Products
Solutions
Resources


Statsig x Langchain: Unlocking experimentation in Langchain apps using Statsig

TLDR: Statsig has partnered with Langchain to build a new statsig-langchain package. With this package, developers can set up event logging and experiment assignment in their Langchain application in minutes, unlocking online experimentation across infra, product, and user metrics in one platform.
Langchain has changed the way that people build AI applications.
By providing developers with a single library that links many tools and pieces of context, Langchain has enabled the development of sophisticated AI applications. As the complexity of AI applications continues to increase, Langchain (and toolkits like it) are going to become more and more essential for AI developers.
At Statsig, we’ve watched Langchain’s progress with excitement (and built a few applications with Langchain ourselves). As we’ve built with Langchain, we’ve run experiments on our users, but it wasn’t as easy as it should be—a lot of code changes are required before an experiment is ready to launch.
We wanted to change that. So we worked with the Langchain team to develop a Statsig package that’s purpose-built for Langchain developers.
With this package, developers can set up event logging, define basic metrics, and start an experiment in under 10 minutes.
Our initial version of this package extends a few common Langchain primitives. These extensions automatically pass in variables from a Statsig layer to your Langchain application, meaning all parameters can be managed from the Statsig portal, instead of in code. All of these parameters can be configured from experiments and adjusted.
The extensions also automatically log all inputs and outputs to the Statsig console, giving developers full visibility across key model and user metrics (including cost and latency). All these logged events can be exported from the Statsig console and used as a “data store” for further model fine-tuning and training.
It’s still early and there’s a lot more to build, but it’s an exciting step towards simplifying online experimentation in AI apps.
Why online experimentation matters for AI apps
Imagine that you’re the CEO of a productivity tooling company. You’re ready to launch a set of new AI-powered features to enable in-app ideation, summarization, and more. You feel certain that this will drive value for customers and make a big splash!
During development, you had your team run a number of offline tests. They tested their model against a number of public benchmarks, and it passed with flying colors. Then they built a set of rules-based evaluation tools for your specific use case, which they used to test prompts.
At the same time, the team was using the feature and pushing it to its limits: asking it to perform a variety of tasks and throwing it curveballs. After a lot of work, it seems ready to roll! Your team is sure it’s going to be a success.
When launch day comes, the feature generates a lot of attention, but the percentage of users who actually tried the feature is low. Furthermore, it’s not very 'sticky:' Of the people that tried it, few people used it consistently. From a product perspective, the feature was a dud.
What went wrong?
This example is where the traditional AI/ML testing paradigm fails. The success of an AI feature is not solely dependent on the performance of the “AI” part of that feature; it’s dependent on the entire system working well together.
In this example, the problem with the feature could have nothing to do with the things you tested. Maybe the NUX for the feature is confusing. Maybe the way people trigger the AI feature is buried too deeply for users to find it. Maybe a bug causes the feature to not work in certain browsers. Maybe the AI is producing some very bad answers. Unless you have a system set up to capture this, it’s impossible to know!
This is where online experimentation comes in. If this feature had been rolled out as an experiment, the team would have:
A set of pre-defined metrics they could use to evaluate the success of the launch
A chance to learn from a partial rollout (instead of releasing all at once)
A data-based understanding of why the product was less effective than expected
Online experimentation will become increasingly crucial as more AI products exit testing and enter production. Or, as Harrison Chase (Langchain’s CEO) puts it:
"Evaluation of AI systems is hard. With a lot of these generative apps, there aren't really good metrics you can optimize for offline. This means that online experimentation becomes crucial for building and evaluating AI apps. As more and more LangChain applications make their way into production, I'm super excited to see this integration with Statsig enable online experimentation for more people.”
Harrison Chase, CEO, Langchain
How to set up an experiment using the langchain-statsig package
Note: Before proceeding, make sure you've set up a Statsig account and added your Statsig API key to your .env file. Read the documentation for more instructions.
Step 1: Install the statsig-langchain package with NPM
First, you’ll need to install the statsig-langchain npm package.
(Just type
npm install statsig-langchain)
Step 2: Use statsig-langchain primitives in place of Langchain primitives
You’ll then need to replace the usage of Langchain primitives with primitives from the statsig-langchain package. Here’s a sample of some code using the statsig-langchain primitives.
