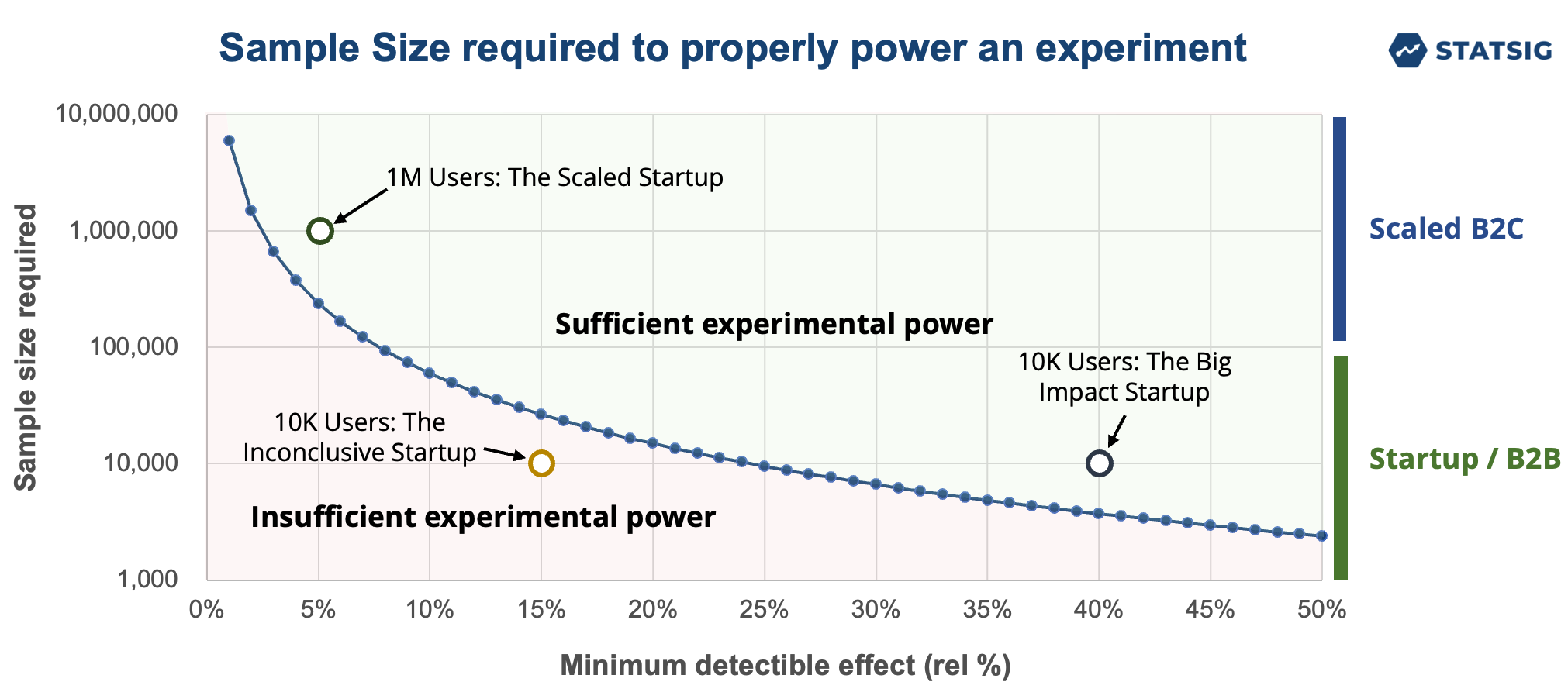
A final area where we’ve seen AI companies use experimentation is for catching bugs. Many AI companies are small, so they don’t have a ton of users to power experiments. While you don’t need a million users to power experiments, it may be difficult to see impact on metrics like engagement rate or stickiness if you’re a small company.
However, there are metrics (i.e., crash rate) that will show dramatic changes in a short period of time if there’s a problem. These metrics can show statistically significant results with a very small number of users. We’ve seen a number of small companies catch bugs by including bug-related metrics in their experiment scorecard, and setting metric alerts.
Okay, so there is a LOT to experiment on when you’re building AI apps, and there’s a lot to track. Everyone would love to test all of these features all at once, but how?
