Products
Solutions
Resources



Implementing a SaaS provider in the critical path of your applications always carries some inherent risk.
Ultimately, any tools that affect your availability and system performance are inherently risky, but there are always ways to mitigate.
There will always be tradeoffs when solutioning to make your system more resilient. In this article, I’ll cover some of the key methods and design patterns that our customers employ to help them sleep soundly at night.
With any sort of experimentation or feature flag provider, there are a handful of common concepts that carry reliability and performance implications—here is a light primer on some of the key concepts, described in simple terms:
Point of assignment: Describes the point at application runtime in which an SDK or service will be invoked to determine if a user should be assigned to a Test Group or pass a Feature gate.
Configuration: Generally, the data necessary for an SDK or service to function at the point of assignment in both client and server integrations. This can mean either a list of user assignments or a configuration spec that reflects the allocation rules and conditions configured for your experiments within the platform.
Initialization latency: Describes the time it takes for a tool to become “ready to use” and typically impacts or prolongs the application's readiness altogether.
Asynchronous vs. synchronous: I’ll use async to describe if a call requires an external network request to fetch some dependency. Sync will describe if some operation can happen purely using local compute and memory without having to stall your application to wait for the fetch of some external dependency.
Resilience/availability: This describes the likelihood that a service will be operational for the end user without causing disruption. Statsig aims to maintain
99.99%availability (four 9’s) to Enterprise customers.Network I/O: Describes the frequency and size of inbound and outbound network requests from a component within a customer's infrastructure. You may also hear network throughput and network chattiness. In this context, less network i/o is optimal.
Statsig server and client SDK design