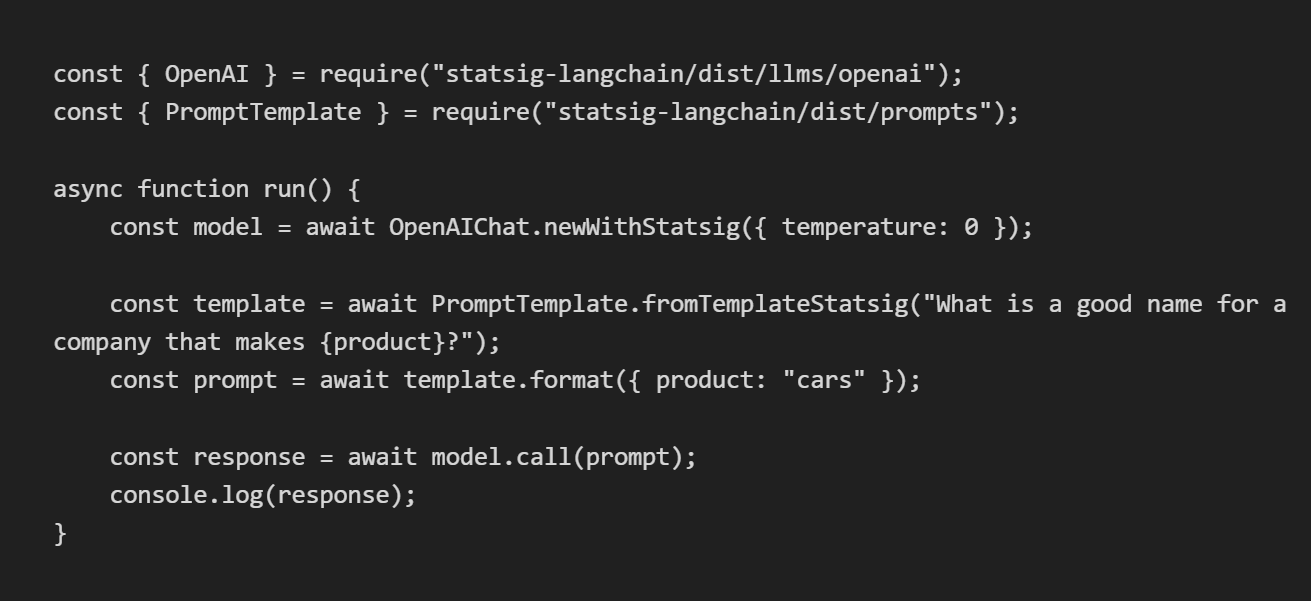
In the code above, we’re importing primitives from statsig-langchain and using the Statsig-specific constructors to create the primitives used to generate an AI response.
These new extensions perform four functions:
Automatically pass in values from a layer to your application, eliminating the need to make code changes to adjust the value of a parameter
Automatically assign users to an experiment, if you have an experiment running on that parameter
Automatically pass in values from an experiment to your application
Log all parameter inputs and outputs, giving you a record of the treatment you’ve assigned to each user, plus the impact on all user metrics
Step 3: Create a "Langchain layer" in the Statsig console
Next, you’ll go to the Statsig console, and create a layer named “langchain_layer.” This is the default name that is read into Statsig, though you can make a code change to read from other layers.
Then, you’ll add parameters to this layer. Please note, the names of each parameter must match the name of the Langchain parameter you’re trying to change.
Once you’ve set a value for each parameter, that value will serve as the default value for that parameter in your application. You can change the default value at any point within the layer, or change the value in an experiment.
If you don’t have a value in the layer, it will default to the value you’ve specified in code. This allows you to control the values of all parameters from the Statsig console in code.
Step 4: Set up an experiment and test any parameter
Once you’ve set up parameters in your layer, running an experiment is easy.
First, scroll up to the top of the layer view and click “Create experiment”. You’ll be prompted to set an experiment hypothesis and add additional tags.
Since you’re creating an experiment from a layer, you don’t have to worry about any code changes—you simply need to add in a few parameters from the layer, and specify the values you want to test.
That’s it! With those changes, you’re off and running, and ready to experiment.
Centralized control and measurement of parameters and metrics.
By completing these steps, you’re already well on your way to running experiments on your application. Without any other changes, you’ll see the impact of changing parameters on cost and latency, and record the exact parameters used in each user session (including user inputs).
To get the most out of Statsig, you’ll want to add a deeper view of user metrics. Any user metric you log to Statsig will automatically be included in every experiment, so no additional setup is needed.
To start, you may just want to log the most representative point of feedback for your AI application (e.g., a thumbs-up or thumbs-down button).
After you’ve completed this final piece of setup, you’ll be able to:
Track all model inputs, outputs, and user metrics in a single place, and use that data to fine-tune/train other models in the future
Change all parameters in one console, enabling changes without code modifications
Run experiments to measure the impact of all changes you make
Utilize holdouts to measure the cumulative impact of all the changes you make in your application
We think that’s a pretty amazing set of capabilities to unlock with ~10 minutes of setup… Hopefully you think so too!
Looking ahead
The current Langchain integration version is primarily aimed at developers using OpenAI to build chatbot-style applications in Javascript. As we move forward, we are eager to support developers using Statsig and Langchain by adding SDKs in other languages, enabling additional extensions, and more.
We believe that online experimentation will be a core part of the way that people build AI applications. We were thrilled by the opportunity to partner with the Langchain team to make experimentation even easier—and make Langchain an even better way to build AI applications.
Get started now!