Learn more from your user count: Layers, Layers, Layers
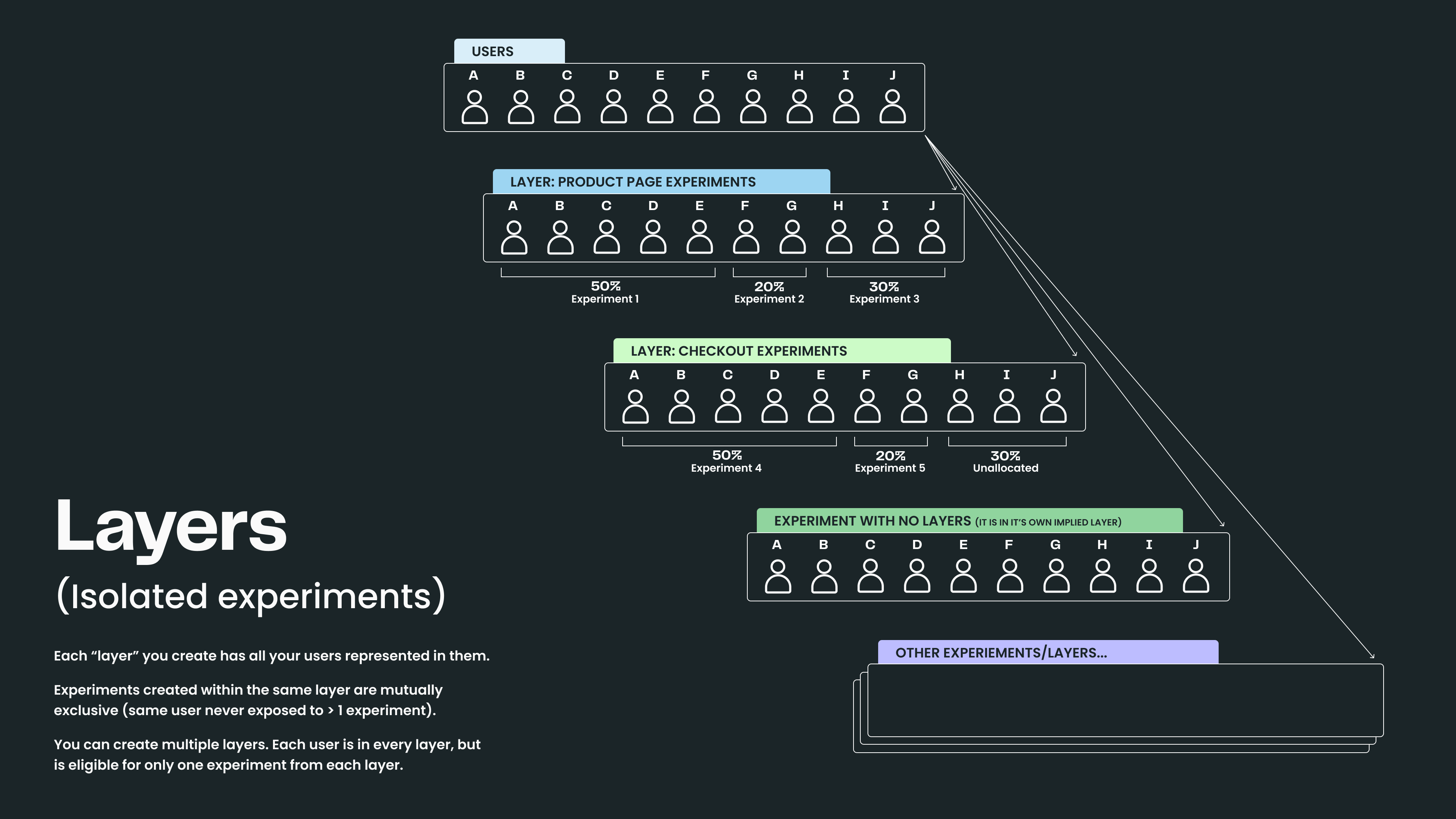
Statsig Layers (a.k.a. Universes) allow companies to create experiments that are mutually exclusive to each other. Each layer has a logical representation of all your users and can have experiments created "within" this layer. Users that are in one experiment of a layer cannot also be in another experiment in the same layer.
Put simply, layers allow you to run more experiments on a single user by ensuring that a user isn’t assigned to two contradictory experiments. This feature can be transformative for AI companies because it allows them to simultaneously test several components of an AI application.
Assuming the inputs are all discrete, AI companies can simultaneously run experiments on things like:
Model
Prompt
Model temperature
Vector database
Variable
Feature UI/UX
By creating a layer for each of these, companies can dramatically increase the amount of information they get from their existing user base. Since each layer is randomized independently, results from each layer won’t corrupt the experiment results from the other layers.
This removes a huge barrier for developers building AI apps. It means they can independently run tests on their component of an application, without corrupting other experiment results.