The SDKs and their default capabilities are designed with performance in mind, and have various mechanisms for optimizing for performance and reliability at the point of assignment. Statsig SDKs will download and memorize configs (server SDKs) and assignments (client SDKs) in order to ensure getExperiment and checkGate evaluate locally and synchronously without adding latency.
Both SDKs are also designed to fail gracefully, supporting “default values” any time you call the assignment methods. This ensures that even if the SDK cannot initialize with a valid configuration (due to network conditions or an invalid key), the application will not crash, and the user will be served some sort of “default” experience.

In the next few sections, I’ll be covering the design principles of the SDKs, some of the common customer concerns, and cover solutions Statsig offers to alleviate those concerns and ensure implementations are performant and resilient.
Client SDK design
By default, our Client SDKs will download all user assignments from our servers and cache these in memory during initialization. As with most client-side tools, this is the piece that can result in render-blocking latency, which customers often seek to optimize to ensure their application is available to use as soon as possible for the end user.
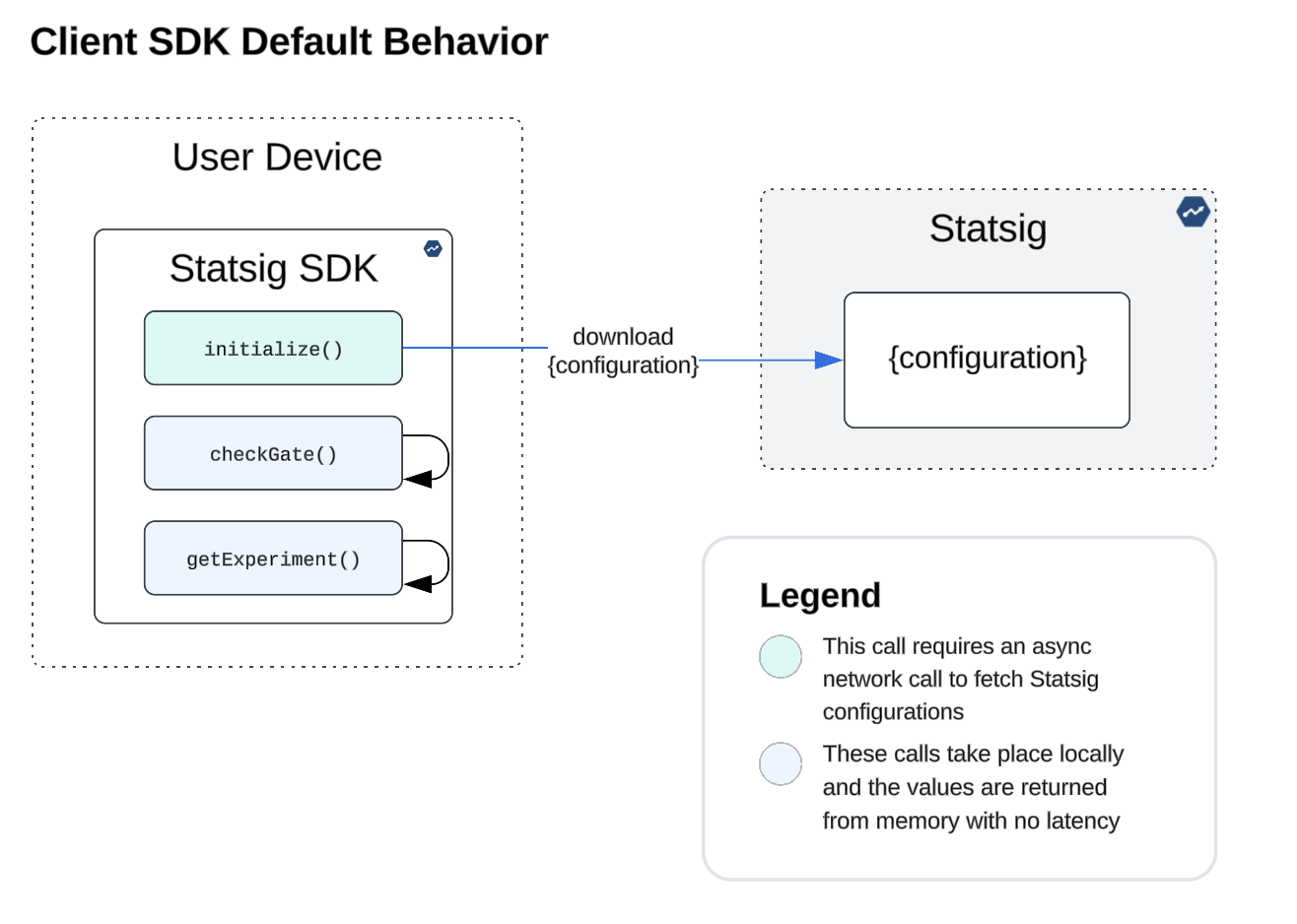
As a result of memoizing user assignment, each time the statsig SDK is called to check a gate or assign a user to a test, evaluation happens locally and carries no latency as depicted on the diagram.
Client SDK bootstrapping and local evaluation
Bootstrapping (available as an initialization option with client SDKs)
This solution lets customers provide the configuration directly to the client SDK for initialization, mitigating the associated latency and allowing a synchronous, render-blocking-free experience. This is optimal for testing on landing and marketing pages where the test experiences must be applied at the earliest point during page rendering to mitigate flickering.
A tradeoff here is that this approach adds complexity, requiring that you implement the Statsig server SDK in order to relay the configuration payload to the SDK running in your client application. This solution can be applied to both web (by simply serving the JSON config back to the page source) and mobile (by including the config in the payload downloaded during app launch).