If a developer is rolling out a new version of a model, all they have to do is take some allocation from the existing “model” layer and run the experiment—no additional work or headache required.
Example: Jane is testing which models work best for an AI feature. Joe is working on changing prompts for that feature. With Layers, they can both runs experiments at the same time, with results they can trust.
Scaled AI companies make extensive use of layers. Coinbase has a fantastic article on the topic, that’s worth a read if you want to dive deep. In the meantime, here’s an illustrative example of what this could look like.
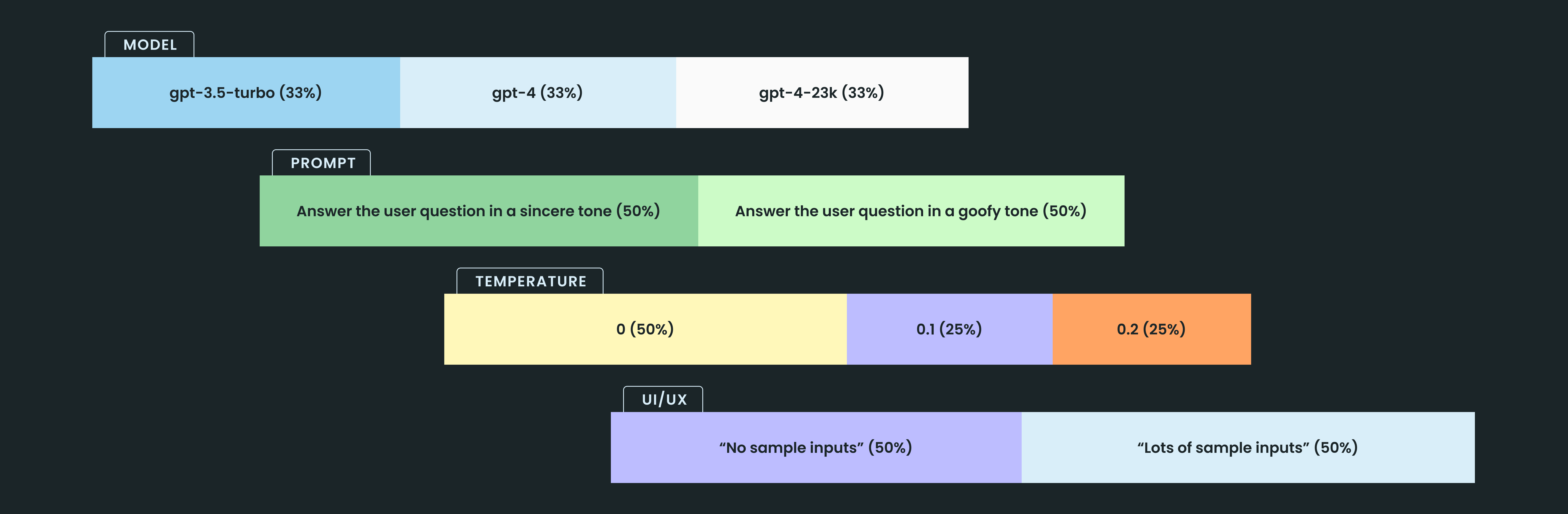
In this example, a single user would take part in four experiments simultaneously, without any additional effort from an individual developer. All with valid results & automated impact analysis.
Join the Slack community

Tracking progress: Analytics
Outside of individual experiments, gates, and layers, it can be helpful to see the bigger picture: the impact that any AI initiative has on overall product performance. AI companies use Statsig to track their progress, with metrics that are already being logged in their code.
The core metrics that we see AI metrics tracking are classic user accounting metrics: DAU, WAU, MAU, stickiness, retention, etc. As soon as you set up Statsig, these metrics will be tracked automatically: giving your team a scorecard that they can use to track progress from day 1.
There’s also been a whole suite of AI metrics that we’ve seen companies track. Many of these center around the holy trinity of performance, latency, and cost. Some particularly useful metrics that we’ve seen include:
Performance:
Thumbs up / thumbs down rate
First-time acceptance rate
Overall acceptance rate
Successful query rate
Number of queries completed
Number of sessions initiated
Sessions per user
Chats per user
Latency:
First token completion time
Last token completion time
End-to-end completion time (including application latency)
Cost:
Number of tokens
Implied cost (number of tokens * cost per token)
These companies have built dashboard after dashboard to track their performance over time, which is pretty cool!
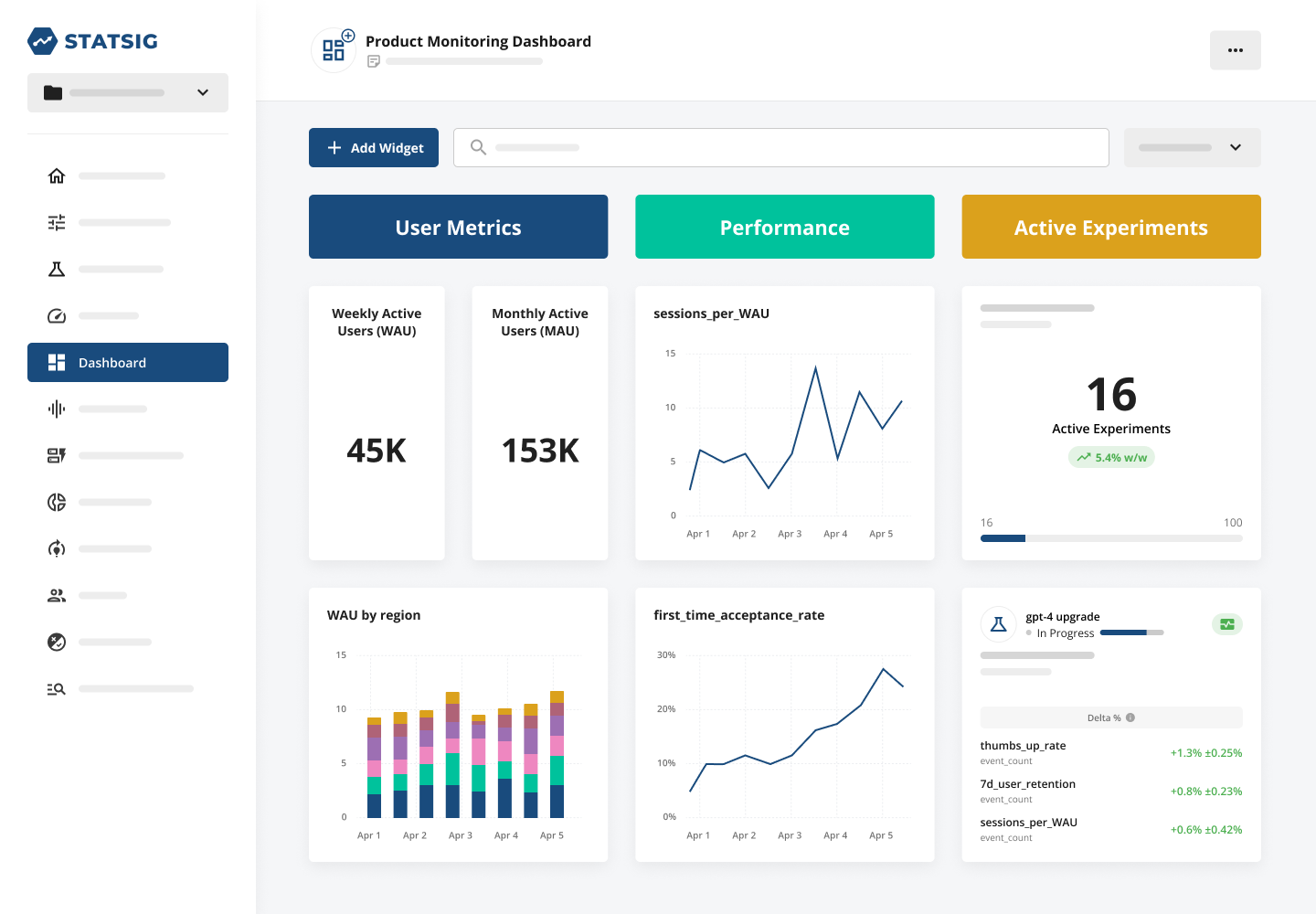
They’ve also made hefty use of our analytics offering to dig deeper into their performance. This can be super useful to break down the performance of a headline metric by user groups, letting you see how your product is performing with specific user segments.