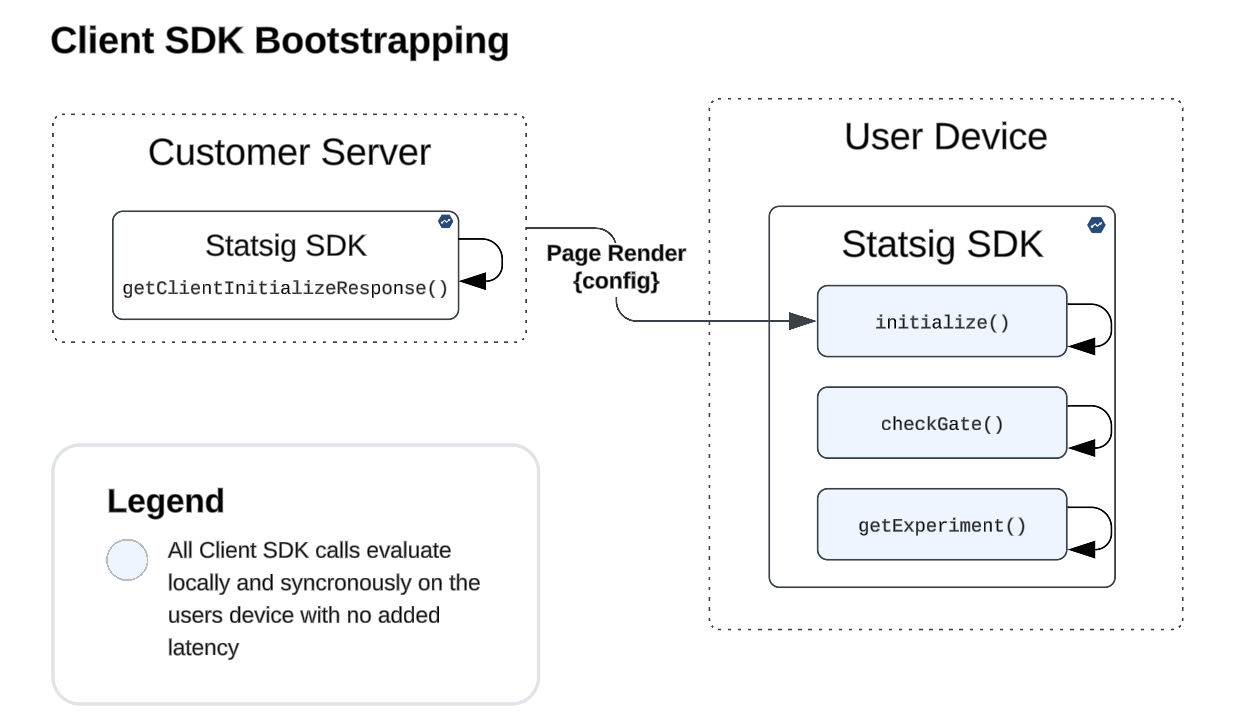
Local initialization (a new set of SDKs!)
Local Evaluation client SDKs (JavaScript, Android, iOS) are available for customers that require (a) frequently re-evaluating experiments with updated user context during long user sessions without triggering and awaiting an async network request and (b) initializing their client application synchronously without triggering async network requests.
These SDKs are similar to the bootstrapping approach but with the added benefit that you can mutate the user object in memory without having to download new assignments from Statsig over the network each time. The JS-SDK for local evaluation also offers a full-managed approach for bootstrapping whereby you can simply import your configuration by including a <script> tag prior to initialization (see under “synchronous evaluation”) rather than having to stand up your own server for providing “bootstrap values”.
Server SDK design
By default, our Server SDKs will download the project configurations from the servers and cache them in memory during initialization. The initial initialization latency realistically has no impact on end-user performance because the server is not yet handling requests.
💡 Tip: For servers sitting behind a load balancer, you can configure your GET /healthcheck endpoint to only return http 200 after Statsig has initialized. This way, your load balancer knows the server is ready to handle incoming user requests.
Each time the statsig SDK is called to check a gate or assign a user to a test, that evaluation happens locally with no latency or additional network requests. There is no performance impact on the end-user experience at any point because the checkGate or getExperiment calls take place in a route handler after the server has been running and initialization has since completed.
When implementing the Server SDK in many different services within a network, this can result in more network chattiness due to all SDK instances periodically downloading configurations over the network (though the frequency is configurable as an initialization option).
Additionally, customers may be concerned that relying on network calls back to Statsig (during initialization and polling) could have impacts on their application availability if they were to hang or fail altogether (though “default values” and the initTimeoutMs option mitigate this as well). Customers building for resilience typically care about both of these aspects and can implement the Data Adapter architecture described below.
Data adapter for server SDKs
⚡ Improves availability, reduces customer network i/o.
This capability allows the Server SDKs to initialize and retrieve your configurations from the data store located within your network (i.e., Redis), removing the dependency on Statsig servers altogether.
As documented in our data stores documentation, this is a programmatic interface that requires two simple methods: get for connecting and fetching from your data store and set for writing an updated config to your data store.
The architecture diagram below depicts several services within a customer VPC that are implementing Statsig, whereby only one of the instances is configured to handle fetching updates and writing them to the data store, and the others are all configured to read from a colocated Redis store.