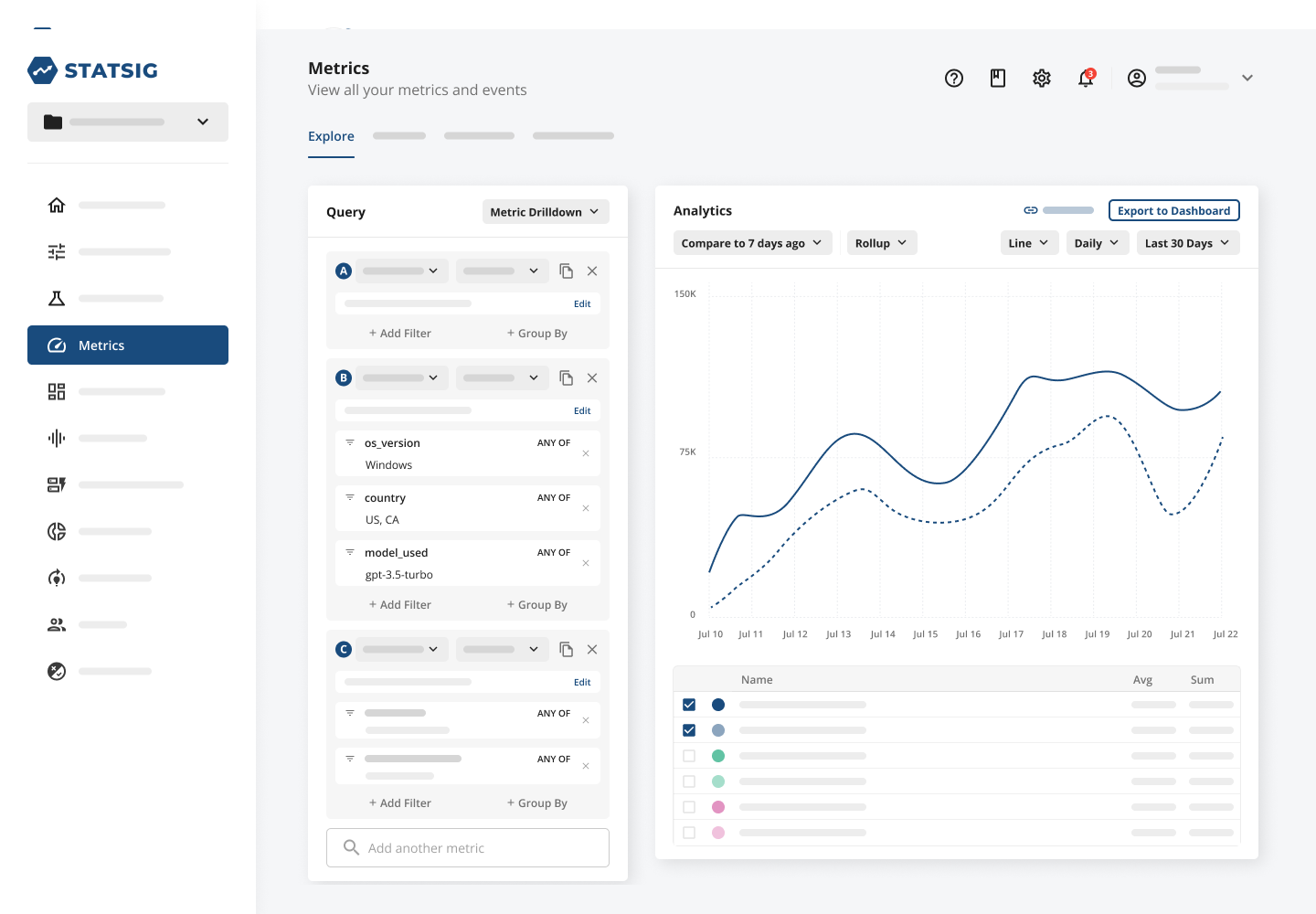
Analytics are especially powerful when combined with feature flagging and experimentation because the data behind each component comes from the same set of metrics.
For companies who aren’t running a ton of experiments, it can provide a crucial source of data to observe the impact of feature releases. For companies who are running a ton of experiments, it can help unpack confusing experiment results and identify trends.
And for any company regardless of experiment velocity, it’s a great way to measure success over time.
Read our customer stories
AI is here to stay
Whether you’re an AI maximalist or a skeptic, it’s undeniable that AI has forever changed the way that we build software products.
If you are trying to build AI apps, execution is critical.
The technology is still nascent and there are substantial risks when launching AI features. The best AI companies have found a way to leverage feature flags, experimentation, and analytics to minimize these risks & supercharge successes—a process that any company building with AI can learn from and adopt.
In March last year, I wrote the following to close out our first AI-focused blog post:
"Statsig was built to provide amazing tools to people building amazing products. We’re so excited to see the sort of things people are able to create when our platform is combined with the latest generative AI tools."
Fast forward 7 months, and some of the best AI companies have leveraged our platform to supercharge their growth. It’s been unbelievably cool to be a small part of their journey.
We’re so excited to see what else people build with Statsig.
Get started now!