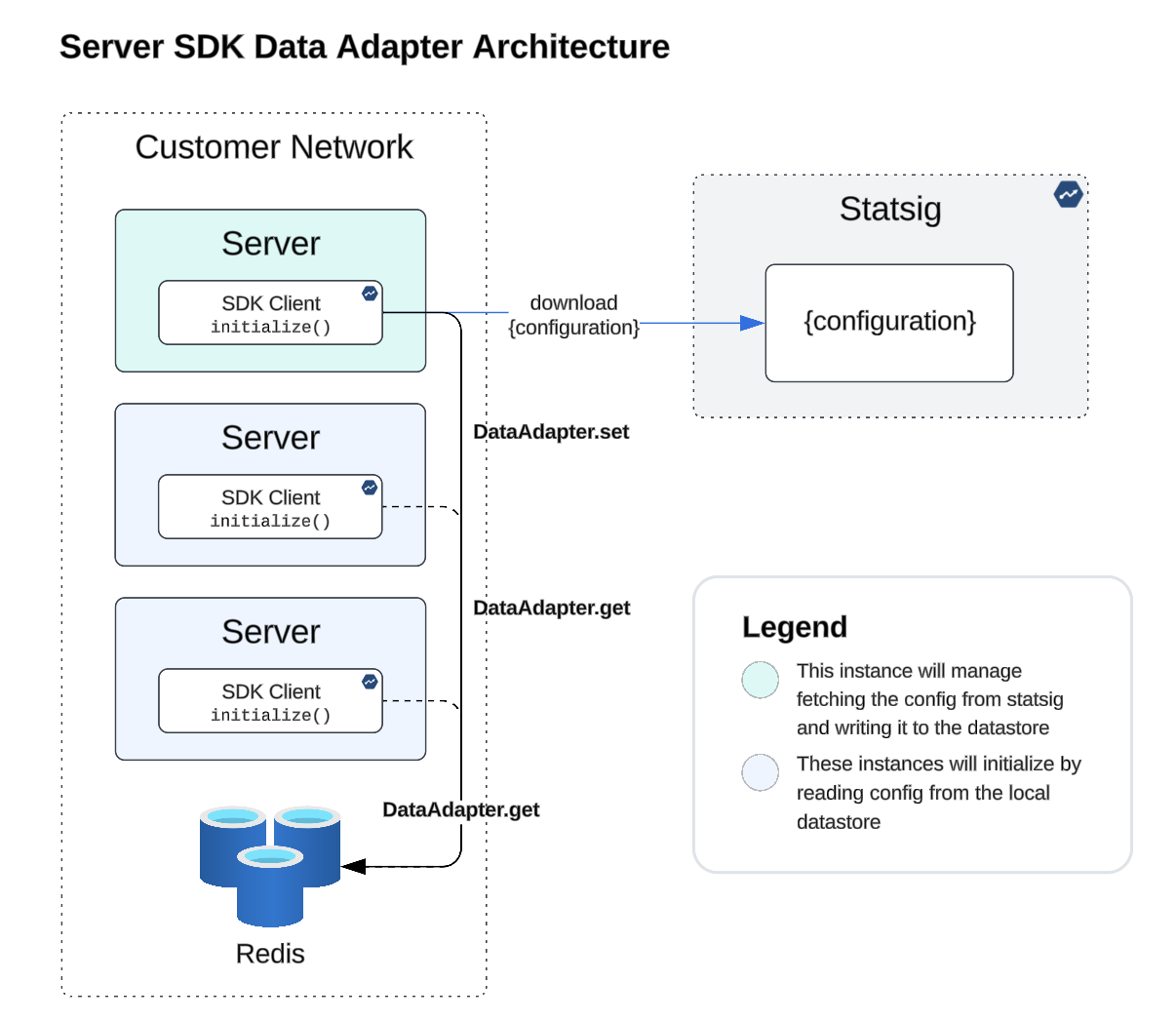
In conclusion, navigating the challenges of implementing a SaaS provider like Statsig within your application's critical path demands careful consideration of availability and system performance. By leveraging key design patterns and embracing strategies for resilience and efficiency, you can fortify your system against potential disruptions, ensuring a seamless and reliable user experience.
If you want more info, or to chat about this in regards to your own business, don’t hesitate to reach out.
Request a demo
